How I did a fault tolerant web service
Foreword
In this article I wanted to talk about my experience in building a fault-tolerant Web service. I developed an internal enterprise management system using PHP + MySQL (corporate portal), and since almost the entire life of an enterprise depends on the efficiency of this system, resiliency issues become very important. At the same time, the enterprise is small, accordingly, it cannot afford expensive iron and technology, and a simple system in a few hours is also not lethal to it. Therefore, I tried to solve this problem with minimal monetary investments and doing it on my own and with little knowledge in the field of administration.
Just want to say that for specialists working with Heartbeat, DRBD, OCFS2, MySQL Cluster this article is clearly not interesting. But if you are new to this, you only have money for a couple of system managers, and you want to build a reliable system, then ... read what I did.
Task
Understanding that I would not be able to work on a working server until I was able to build a classical fault-tolerant system in which when one of the servers fails, I set the following task for myself. Build a system of two servers, in which one works as the Main, and the second, as a Slave, when the Main server fails, the enterprise system administrator manually switches the network cables to the slave and the work continues. Then you can slowly restore the performance of the Chief and return the system to the normal mode of operation without much downtime. This completely satisfied the requirements of the customer.
')
General solution scheme
So, to create my own system, I purchased 2 inexpensive system units (the total cost was a little more than 30 thousand rubles) of the following configuration:
- Mat. motherboard Socket775 ASUS "P5Q-VM DO"
- Intel Core 2 Duo E8400 processor
- RAM DIMM DDR2 (6400) 2048Mb x 2
- Hard Drive 320Gb WD SATA-II 7200rpm 16Mb, Raid Edition
- I put 1 additional network card into the main server and 2 with the slave. Intel Corporation 82541PI Gigabit Ethernet Controller network cards.
The result is a main server with 2 network interfaces and a slave server with 3 network interfaces.
As a platform on which the corporate portal runs, I use LAMP based on Ubuntu Linux 8.04.4, which runs as a VMWare virtual machine. In fact, I am not a great specialist in setting up LAMP, so I trust professionals and take the ready-made 1C-Bitrix virtual machine as a basis ( http://www.1c-bitrix.ru/products/vmbitrix/ ).
In order to run a virtual machine on servers, I stopped at the option of installing a free VMware vSphere HypervisorTM hypervisor (ESXi) v. 4.1 on bare metal (bare metal), which is installed first on both servers. This hypervisor is a mini-operating system, the functions of which boil down to what to manage virtual machines. The installation went smoothly, however, as I found out later, the hardware turned out to be not quite compatible with ESXi. Although I checked all the components on the white lists I found on the Internet ( http://www.vm-help.com/esx40i/esx40_whitebox_HCL.php and http://ultimatewhitebox.com ). The incompatibility was expressed in the fact that ESXi did not display the full range of diagnostic information about the state of server hardware. It seems not to matter, but still not very good.
Then I copied identical configured virtual machines with LAMP and my corporate portal onto both servers. Then configured network interfaces in ESXi. On the Main server (2 LAN interfaces in total): 1 network interface configured for access to ESXi and both tied to a virtual machine. And on the Slave (3 LAN interfaces in total): 1 interface - for access to ESXi, and 2 others “tied” to the virtual machine.
Cable directly connected both servers through network interfaces tied to virtual machines. In virtual machines, I assigned IP addresses to these network interfaces (10.10.10.2 - for the Main and 10.10.10.3 - for the Slave) from a subnet different from the customer's LAN network (172.20.15.0-255). This direct connection between servers is intended solely for “communicating” the virtual machines of the two servers with each other, namely, to replicate MySQL data and synchronize folders with scripts.
The main server through its second interface connected to the local network of the enterprise. The slave server through the interface for working with ESXi also connected to the local network, and the third of its interface, designed to work with the virtual machine, was left unconnected - in normal mode it is not used.
On the Master and Slave servers in virtual machines, I assigned the same IP to the second interface that the virtual machine "sees". In normal mode, the network cable is connected to this interface on the Main server, and when it fails, you need to switch this cable to the corresponding interface of the Slave server. Because The IP is the same there, no other settings will be required, and the work can be continued.
