Hask category
Introduction
In this short article I will talk about category theory in the context of the Haskell type system. No zaumy, no tricks - I will try to explain everything clearly. I want to show the close connection of a programming language with mathematics in order to provoke the reader's awareness of one thing, through the other and vice versa.
I would not like to repeat the translation on this topic, which was already on Habré: Monads from the point of view of category theory , but for the integrity of the article, I will still give basic definitions. At the same time, unlike the article, I do not want to focus on mathematics.
This article largely repeats (including borrowing illustrations) a section from the English Haskell Wikibook , but nonetheless is not a direct translation.
')
What is a category?
Examples
For clarity, we first consider a couple of pictures depicting simple categories. They have red circles and arrows:
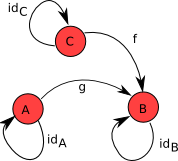

Red circles represent “objects”, and arrows - “morphisms”.
I want to give one illustrative example from real life, which will give some intuitive insight into the nature of objects and morphisms:
Cities can be considered “objects”, and movements between cities - “morphisms”. For example, you can imagine a flight map (I somehow did not find a good picture) or a railroad map - they will look like the pictures above, only more complicated. Attention should be paid to two points that seem to be taken for granted, but are important for the future:
- It happens that there is no way to get from one city to another by train or by plane - there are no morphisms between these cities.
- If we move within the same city, then this is also a morphism - we are traveling from the city to it, as it were.
- If there is a train from St. Petersburg to Moscow, and from Moscow there is a flight to Amsterdam, then we can buy a train ticket and a plane ticket, “combine” them and thus get from St. Petersburg to Amsterdam - that is, you can map draw an arrow from St. Petersburg to Amsterdam depicting this combined morphism.
Definition
So, we already know that a category consists of objects and morphisms:
- There is a class (set) of objects . Objects can be any entities.
- For any two objects
AandB, the class of morphismsHom(A,B)defined. For a morphismffrom this class, the objectAis called a domain , andBis a co - domain . It is written like this:f ∈ Hom(A,B)orf : A → B - For any two morphisms
f : A → Bandg : B → C, their composition is defined — the morphismh = g ∘ f,h : A → CIt is important that the domaingand the domainfcoincide. - The composition is associative , that is, for any morphisms
f : A → B,g : B → Candh : C → D, the equality(h ∘ g) ∘ f = h ∘ (g ∘ f) - For any object
Athere is a “unit” morphism, which is denotedidA: A → Aand it is neutral with respect to the composition, that is, for any morphismf : A → Bsatisfied:idB∘ f = f = f ∘ idA
id , since its area / area is restored from the context.It can be verified that for the examples above, all the properties are fulfilled: the composition is defined when necessary, associative, and the corresponding isolated morphisms are neutral with respect to it. The only problem arises from the associativity in the example about moving between cities - here you need to think about the composition as “combining tickets”, and not just sequential movements of a particular person.
