Internet project stability: how to // Reports from the Mail.Ru Technology Forum 2011: text of the report, video, presentation
The report “ Stability of the website: how to ” is another in a series of transcripts from the Mail.Ru 2011 Technology Forum . For details on how the report decryption system works, see the article “Reverse” of the Mail.Ru Technologies Forum: High-tech in event-management . There, as well as on the Forum website ( http://techforum.mail.ru ) - links to transcripts of other reports.
( Download video version for mobile devices - iOS / Android H.264 480 × 368, size 170 Mb, video bitrate 500 kbps, audio - 64 kbps)
( Download video version of higher resolution H.264 624 × 480, size 610 Mb, video bitrate 1500 kbps, audio - 128 kbps)
( Download presentation slides, 5.5Mb)
Probably, it is not a secret for you that every time when a large site has problems with work, interruptions, this causes a huge number of discussions. I will try to tell you how to ensure that your site does not fall, or fall even less often. What we do for this in Mail.Ru, what methods we use.
Stability is important
')
Stability for a website - is it important in principle? There are many opinions on this topic - someone thinks that this is important, someone thinks that, among others, this is not the most important factor. We consider this very important, and for this we have three main reasons.

As you know, most of the services on the Internet are free. And as soon as your site does not work, it slows down, experiences some problems, your user goes to a competitor.
The second reason is that the threshold for switching between services on the Internet is quite low. You do not need to go anywhere, there is no high switching cost, as is the case with cellular operators, and you can always switch to another site when the service you are used to using does not work. And, moreover, there is a huge number of auxiliary features that will help such an offended user to move from one site to another, therefore stability is important.
The third reason is not “about the Internet”. We should all understand that a person is arranged in such a way that negative emotions are always stronger than positive ones, and one accident on your site, as a rule, covers a huge amount of stable operation time, high-quality service, etc.
For these three reasons, we believe that the site should work stably, but on average, the Internet does not have a very high level of stability. According to our internal statistics, the average Russian Internet site has Uptime, i.e. “Work time” - 98.6%. The figure is not terrible, but if you take a closer look, it’s five days a year when the average Internet site is down. This is quite a lot of time, and it tells us that the problem exists, and the problem is quite serious. Of course, large Internet sites work a little better. A large Internet site accounts for about four hours of “non-work” per year. But, nevertheless, these are all large numbers, especially if we recall about five days.

Causes of accidents
Based on the statistics of Mail.ru, we have classified the reasons why accidents occur in our country and on other sites on the Russian Internet. If we talk about quantitative distribution, I mean the number of accidents due to which this or that site’s functionality does not work, the site is down, etc., half of the sites crash on the Internet are due to the wrong software release, software release with bugs, crooked configs. Accordingly, in half of the cases, again I want to draw attention - quantitatively, the developers, the system administrators who failed, failed badly, etc., are to blame. Another 25% of cases occur in software accidents, to which I also include the load on the site, 16% of cases are network crashes, 8% are server and computer crashes on which the sites operate.

If you look at the qualitative distribution, it will be completely different. As we can see, the worst accidents are network crashes and data center crashes. It is very hard to protect yourself from them. They, as a rule, completely shut down the entire resource or even large hosting, many resources do not work at the same time. They occupy 30% each. The following are crashes when new software is released. This is followed by software crashes and, at the very end, equipment crashes, they make up a small percentage.
Monitoring
In order to talk about how to make your site stable, we first need to discuss how we know something is wrong with our site. I am sure that all IT professionals who are in this audience will not argue with me about the need for monitoring. Anyone going to be? I am also sure that there are people in this audience who do not have monitoring. Let me briefly list 10 reasons to have monitoring. I know that you agree that you need monitoring, but let's still go through this list.

