Choosing a distributed file system for Linux. A few words about Ceph and the rest
There are several dozen file systems, all of which provide user interfaces for storing data. Each system is good in its own way. However, in our age of high loads and petabytes of data for processing, it turned out to be quite difficult to find what you need, you just have to think about distributed data, distributed loads, multiple mount rw and other cluster charms.
Task: organize distributed file storage
- without self-assembled cores, modules, patches,
- with the possibility of multiple mount mode rw,
- POSIX compatibility,
- fault tolerance,
- compatibility with already used technologies,
- reasonable overhead of I / O operations compared to local file systems,
- easy configuration, maintenance and administration.
We use Proxmox and OpenVZ container virtualization in our work. It is convenient, it flies, this solution has more advantages than similar products. At least for our projects and in our realities.
Storage itself is mounted everywhere on FC.
')
We had a successful experience using this file system, we decided to try it first. Proxmox has recently switched to the Redchat core, with support for ocfs2 turned off. There is a module in the kernel, but on the openvz and proxmox forums, it is not recommended to use it. We tried and rebuilt the kernel. Module version 1.5.0, a cluster of 4 iron machines based on debian squeeze, proxmox 2.0beta3, kernel 2.6.32-6-pve. For tests used stress. The problems over the years remained the same. Everything started, setting up this bundle takes half an hour from the force. However, under load, the cluster may spontaneously collapse, which leads to a total kernel panic on all servers at once. During the day of the test machine rebooted a total of five times. It is treated, but to bring such a system to working condition is quite difficult. I also had to rebuild the kernel and turn on ocfs2. Minus.
Although the core is Redhat, the module is turned on by default, we could not start here either. It's all about proxmox, which from the second version came up with its cluster with chess and poetess to store their configs. There cman, corosync and other packages from gfs2-tools, only all rebuilt specifically for pve. The snap-in for gfs2, therefore, isn’t just put out of packages, as it offers to demolish the entire proxmox first, which we could not do. For three hours, the dependencies managed to be defeated, but the kernel panic ended again. An attempt to adapt proxmox packages for solving our problems was not successful, after two hours it was decided to abandon this idea.
We stopped while on it.
POSIX compatible, high speed, excellent scalability, several bold and interesting approaches to implementation.
The file system consists of the following components:

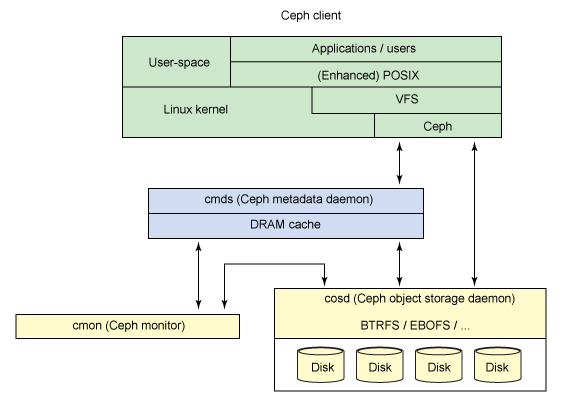
1. Customers. Data users.
2. Server metadata. Cache and synchronize distributed metadata. With the help of metadata, the client at any time knows where the data he needs is located. Also, metadata servers perform the distribution of new data.
3. Cluster storage of objects. Here both data and metadata are stored as objects.
4. Cluster monitors. Monitor the health of the entire system as a whole.
Actual file I / O occurs between the client and the object storage cluster. Thus, the high-level POSIX functions (opening, closing, and renaming) are managed using metadata servers, and the usual POSIX functions (read and write) are managed directly through the object storage cluster.
Any components may be several, depending on the tasks of the administrator.
The file system can be connected either directly using the kernel module or via FUSE. From the user's point of view, the Ceph file system is transparent. They simply have access to a huge data storage system and are not aware of the metadata servers used for this, the monitors, and the individual devices that make up the massive storage pool. Users simply see a mount point at which standard file I / O operations can be performed. From the point of view of the administrator, it is possible to expand the cluster transparently by adding as many components as necessary, monitors, storages, and metadata servers.
The developers proudly call the Ceph ecosystem.
We did not consider GPFS, Luster and other file systems, as well as add-ins, this time, they are either very difficult to set up, or they do not develop, or are not suitable for the task.
The configuration is standard, everything is taken from the Ceph wiki. In general, the file system has left a pleasant impression. An array of 2TB is assembled, in half from SAS and SATA disks (block device export by FC), partitions to ext3.
Ceph storage is mounted inside 12 virtual machines at 4 hardware nodes, read-write from all mount points is performed. The fourth day of stress tests are normal, I / O is issued on average 75 mb / s. on record by peak.