Exercise for self-test: check whether the following picture represents a category

Hask category
And now the main example, the main topic of the article. The Hask category consists of Haskell language types and functions between them. More strictly:
- Hask objects: data types with 1
*. For example, primitive types:Integer,Bool,Char, etc. The “Type”Maybehas a command* → *, but the typeMaybe Boolhas a command*and is therefore an object in Hask . The same with any parameterized types, but about them later. Notation:a ∷ *≡ “typeahas a keynd*” ≡ “ais an object in Hask ”. - Hask morphisms : any Haskell functions from one object (type) to another. If
a, b ∷ *, then the functionf ∷ a → bis a morphism with a domainaand a domainb. Thus, the class of morphisms between objectsaandbis denoted by the typea → b. For completeness of the analogy with mathematical notation, we can introduce the following synonym:type Hom(a,b) = a → b - Composition: standard function
(.) ∷ (b → c) → (a → b) → (a → c). For any two functionsf ∷ a → bandg ∷ b → ccomposition isg . f ∷ a → cg . f ∷ a → cis determined in a natural way:g . f = λx → g (fx) - The composition associativity is obvious from this definition: For any three functions
f ∷ a → b,g ∷ b → candh ∷ c → d
Direct check:(h . g) . f ≡ h . (g . f) ≡ λx → h (g (fx))(h . g) . f ≡ λx → (h . g) (fx) ≡ λx → (λy → h (gy)) (fx) ≡ λx → h (g (fx)) h . (g . f) ≡ λx → h ((g . f) x) ≡ λx → h ((λy → g (fy)) x) ≡ λx → h (g (fx)) - For any type
a ∷ *functionid ∷ a → ais also defined in a natural way:id = λx → xf ∷ a → bf . id ≡ λx → f (id x) ≡ λx → fx ≡ f id . f ≡ λx → id (fx) ≡ λx → fx ≡ f
Char object it will be a monomorphic function id ∷ Char → Char . That's why I said before about the index - in Haskell, you can not write every time what id we need, because its type is automatically taken out of context.So, as we see, all the required entities are present, their interrelationships are presented, and the required properties are fulfilled, so Hask is a full-fledged category. Notice how all concepts and constructs are transferred from mathematical notation to Haskell with minimal syntactic changes.
Then I will talk about what functors are and how they are embodied in the category Hask .
Functors
Functors are transformations from one category to another. Since each category consists of objects and morphisms, the functor should consist of a pair of mappings: one will match objects from the first category to objects in the second, and the other will map to morphisms from the first category — morphisms to the second.
First I will give a mathematical definition, and then I will demonstrate how simple it becomes in the case of Haskell.
Mathematical definition
Consider two categories
C and D and the functor F from C to D The notation used is the same as for morphisms, only the functor is denoted by a capital letter: F : C → D This F performs two roles:- Each object
Afrom categoryCis associated with an object from categoryDand is denoted byF(A). - Each morphism
g : A → Bfrom categoryCis associated with a morphism from categoryDand denoted byF(g) : F(A) → F(B).
A ↦ F(A) g : A → B ↦ F(g) : F(A) → F(B) In the picture, the first display is depicted with yellow dotted arrows, and the second is blue:
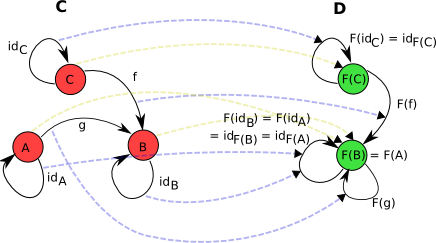
The functor is required to fulfill two completely natural requirements:
- He must translate every single morphism of a given object into a single morphism of its image:
F(idA) = idF(A) - He must translate the composition of morphisms into the composition of their images:
F(h ∘ g) = F(h) ∘ F(g)
Functors in Hask
Now we look at functors from the Hask category in Hask . By the way, such functors that translate a category into it are called endofunctors .
So, then we need to translate types into types, and functions in functions are two mappings. And what is the construction language Haskell embodies the first? That's right, types with a knight
* → * .For example, the
Maybe ∷ * → * type mentioned already Maybe ∷ * → * . This is a mapping that matches to any object a ∷ * an object from the same category (Maybe a) ∷ * . Here, Maybe a should be taken not as a constructor of a parameterized type with a given parameter a , but as a single character, similar to F(A) from a mathematical definition.So, the first mapping comes to us for nothing - this is any type constructor with a parameter.
data Maybe a = Nothing | Just a But how to get the second display? To do this, Haskell has a special class defined:
class Functor f where fmap ∷ (a → b) → (fa → fb) where f ∷ * → * . That is, fmap is a polymorphic function that takes the morphism a → b , and returns the morphism fa → fb . Based on this, we will make Maybe real functor, defining the following function for it: instance Functor Maybe where fmap g = fg where fg Nothing = Nothing fg (Just x) = Just (gx) So, we got two maps:
a ∷ * ↦ Maybe a ∷ * g ∷ a → b ↦ fmap g ∷ Maybe a → Maybe b There is nothing that, unlike mathematical notation, they have different names, it is just the specificity of the language, which does not affect the meaning.