The first reason sounds very simple: you are an excellent programmer, an even better system administrator, but your site will still fall. Whatever you do, it will happen - tomorrow, after a year - it does not matter. It will happen in any case, it is impossible to fight this, it will definitely be, so always remember this. We need monitoring not only to find out that our site has fallen. We need it in order to take some measures as soon as possible so that the site can work again. When the site does not work a small amount of time - this is one problem for the user, when the site does not work for 5 days - this is a problem of a different order.
You should not learn about the problems of your site from your users, because the time it takes to get your user to write to you, your tech support told you about the problem - it is too long. During this time, a large number of users goes to your competitors. The market is designed in such a way that most service providers, both Internet service providers and data center service providers, will not be liable in proportion to the value of your business, therefore, responsibility for your Uptime and for the time when your site is down , lies entirely on you, not on your service provider.
As you know, when the site does not work, users begin to discuss: “it does not work temporarily” or “completely closed” or “something happened”. This discussion does great damage to your reputation. Moreover, we noticed an interesting effect that even those users who were not directly affected by the accident, i.e. they did not go to the site at the time when he was not working, participating in these discussions, they become as if they were involved. They believe that something happened to them too and this is another problem for which we need to have monitoring, and we need to know when our site is down.

All our sites are updated, we are constantly refining new features, we are launching new “features”, we are doing new features on our site, and this leads to the fact that we have a complex, large, long development process. Monitoring is the thing that allows us to know that there are systemic problems in it. Only through monitoring you can find out which team of your developers or a specific developer constantly creates problems in the stability of the site. Only through monitoring can we know which module of our software we need to pay extra attention to.
The next problem is that the Internet is large and you can work perfectly with your website, it can open perfectly, all functions can work for you, but you will be the only person for whom it works. Accordingly, monitoring should be done in such a way that it allows you to see problems not only from your technical infrastructure, but also outside. Now if we talk about Mail.Ru - it is monitored from about 100 points around the globe, so we learn about the problems not only with us, but also about problems with providers, about problems with providers of our providers. Honestly, the end user doesn’t care where Mail.Ru doesn’t work, the phrase "provider provider" doesn’t say anything to it. He understands that Mail.Ru does not work. Therefore, we observe our network infrastructure, we observe the network infrastructure of those operators who provide services to us through our monitoring.
Again, good monitoring will save you time, because not only does it warn you that you have problems, it will also say that it is not working at the moment, and it will save you time for understanding and the subsequent solution.
You should be aware of the problem at any time. Only in Russia there are nine time zones, and all over the world you can have users in those places where, say, the day is already, at the time when we have night.
Well, the last argument. As a rule, the cost of developing a site is quite high. The cost of creating a monitoring compared to the cost of developing the site is almost none. By creation, I mean customization, because there are a lot of solutions in open access that can be downloaded and delivered for free.
Here are 10 reasons why all people in this room, who have their own websites, and who for some reason do not monitor them, should return from the Technology Forum and set up monitoring for themselves.

What we are monitoring in Mail.Ru
In fact, Mail.Ru has about 140 different types of monitoring, I will not list them all, in total we monitor about 150,000 objects on our servers. We have a monitoring service. For example, this may be a service response over HTTP. We have functional monitoring of services, we always check whether letters reach us, whether they are downloaded via POP3, whether the user can add another user as a friend, etc. We will definitely monitor network availability. We check whether we are visible around the world. We monitor the occupancy of our data warehouses, because most of the software is written in such a way that if the disks are full, then this data will simply deteriorate, and we will be forced to recover from the backup. We also monitor the speed of the site, because there are thresholds at which it doesn’t matter that your site opens, relatively speaking, in half an hour. For the user, this will mean that your site simply does not work. We monitor all statistical emissions. We collect a huge amount of statistics on Mail.Ru, for example, we know how many letters we send per day, we know how many messages we send per day, how many friendships we have in social networks. We try to observe these quantitative metrics, and if any of them starts to grow or change rapidly, or some kind of “outlier” appears, we have it highlighted in monitoring, it is possible then to analyze why it happened, that this can be done, etc. And these are just a few of the types of monitoring available.
But one more important one remains. If you do not have monitoring, it is very bad. But when you have monitoring, but it doesn’t work - it’s terrible, because you get the false impression that your website is actually working now. Therefore, the most important and very first monitoring in Mail.Ru is monitoring that monitoring is working.

