Condé Nast Traveler multimedia project website and mobile applications launched on the 1C-Bitrix web cluster on Amazon
Good afternoon, colleagues!
Condé Nast Digital Russia has launched a multimedia project for travelers Condé Nast Traveler , which combines a print edition , its digital version , a website and a mobile application . The project started on September 21, 2011. The product of 1C-Bitrix on a web cluster platform was chosen as the web base, as a hosting site, based on our recommendations - the Amazon cloud .
The website www.cntraveller.ru contains articles about travels and, most importantly, makes it possible to quickly find information about hotels, restaurants, places for entertainment in different countries of the world, add your own objects, photos and reviews to the site, create a guide for future travel. All data about the objects are also used by the iPhone application “Condé Nast Traveler - My Addresses” , with which you can not only draw up a travel route, but also, having determined your location on the map, see the nearest addresses recommended by the editors of the magazine and site visitors.
')
In general, the project is unique, large and interesting - you cannot tell everything in one paragraph - see for yourself if you are interested. And our goal is to look under the hood of the project.
So, we critically evaluate the architecture and reliability of the solution. Weigh the pros and cons of cloud hosting and Bitrix clustering technologies used.
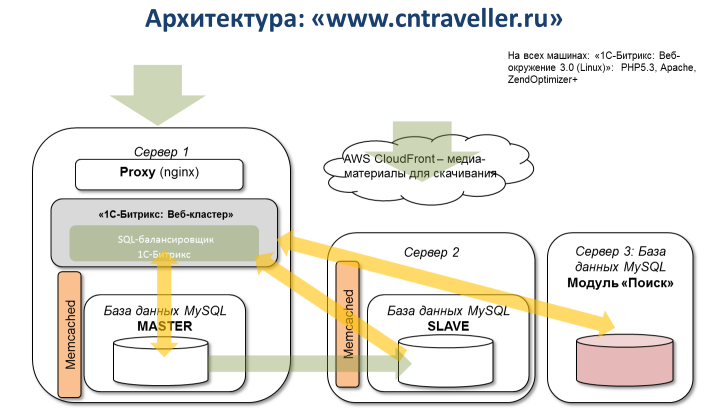
Statics are moved to the cloud and distributed from CDN (CloudFront) using the “Cloud Storage” module functionality. Of course, you can organize work with files using the FUSE- module, for example, s3fs , however, the internal “information trees” are easier to take to the clouds using the platform’s built-in tools.
A typical MySQL master-slave replication is used, but load balancing is performed by the core of the Bitrix platform — so you don’t need to make changes to an existing application, which doesn’t care - one database or master + 20 slaves.
We see a clustered cache based on memcached, built into the Bitrix cluster platform - which will work when any of its nodes fail, and also automatically supersedes the “outdated” data. This is especially true for large, high-load projects, in which a large amount and number of cache files are created (sometimes because of errors) - if you keep such a cache in the file system, you need to constantly monitor its size and periodically clear outdated data.
The search index, which is intensively used by visitors and external applications of the project, accessing the system using web services , using the “vertical sharding” method, is delivered to a separate server through a master in the admin area. With increasing intensity of use of search services - it is possible within a couple of minutes ( through the Amazon API ) to overload the machine on a more “powerful” hardware.
With increasing load, Server 2 can connect automatically and be used as an application server.
Backups of the project machines are done by snapshots of EBS disks in S3 . If an aircraft or a ballistic missile hits a data center (Availability Zone), the machines with disks can be lifted in a few minutes in another data center (Availability Zone). Snapshots are stored as increments with auto-consolidation, so they can be done at least once every 10 minutes. For a backup of a DB by snapshot of an EBS disk, it will shortly crash (" FLUSH TABLES WITH READ LOCK ") and its file system will freeze for a short time ( fsfreeze ).
To quickly restore access to the most up-to-date data in the database (if, say, the file system crumbled on the database master), the database slave easily switches to the master mode and is used by the project. If you wish, you can automate this process. It is even better to do repilation to another Amazon data center (Availability Zone) and then during a “lightning strike” to the current data center it will be possible in a few minutes: a) pick up the machines from snapshots in another data center, b) change the hardware configuration of the slave database (via API Amazon) and reboot it, c) switch DNS to use another balancer or, if you use the balancer built into Amazon, the traffic will be redirected to another data center automatically or will require a minimum configuration of ELB (for full automation, you need to configure s group autoscale AWS AutoScaling ).
With an increase in the volume of readings on the database, it is possible, without interrupting the work of the project, to add server-to-left databases. To handle the increased volume of records on the master, you can increase the power of hardware (through an Amazon API call) of Server 1, or transfer the master database to a separate server.
If you increase the load on the PHP application server (“Server 1”), you can add one or several application servers (without rewriting the project code), synchronizing their files using, for example, csync2 (in Amazon, you cannot mount one EBS disk to several servers for cluster FS of type ocfs2 ). Of course, then the application servers must be hidden behind the load balancer. In this case, the built-in fail-safe and scalable Amazon ELB balancer or a low-power machine with nginx may be perfect. It is reasonable to put the SSL test to the balancer (Amazon can do this) - so as not to spread certificates over the application servers.