Thus, the following schemes of the system operation in the normal mode and in case of the failure of the Main server have turned out:
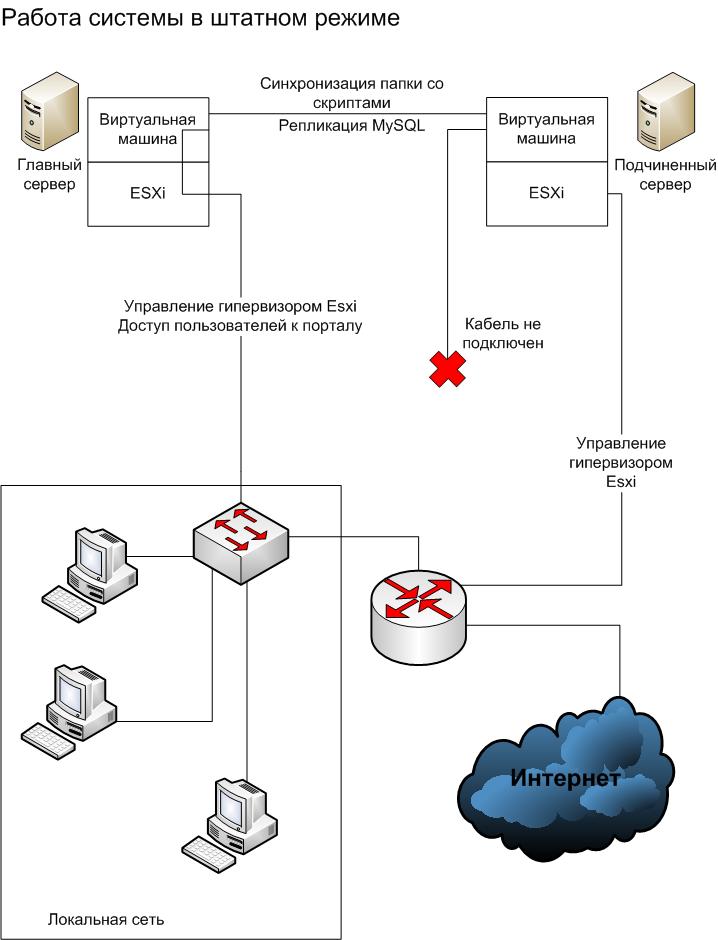

Now a little about the nuances.
I set up standard replication in MySQL between the Master (made him a master) and the Slave (made him a slave) servers over a cable connecting the servers to each other. There are a lot of good materials on this topic, I don’t see any sense in describing it. I want to dwell on some points that, in my opinion, may be interesting.
Track MySQL replication status.
At work, I wanted to be able to easily see if replication was not interrupted. Each time it is tiring to enter the subordinate north through the console in ESXi or through the Main server. To solve this problem, I copied a PHP script (checkslave.php) to the slave server, the main function of which is to obtain the status of replication from MASTER and RAB and display them as a table. The main server cannot poll the slave, since in MySQL, he has no rights to it, the subordinate has the right to access the main thing, but not vice versa. The status is obtained when executing the commands:
SHOW SLAVE STATUSand
SHOW MASTER STATUSBecause users have access only to the Chief, on it I added the command to cron:
wget --no-check-certificate 10.10.10.3/checkslave.php -O /var/www/checkslave.html wget --no-check-certificate 10.10.10.3/checkslave.php -O /var/www/checkslave.html , which requests from the slave server checkslave.php and saves its output to the html file on the Main server. Accordingly, you can look at the main server in the browser this file and see if there are problems with replication.Replication rupture protection.
As I worked, I encountered the fact that replication was easily broken with any SQL change request running on a slave server. This immediately led to the creation of duplicates in unique keys and in general to inconsistency of data. It was enough to enter the corporate portal on it and replication was interrupted. To make replication more reliable, I added the following. On the slave server, I added two PHP scripts: one gave the rights to change to the MySQL user, under which the corporate portal scripts run, and the second took away those rights using the SQL
GRANT and REVOKE . The management scripts themselves are connected to MySQL under a different user, under the same ones that the MASTER and RAB status polling scripts work.Then I wrote a small script that checks whether the Slave server has a connection with the Main server and accordingly launches the script for opening / closing the Slave server database for changes. The script runs on a schedule every 5 minutes. Accordingly, after 5 minutes after the break of communication, users will be able to work with the slave server, and if the link has not been broken, the slave server will remain closed from changes:
#!/bin/bash
count=$(ping -c 8 10.10.10.2 | grep 'received' | awk -F',' '{ print $2 }' | awk '{ print $1 }')
if [ $count -eq 0 ]; then
php -f /folder/slave_open.php
else
php -f /folder/slave_close.php
fi
Synchronization scripts.
In addition to database synchronization, it is important that PHP scripts and other work files also change on the slave server when changes are made on the Master. To solve this problem, I added the following command on the Slave server:
rsync -avz 10.10.10.2:/var/www/ /var/wwwWork corporate portal with files.
In addition to PHP scripts, the corporate portal manages user files, which should also be available on both the Master and Slave servers. To make this possible, I removed the storage of these files to a separate file server of the enterprise running Windows Server 2008. There I got a separate folder, wrote a script that checks on both virtual machines whether the folder is in mounted drives, and if not, mounts it.
flag=0
mnt_path='/folder'
mnt_test=`mount -t cifs`
flag=`expr match "$mnt_test" '.*folder.*'`
if [ "$flag" = "0" ]
then mount -t cifs -o username=user,password=pass,uid=bitrix,gid=bitrix,iocharset=utf8,codepage=866 //172.20.15.21/portal_folder /folder
fi
Further, all PHP scripts save user files on a specific system in this mounted folder. If the job switches to the slave server, it immediately mounts the folder itself when it includes a network cable and everyone continues to work. And even if both servers fail, you can directly use the files on the file server.
Thank you if you have read to the end!
Source: https://habr.com/ru/post/133641/
All Articles