We have not yet considered the remaining functions of Ceph (and there are still quite a lot of them), there are also problems with FUSE. But although the developers warn that the system is experimental, that it should not be used in production, we believe that if you really want, you can -_-
I ask all those interested, as well as all sympathizers, in a personal. The topic is very interesting, we are looking for like-minded people to discuss the problems that have arisen and find ways to solve them.
References:
- http://en.wikipedia.org/wiki/Ceph
- project site
- a brief overview used when writing this article
Task: organize distributed file storage
- without self-assembled cores, modules, patches,
- with the possibility of multiple mount mode rw,
- POSIX compatibility,
- fault tolerance,
- compatibility with already used technologies,
- reasonable overhead of I / O operations compared to local file systems,
- easy configuration, maintenance and administration.
We use Proxmox and OpenVZ container virtualization in our work. It is convenient, it flies, this solution has more advantages than similar products. At least for our projects and in our realities.
Storage itself is mounted everywhere on FC.
')
OCFS2
We had a successful experience using this file system, we decided to try it first. Proxmox has recently switched to the Redchat core, with support for ocfs2 turned off. There is a module in the kernel, but on the openvz and proxmox forums, it is not recommended to use it. We tried and rebuilt the kernel. Module version 1.5.0, a cluster of 4 iron machines based on debian squeeze, proxmox 2.0beta3, kernel 2.6.32-6-pve. For tests used stress. The problems over the years remained the same. Everything started, setting up this bundle takes half an hour from the force. However, under load, the cluster may spontaneously collapse, which leads to a total kernel panic on all servers at once. During the day of the test machine rebooted a total of five times. It is treated, but to bring such a system to working condition is quite difficult. I also had to rebuild the kernel and turn on ocfs2. Minus.
Gfs2
Although the core is Redhat, the module is turned on by default, we could not start here either. It's all about proxmox, which from the second version came up with its cluster with chess and poetess to store their configs. There cman, corosync and other packages from gfs2-tools, only all rebuilt specifically for pve. The snap-in for gfs2, therefore, isn’t just put out of packages, as it offers to demolish the entire proxmox first, which we could not do. For three hours, the dependencies managed to be defeated, but the kernel panic ended again. An attempt to adapt proxmox packages for solving our problems was not successful, after two hours it was decided to abandon this idea.
CEPH
We stopped while on it.
POSIX compatible, high speed, excellent scalability, several bold and interesting approaches to implementation.
The file system consists of the following components:
1. Customers. Data users.
2. Server metadata. Cache and synchronize distributed metadata. With the help of metadata, the client at any time knows where the data he needs is located. Also, metadata servers perform the distribution of new data.
3. Cluster storage of objects. Here both data and metadata are stored as objects.
4. Cluster monitors. Monitor the health of the entire system as a whole.
Actual file I / O occurs between the client and the object storage cluster. Thus, the high-level POSIX functions (opening, closing, and renaming) are managed using metadata servers, and the usual POSIX functions (read and write) are managed directly through the object storage cluster.
Any components may be several, depending on the tasks of the administrator.
The file system can be connected either directly using the kernel module or via FUSE. From the user's point of view, the Ceph file system is transparent. They simply have access to a huge data storage system and are not aware of the metadata servers used for this, the monitors, and the individual devices that make up the massive storage pool. Users simply see a mount point at which standard file I / O operations can be performed. From the point of view of the administrator, it is possible to expand the cluster transparently by adding as many components as necessary, monitors, storages, and metadata servers.
The developers proudly call the Ceph ecosystem.
We did not consider GPFS, Luster and other file systems, as well as add-ins, this time, they are either very difficult to set up, or they do not develop, or are not suitable for the task.
Configuration and Testing
The configuration is standard, everything is taken from the Ceph wiki. In general, the file system has left a pleasant impression. An array of 2TB is assembled, in half from SAS and SATA disks (block device export by FC), partitions to ext3.
Ceph storage is mounted inside 12 virtual machines at 4 hardware nodes, read-write from all mount points is performed. The fourth day of stress tests are normal, I / O is issued on average 75 mb / s. on record by peak.
We have not yet considered the remaining functions of Ceph (and there are still quite a lot of them), there are also problems with FUSE. But although the developers warn that the system is experimental, that it should not be used in production, we believe that if you really want, you can -_-
I ask all those interested, as well as all sympathizers, in a personal. The topic is very interesting, we are looking for like-minded people to discuss the problems that have arisen and find ways to solve them.
References:
- http://en.wikipedia.org/wiki/Ceph
- project site
- a brief overview used when writing this article
Source: https://habr.com/ru/post/133987/
All Articles