Well, what about meeting the requirements?
fmap must save the id and translate the composition into the composition: fmap id ≡ id fmap (h . g) ≡ (fmap h) . (fmap g) It is easy to verify this in the case of the above definition of
fmap for Maybe .Notice that we get the first mapping by simply declaring a type constructor with a parameter. And for him, as for the mapping between objects, it does not matter how the
Maybe type is arranged: it simply associates with the object a object Maybe a , whatever that may be.In the case of the display of morphisms, everything is not so simple: we have to manually define
fmap , taking into account the Maybe structure. On the one hand, this gives us a certain flexibility - we decide how a function will transform a specific data structure. But on the other hand, it would be convenient to receive this definition for nothing, if we want it to be organized in a natural way. For example, for the type data Foo a = Bar a Int [a] | Buz Char Bool | Qux (Maybe a) the function g ∷ a → b should recursively bypass all data constructors and wherever they have a parameter of type a convert it with g . Moreover, if [a] or Maybe a is encountered, then their fmap g should work for them, which again bypasses their structure and transforms it.And lo and behold, it is possible! GHC has a corresponding extension . We write in the code:
{-# LANGUAGE DeriveFunctor #-} … data Foo a = … deriving Functor And we immediately get a full end - function of the category Hask -
Foo , with the corresponding fmap .By the way, it should be said that these functors actually map the Hask category into its subcategory , that is, into a category with a smaller class of objects and morphisms. For example, by displaying
a ↦ Maybe a we can’t get a simple type Int - whatever a we took. Nevertheless, the resulting subclass of objects and the class of functions on them as morphisms also form a category.In the Functor class documentation, you can also see a list of types for which the embodiment was originally defined. But they are mainly made in order to then say that this type is a monad.
Conclusion
So, I talked about the Hask category and the functors in it, and I hope it helped to realize the Haskell type system from a new perspective. Perhaps it seems useless from a practical point of view, since the meaning of
fmap everyone probably understands in its own way and without knowing what a functor is. But then I’m going to write about natural transformations, monads and other categorical constructions in the key of the Hask category and then, I think, mathematical analogies will be more useful, allowing you to better understand the inner nature of these constructions of the language and apply them further more consciously.- If who did not meet earlier with kaynd (kinds), I will explain in two words. Kaynda is something like a type system over ordinary types. Kaynda are of two types:
*- this is a simple, not parameterized type. For example,Bool,Char, etc. Customdata Foo = Bar | Buz (Maybe Foo) | Quux [Int]typedata Foo = Bar | Buz (Maybe Foo) | Quux [Int]data Foo = Bar | Buz (Maybe Foo) | Quux [Int]data Foo = Bar | Buz (Maybe Foo) | Quux [Int]will also be simple:Foo ∷ *, because the type constructor has no parameters (although its data constructors have)… → …- this is a more complicated keynd, it can have any other keyes composed of*and→on the ground ellipsis. For example:[] ∷ * → *, or(,) ∷ * → (* → *)or anything else more complicated:((* → *) → *) → (* → *).
The meaning of all this is simple: type constructors are kind of functions on types and describe how these functions interact correctly. For example, we cannot write[Maybe], because[] ∷ * → *, that is, the argument of the parentheses must have a kand*, whileMaybeit has* → *, that is,Maybealso a function and if we give it an argumentInt ∷ *, then we getMaybe Int ∷ *and we can already pass it to the brackets:[Maybe Int] ∷ *. For this kind of control, the kayndas exist.
Source: https://habr.com/ru/post/133277/
All Articles