Once again about finding prime numbers
") This note discusses sieve algorithms for finding primes. We will consider in detail the classical sieve of Eratosthenes, the features of its implementation in popular programming languages, parallelization and optimization, and then we will describe the more modern and fast Atkin sieve. If the material on the sieve of Eratosthenes is intended primarily to protect beginners from regular walking on a rake, then the Atkin sieve algorithm was not previously described in Habrahabr.
This note discusses sieve algorithms for finding primes. We will consider in detail the classical sieve of Eratosthenes, the features of its implementation in popular programming languages, parallelization and optimization, and then we will describe the more modern and fast Atkin sieve. If the material on the sieve of Eratosthenes is intended primarily to protect beginners from regular walking on a rake, then the Atkin sieve algorithm was not previously described in Habrahabr.The picture shows a sculpture of an abstract expressionist Mark Di Suvero "Sieve of Eratosthenes", installed on the campus of Stanford University
Introduction
Recall that a number is called simple if it has exactly two different divisors: the unit and itself. Numbers with a greater number of divisors are called composite. Thus, if we can factor numbers into factors, we can also check numbers for simplicity. For example, something like this:
function isprime(n){ if(n==1) // 1 - return false; // 2 sqrt(n) for(d=2; d*d<=n; d++){ // , if(n%d==0) return false; } // , return true; } The running time of such a test is obviously O ( n ½ ), that is, it grows exponentially with respect to the bit length n . This test is called brute force check.
')
Quite unexpectedly, there are a number of ways to test the simplicity of a number without finding its divisors. If the polynomial factorization algorithm still remains an unattainable dream (which is what RSA encryption is based on), then the AKS [ 1 ] test for simplicity works out in 2004 in a polynomial time. With various effective tests for simplicity can be found on [2].
If now we need to find all simple ones on a fairly wide interval, then the first impulse will probably be to test each number from the interval individually. Fortunately, if we have enough memory, we can use faster (and simple) sieve algorithms. In this article we will discuss two of them: the classical sieve of Eratosthenes, known to the ancient Greeks, and the Atkin sieve, the most advanced modern algorithm of this family.
Sieve of Eratosthenes
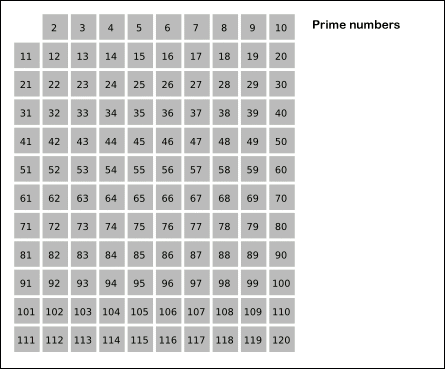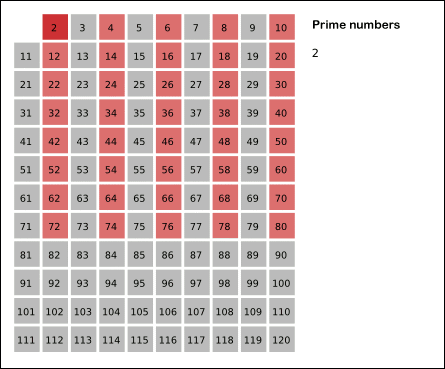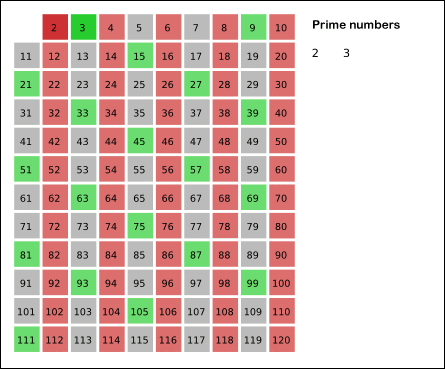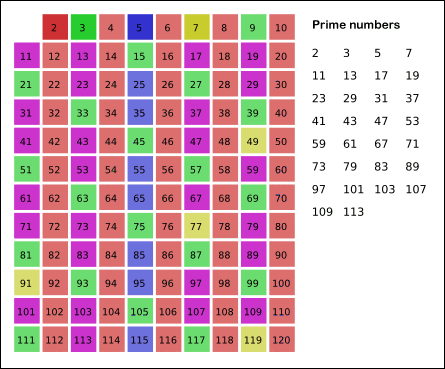
The ancient Greek mathematician Eratosthenes proposed the following algorithm for finding all simple numbers that do not exceed a given number n. Take an array S of length n and fill it with units ( mark as unclosed ). Now we will successively look at the elements of S [ k ], starting with k = 2. If S [ k ] = 1, then fill in with zeroes ( cross out or drop out ) all subsequent cells whose numbers are multiples of k. As a result, we obtain an array in which the cells contain 1 if and only if the cell number is a prime number.
