ABBYY Cloud OCR SDK: Public Recognition API in the Windows Azure Cloud
 Until recently, on the web, our recognition technologies "lived" only on the site www.abbyyonline.com , this service is intended for end users. And now we are ready to announce the launch of a beta version of web recognition API for developers. Meet ABBYY Cloud OCR SDK , the “cloud brother” already familiar to our readers ABBYY FineReader Engine .
Until recently, on the web, our recognition technologies "lived" only on the site www.abbyyonline.com , this service is intended for end users. And now we are ready to announce the launch of a beta version of web recognition API for developers. Meet ABBYY Cloud OCR SDK , the “cloud brother” already familiar to our readers ABBYY FineReader Engine .We have long wanted to release a product that would allow the use of OCR-technology with all sorts of "thin" and not very devices and all kinds of operating systems and at the same time was convenient and inexpensive. We hope we did it. ABBYY Cloud OCR SDK requires payment as it is used, so that quality recognition functions become available with minimal initial investment.
Under the cut, we will tell you more about how we worked on it and what we did. While the service is in closed beta testing, but we believe that it is already quite stable, and the open beta stage is getting closer. We would like to invite Habr's readers to become one of the first "external" beta testers of ABBYY Cloud OCR SDK. How to get access - also under the cut.
')
Cloud Recognition API can be used in many scenarios. For example, include recognition functionality in an application in which it is not the main one. Or you can make a “light” mobile application in which the user photographs the document, then this document is sent to the server for recognition, and the result comes back. In this scenario, you can make a program that recognizes business cards, almost all phones.
You can also add recognition to a web application. You can still install FineReader Engine on the server, but if you want to do without it, the cloud service should help here.
Service API
For the first version, we really wanted the recognition API to be accessible from under any operating system and from any device that has access to the Internet, while remaining as simple as possible. Therefore, we made it in the form of several RESTful job creation requests, getting information about statuses and links to downloading results. Each processing request must be authorized, if desired, you can enable ssl and encrypt traffic.
A typical scenario of working with the service looks like this. A client program, sending images using one or several POST requests, creates a task on the server. After the task is formed, it is necessary to send it for processing, specifying the processing settings. The settings depend on the type of processing being performed.
For example, if you are simply recognizing the whole document, you can (there are defaults) specify the document language and the format in which you want to get the result. Now pdf, docx, txt, xml and several others are supported.
You can recognize barcodes (the slider itself finds the barcode in the picture and determines its type), you can recognize handwritten text, which is usually filled in questionnaires. We also brought a business card recognizer to the API: you send a business card image to the server, and in return you get a vCard with the recognized text and all the fields found: name, surname, address, etc.
After each request, the server issues xml, which contains all the information about the task: its ID, cost, status and estimated time until the end of processing.
Tasks that are ready for processing are placed in the server queue, from where the next released handler takes them. The client program learns about changes in the status of tasks through a special request.
After the task is processed, a link appears in the server's response, where you can download the result.
Schematically, the sequence of commands for processing one photo is depicted in the figure:
Larger

In the ideal case, only 3 requests are required - in the first request, the image is sent to the server and queued for processing. In the second, you find out that the task is ready, and you get a link to download. On the third query, the result is downloaded.
We plan to further expand the service API. Notifications about job status changes will appear via user-provided URLs, advanced task settings, and more. When designing the next version of the API, we also hope to get information from you about features that the product lacks in your usage scenarios.
How is everything inside
Service works under control of Windows Azure. It turned out to be quite convenient, there is no need to think about the hardware and the operating system, under which everything works, and you can focus on the logic of the application.
Schematically, the solution architecture looks like this:
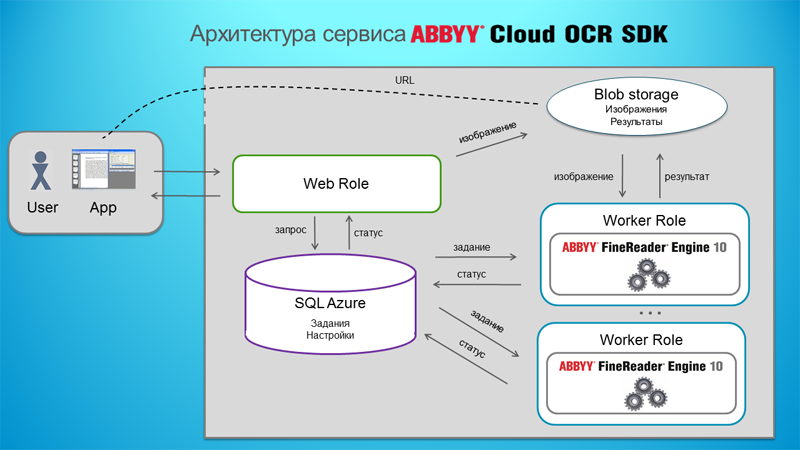
The service consists of several parts. User data is stored in Blob storage, settings and tasks are stored in the database. Web roles are responsible for interacting with user applications and the web interface, while worker roles are responsible for recognition.
Web roles implement a RESTful service API. They authorize the user, get tasks, add images to blob storage, job descriptions are placed in the database, and generate answers.
Several worker roles are responsible for processing tasks. The identifier of the next task is taken from the database, from the blob - the files related to this task. Everything is processed, then the results are placed in the blob, and the database is marked that the task was successfully processed.
Then, after the user application once again inquires about the status of its task, a special link to the blob is generated for it, using which you can get the result. The link has a limited lifetime and a special checksum, so that access to the results, even knowing the ID of your task, is possible only through this link.
Processed jobs live on the server for some time, after which they are deleted.
Clients and platforms
For the Cloud OCR SDK API, it is enough just to write a client in any programming language and for any operating system.
For example, for fans of pure Linux, we have a script for bash + curl. The complete file processing cycle is only 10 lines of code. Hopefully clear enough :-).
For supporters of more traditional solutions there are examples of clients on .net, java and python, as well as Android application templates.
All source codes are laid out in the form of the project on github. We hope to gradually improve them, listening to your wishes.
Beta testing
We invite all users of Habr to participate in the beta testing service. If you want to join the testing, go to http://ocrsdk.com . First you need to register and fill out an application form for using the ABBYY Cloud OCR SDK. Any user who filled out the form immediately gets the opportunity to recognize 100 pages or 500 small text pieces for free. But if for some reason you didn’t have enough of it - write to us, add more :-)
To make it easier for you to start working with the service, we made several examples in popular programming languages and picked up a database of images on which you can test for free.
In addition, both during beta testing and after, we apply the principle of not taking money twice for recognizing the same image. If you have already recognized the picture once, then you can re-recognize it with different settings, but for free. This is especially useful if you are debugging the logic of your application, driving it in a circle under the debugger. We are sure that such use should not be paid to the developer. To check for the coincidence of images, we check their checksums but, alas, we cannot check for coincidence different photos of the same document.
We are very interested in your feedback and wishes! Write them in the comments to this text or to the technical support address in the user's personal account at http://ocrsdk.com .
Update: In the questionnaire and in letters we can write in Russian :-).
Vasily Panferov,
Product Development Department
Source: https://habr.com/ru/post/133624/
All Articles