Backup and balancing
And now let's talk about what we still have to do so that our site does not fall, as we at Mail.Ru approach these issues. We begin, naturally, with redundancy and balancing.
We have a universal table that we apply to our services. It is quite common, but at least by trying it on one or another of our services, we can understand how secure it is, how much it corresponds to what we want to receive.
We believe that for any data processing servers that are not repositories, N + 1 redundancy is sufficient for us. N + 1 in this example does not mean that we have one spare server for 100 servers, this means that we determine N. For example, in the case of frontend, we have one spare server for every 10 web servers. The important thing is that in this case we always have some number of servers that we can, if anything, put into battle. For data warehouses, we always have two online copies of our storage, because hard drives are such a thing that they cannot be trusted. And we can switch from one storage to another at any time. Plus, that is often forgotten, we always have an offline copy of our data. The problem is that there are not only hardware failures, but also software, in which case I simply don’t need two arrays with broken data, I just need an offline copy to which we can roll back if we need it.
The stock taken by the network infrastructure in Mail.Ru is 35%. This is enough to survive the "peaks" that are associated with some events. This is enough to survive the influx of attendance that we experience when our competitors are not working. In general, 35% of the network infrastructure of the average site is enough to survive all those disasters that can happen to it.
Separately, I would like to mention that every time I talk about reservations, every time I talk about reserves, I don’t mean the server that lies somewhere in your warehouse, office, or somewhere else. Because at the moment when the accident happens, you will need some amount of time to bring the reserve into battle. Therefore, all the reserves that you have should be automatically brought into battle. And in the ideal case, as it is done with us, it should always work. Those. The ideal reserve is the redundancy of your working servers. Backup servers should also process some part of the load in the usual time, so that a copy of the software for them is always relevant, their configuration files are always relevant, etc.
So, just a couple of words about how we approach the creation of fault-tolerant balancing systems. I will describe this using the HTTP service as an example. In fact, you can use this concept in almost any service. In order to create such a balancer, we need the simplest router with support for the RIP protocol, we need a means of communication with this router, I propose an open source solution for Quagga , but you can use something else.
We need the actual balancer and IPVS traffic encapsulator, it is very well known, a huge number of system administrators know how to work with them. And the last thing we need is a utility to check the liveliness of servers keepalived . It is good because you can customize it completely to your needs. So, how does this work on the example of a single data center? In the future, I will also show how this works in the case of several data centers.
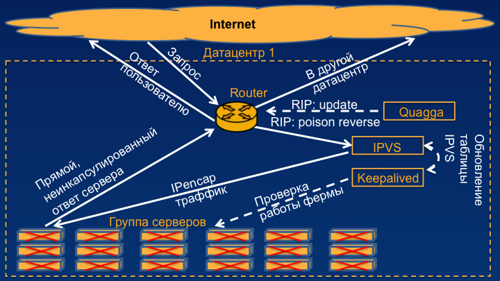
Here we have a group of our servers. Suppose - this frontend-s. They respond via HTTP to user requests. We have the same Keepalived that I described, which polls them and, if they work, it updates the table of these real servers in IPVS. If the number of real working servers in IPVS is higher than the threshold value that we have determined sufficient for our service, IPVS raises the virtual IP address of your service on the balancer. In the case of Mail.Ru, you can see, these are four IP addresses, four different groups of balancers. The same demon who communicates with the router begins to inform him that the route to Mail.Ru runs through this same balancer. Further, when a user request comes to us, the router, based on its routing table, calls the balancer, the balancer encapsulates this traffic in IP-in-IP (this adds us only 20 bytes to each packet) and sends it to the real server. And the real server sends it directly, without encapsulation to the router, the router directly to the user.
This scheme allows you to process about 600,000 packets per second, which is not bad even for the hardware of popular vendors.

The advantage of this solution, as compared with the hardware purchased from the vendor, is that it is completely under your control, you fully understand what is happening there at the moment, you can add, finish, redo everything as you need. If several servers do not work for us, keepalived will immediately notice this, and he will turn off these servers in the table of real servers of our balancer. If the entire farm has broken down, i.e. the number of live servers that currently work for us turned out to be less than the threshold value that we expose, it is noticed by the same keepalived, it reports this to IPVS, and it removes the virtual IP address from our balancer. As a result, the demon that is responsible for communicating with the router simply kills the route to this balancer, and the user package simply goes to another data center, where we have a working server farm and a working balancer.
On the example of several data centers, this sounds a bit more complicated, but the meaning is about the same. We receive custom requests. If the RIP-metrics are the same, they are evenly distributed between our balancers, then go to real servers, then go to the router and back to the user. In case we have some kind of accident, it is noticed by our monitoring, our keepalived, we kill the route on this router, and all user requests go to the router in the neighboring data center, and accordingly, to the balancer in the neighboring data center.