By knowing and effectively exploiting the capabilities of cloud hosters and using a platform that supports clustering technology without rewriting for this web project, you can quickly and confidently deploy a virtually “unkillable” web system. If necessary, this web-based system is completely easy to scale - in different ways, both automatically and manually, depending on the preferences of the clients of a high-loaded resource.
And to read the following entries in your feed, click "Like" in the company profile , and check your tape setup.
Condé Nast Digital Russia has launched a multimedia project for travelers Condé Nast Traveler , which combines a print edition , its digital version , a website and a mobile application . The project started on September 21, 2011. The product of 1C-Bitrix on a web cluster platform was chosen as the web base, as a hosting site, based on our recommendations - the Amazon cloud .
The website www.cntraveller.ru contains articles about travels and, most importantly, makes it possible to quickly find information about hotels, restaurants, places for entertainment in different countries of the world, add your own objects, photos and reviews to the site, create a guide for future travel. All data about the objects are also used by the iPhone application “Condé Nast Traveler - My Addresses” , with which you can not only draw up a travel route, but also, having determined your location on the map, see the nearest addresses recommended by the editors of the magazine and site visitors.
')
In general, the project is unique, large and interesting - you cannot tell everything in one paragraph - see for yourself if you are interested. And our goal is to look under the hood of the project.
So, we critically evaluate the architecture and reliability of the solution. Weigh the pros and cons of cloud hosting and Bitrix clustering technologies used.
Architecture of high-loaded solutions "on the box"
Statics are moved to the cloud and distributed from CDN (CloudFront) using the “Cloud Storage” module functionality. Of course, you can organize work with files using the FUSE- module, for example, s3fs , however, the internal “information trees” are easier to take to the clouds using the platform’s built-in tools.
A typical MySQL master-slave replication is used, but load balancing is performed by the core of the Bitrix platform — so you don’t need to make changes to an existing application, which doesn’t care - one database or master + 20 slaves.
We see a clustered cache based on memcached, built into the Bitrix cluster platform - which will work when any of its nodes fail, and also automatically supersedes the “outdated” data. This is especially true for large, high-load projects, in which a large amount and number of cache files are created (sometimes because of errors) - if you keep such a cache in the file system, you need to constantly monitor its size and periodically clear outdated data.
The search index, which is intensively used by visitors and external applications of the project, accessing the system using web services , using the “vertical sharding” method, is delivered to a separate server through a master in the admin area. With increasing intensity of use of search services - it is possible within a couple of minutes ( through the Amazon API ) to overload the machine on a more “powerful” hardware.
With increasing load, Server 2 can connect automatically and be used as an application server.
Reliability
Backups of the project machines are done by snapshots of EBS disks in S3 . If an aircraft or a ballistic missile hits a data center (Availability Zone), the machines with disks can be lifted in a few minutes in another data center (Availability Zone). Snapshots are stored as increments with auto-consolidation, so they can be done at least once every 10 minutes. For a backup of a DB by snapshot of an EBS disk, it will shortly crash (" FLUSH TABLES WITH READ LOCK ") and its file system will freeze for a short time ( fsfreeze ).
To quickly restore access to the most up-to-date data in the database (if, say, the file system crumbled on the database master), the database slave easily switches to the master mode and is used by the project. If you wish, you can automate this process. It is even better to do repilation to another Amazon data center (Availability Zone) and then during a “lightning strike” to the current data center it will be possible in a few minutes: a) pick up the machines from snapshots in another data center, b) change the hardware configuration of the slave database (via API Amazon) and reboot it, c) switch DNS to use another balancer or, if you use the balancer built into Amazon, the traffic will be redirected to another data center automatically or will require a minimum configuration of ELB (for full automation, you need to configure s group autoscale AWS AutoScaling ).
Where to grow
With an increase in the volume of readings on the database, it is possible, without interrupting the work of the project, to add server-to-left databases. To handle the increased volume of records on the master, you can increase the power of hardware (through an Amazon API call) of Server 1, or transfer the master database to a separate server.
If you increase the load on the PHP application server (“Server 1”), you can add one or several application servers (without rewriting the project code), synchronizing their files using, for example, csync2 (in Amazon, you cannot mount one EBS disk to several servers for cluster FS of type ocfs2 ). Of course, then the application servers must be hidden behind the load balancer. In this case, the built-in fail-safe and scalable Amazon ELB balancer or a low-power machine with nginx may be perfect. It is reasonable to put the SSL test to the balancer (Amazon can do this) - so as not to spread certificates over the application servers.
PS
By knowing and effectively exploiting the capabilities of cloud hosters and using a platform that supports clustering technology without rewriting for this web project, you can quickly and confidently deploy a virtually “unkillable” web system. If necessary, this web-based system is completely easy to scale - in different ways, both automatically and manually, depending on the preferences of the clients of a high-loaded resource.
And to read the following entries in your feed, click "Like" in the company profile , and check your tape setup.
Source: https://habr.com/ru/post/133068/
All Articles