As you know, any advertisement describes only the benefits, and my presentation is no exception. There are four things we need to do in order for it to actually work. We need to fix the RIP update timers in Quagga, they need to be reduced to one second, just so that the user does not wait for a long time until our routing table is updated.
Second, we need to once again fix Quagga so that your RIP-metric, which your system administrator can set, does not go into the poison reverse package. Administratively set the metric you may want in case you have several balancers for your system and you need to do some work on one of them. As I said, IPVS encapsulates packets by adding 20 bytes to each IP header packet. We will have to patch Keepalived in such a way that it sends not only the most similar to user requests, we need them to be 1500 bytes in size, so that if we have a bag somewhere on the network, it does not fit through the MTU - we it was immediately discovered.
And finally, in order to achieve the performance that I promised you, namely, 600,000 packets per second, we need to turn off irqbalance on our server, and manually scatter processes across the cores. Actually, you have to scatter the keepalived process and the interrupt queue of your network card. It will be great if your network card supports MSI-X and you have more than one queue. This is how we balance in Mail.Ru.

And now let's talk a little about other things. In order to make the project stable, reliable and all the time working. we need to make it modular. This will allow us to break not all at once, but in parts. You perfectly understand that whatever your site is, your users work only with some functions on it. Some parts of your site are more popular, some less. Accordingly, if your software product is modulated, then you will never break down completely. You will break down in some way, and this will affect fewer of your favorite users. The second thing is to cache negative responses. If for some reason any part of your system stops responding to you, do not continue to send there all the requests from your users. It is necessary to design the system in such a way that after the accident has happened, every tenth, twentieth, thousandth package gets there, depending on your load. Accordingly, as soon as your service began to respond correctly, you unblock it automatically, and the work is restored.
A very good idea that few realize - work with your modules asynchronously. This can be done both with the help of clientside - with the help of AJAX, and on the server side, this will allow you, if you have problems with the load, while you wait for the decelerating module, to collect all other necessary data. As soon as more than one server appears on your system, it is a good idea to divide the load by type. Namely, to have a specified server for your database, for your frontend-a, for your mail service, etc. This allows you to break again not entirely.

Release Management and Testing
Let's talk a little about release management and testing. I understand that we do not have time to cover the entire release management, especially since you can arrange a whole conference on this topic. But there is, nevertheless, a number of topics that for Mail.Ru seem to be the most important and most important.
First, half of the stability problems of the project are associated with the release of new code. And this tells us that there should be release management in the project. By release management, I mean that you, your manager, the team that develops the project should understand “what we are launching today,” “what is included in this release,” “who is responsible for it,” “what load will this release add to production? ” The release process should be as automated as possible, because ... we even have one simple saying in Mail.Ru: “the more automated the process, the fewer surprises in production”. Starting from the moment when in order to run something on the production servers, you start copying something, correcting some configuration files manually - wait, it will take quite a bit of time until you make a mistake. If you have an automatic release process, first of all, it guarantees that what you are rolling out for production is exactly what you have just tested. Secondly, it minimizes the number of errors in the configuration files, under-produced before the production of the library, etc. That is, the cost of automation of the release is small, and the benefits of this, I think, is very large.
Of course, all people are wrong, and we can not always foresee the load we will bring to our service by launching this or that new functionality. We at Mail.Ru apply split testing for this. Split testing is when you launch a new Finch for some users only. First of all, this is wildly liked by the users themselves, because a group of the elect appears, which sees all the newest, most interesting, most interesting bugs. Secondly, it allows us to look at this group, and if we didn’t make a mistake with the load, didn’t we do something that, when running on the entire system, will lead to an accident.
And the last thing I want to say a little bit about is to release everything every time. Suppose there are several developers in your team, and some of them did their task quickly, some of them did the task for a long time. So, even if your product, which was made by one developer, is not ready for release - release what is. Even if nobody calls these modules, even if nobody needs them, release them on the day of release anyway. This allows you to avoid the black day of the system administrator, when a huge piece of code is released, and if something has broken somewhere, it is impossible to figure it out. Therefore, releasing your product a little bit each time, making this process permanent, you achieve that you will never have one big megarelosis, after which it will take another five days to roll back everything.

Of course, it is important not only to release everything, it is also important to predict the load. You must have your load schedules. You need to know how fast you work. Your development team should have a person whose responsibility it is to look at these graphs, and to warn every time - “guys, it seems we are approaching critical values”. We must have thresholds for all response times of our services, because we need to know when to shout about the problem.
There are specific projects. For example, such as the service of virtual postcards. On holidays, for example, on New Year's Day, on Valentine's Day, the load on such services increases by 20 times. Accordingly, if you remember this, then you will be ready for this increase in load.
Very often, the team is formed in such a way that programmers develop new functionality, and administrators are responsible for the stability of your site - this is a bad organization, it should be a single team, people should understand what they are launching and how it will be reflected in production. There should not be situations where some people program and know what they are going to launch, while other people are responsible for the stability of the site, and for them every launch is a surprise. We at Mail.Ru try to have an estimated load metric that our release will cause, we try to predict that this functionality will require so many additional servers from us. I also recommend that you do it. Somewhere, probably, with
times and you learn to guess the load. This greatly helps you to predict your load, and in a timely manner to increase the capacity that you need.

Accidents
Now let's talk about accident planning. I do not mean subversive activities, I mean, what will we do when we have finally broken everything. And as we remember, it is inevitable. So, spend this time before. how you had an accident, and you will save many hours of the time that you will spend to restore the stability of your site. Any member of the team should know - if something is broken, then what is its function, what does it do, how is the reserve injected, how are backups rolled out. Rollout backup should be fully automated. What do I mean by automation? Unfortunately, when our equipment breaks down, it does not always warn us in advance. Sometimes it happens at night, sometimes some people are on vacation. Accordingly, so that you do not have a situation where your system administrator is somewhere far away, and your data is already broken, make sure that your backup rolls out automatically, at your request, of course. Provide stubs and "light versions" of your site. , , . , - , «internal server error 500».
, , , , : ( ) « , , , . .»

, , , , - , . , , . , , « ». - , , . , , , — . , . , , .

— . , , , -, - , . , , , , — , , , ? - , - , - , , , . , , , . . , , , .
, , , « ». 10% . - - , - - , - . , , — , .
, , , , , , , , . — , -, .
, , , BGP-, . , Mail.Ru . , , , , , . , . , , , , .

Questions
— , , . , , . , ?
- 15, .
. , . : ?
, . , , . , , .. , .
, , . : , — - ?
— . , , . , , . - — , , .
. ? - , - ?
. - . , . . , , , , , — « , , », . — , .
, « ». , , , , - . -. , -?
- . , , «».
. . — , — . , — - . ? ..
I understood. , . , , , — «, - , ?». . , , - , , .
— — «, »? ?
. — « — ». , . , , — . : - , , — «, , », , . . « , », « », « , ?» ..
, . , -. Those. . ? - ? ?
, . , , , , , . , - — . , — - . , , , . — , . , , , , .
, — ? ...
, . Various. , , , , .
. Java , ? ? . : ,500- . , -. , , — , « »?
. ? , , , , — , - - . , — . Java- — , , , , . , — . , mail.ru, Java- , , , .
. . opensource . , opensource , .
. 13 - — . , , , . mail.ru , , . .
, . . , - , - , ?
. DoS- - , . , , . , , , 10 . , , , , DoS. , - — , , , , , , - , .
. — - DoS-?
Not.
, ?
— .
: Mail.Ru Group ?
, . - -. - .
. , , , , ? , : ,1- , , .
, Mail.Ru. , , 24 . Mail.Ru . .. , - - , . , , - , , 12 - , - . , .. c .
Mail.Ru 2011 , 16 . Details about the technology of creating texts of reports based on video recordings can be found here: “Wrong side” of the Mail.Ru Technologies Forum: High-tech in event-management . ( ) – techforum.mail.ru . Text versions of the reports will be published here and on the Forum website every week or less often in a similar format. Please report in the "lichku" about typos in the text.
Source: https://habr.com/ru/post/134109/
All Articles