You can save a lot of time if you notice that, since a composite number has number less than n, at least one of the divisors does not exceed
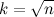 . Here is an animation of the sieve of Eratosthenes, taken from Wikipedia:
. Here is an animation of the sieve of Eratosthenes, taken from Wikipedia:
Some more operations can be saved if, for the same reason, to begin eliminating multiples of k, starting not with 2k, but from the number k 2 .
The implementation will take the following form:
function sieve(n){ S = []; S[1] = 0; // 1 - // for(k=2; k<=n; k++) S[k]=1; for(k=2; k*k<=n; k++){ // k - ( ) if(S[k]==1){ // k for(l=k*k; l<=n; l+=k){ S[l]=0; } } } return S; } The effectiveness of the sieve of Eratosthenes is caused by the extreme simplicity of the internal cycle: it does not contain conditional transitions, as well as "heavy" operations like division and multiplication.
We estimate the complexity of the algorithm. The first crossing out requires n / 2 actions, the second - n / 3, the third - n / 5, etc. According to the Mertens formula
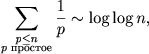
so that O ( n log log n ) operations are required for the sieve of Eratosthenes. The memory consumption is O ( n ).
Optimization and parallelization
The first sieve optimization was proposed by Eratosthenes himself: since only 2 of all even numbers is simple, then let's save half of the memory and time and write out and sow only odd numbers. The implementation of such a modification of the algorithm will require only cosmetic changes ( code ).
More advanced optimization (so-called wheel factorization ) relies on the fact that all simple but 2, 3 and 5 lie in one of the following eight arithmetic progressions: 30 k +1, 30 k +7, 30 k +11, 30 k +13, 30 k +17, 30 k +19, 30 k +23 and 30 k +29. To find all prime numbers up to n , we first calculate (again using a sieve) all prime numbers
By increasing the step of the progression and the number of sieves (for example, with a step of progression 210, we will need 48 sieves, which will save another 4% of resources) along with the growth of n , we can increase the speed of the algorithm by log log n times.
Segmentation
What to do if, in spite of all our tricks, there is not enough RAM and the algorithm shamelessly “swaps”? It is possible to replace one large sieve with a sequence of small strainers and sow each separately. As above, we will have to first prepare a list of simple ones.
Do not make the strainers too small, less than the same O ( n ½-ε ) elements. So you will not gain anything in the asymptotics of memory consumption, but due to overhead costs you will start to lose more and more in performance.
Sieve of Eratosthenes and one-liners
Habrahabr previously published a large collection of Eratosthenes algorithms in a single line in different programming languages (single-line number 10). Interestingly, all of them are in fact not the sieve of Eratosthenes and implement much slower algorithms.
The fact is that filtering a set by the condition (for example,
primes = primes.select { |x| x == prime || x % prime != 0 } in Ruby) or using aka list comprehensions generator lists (for example, let pgen (p:xs) = p : pgen [x|x <- xs, x `mod` p > 0] on Haskell) they cause exactly what the sieve algorithm is designed to avoid, namely, element-by-element checking of divisibility. As a result, the complexity of the algorithm increases at least to 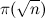 (this is the number of filterings) multiplied by
(this is the number of filterings) multiplied by 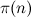 (the minimum number of elements of the filtered set), where
(the minimum number of elements of the filtered set), where 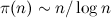 - the number of simple actions that do not exceed n , i.e., to O ( n 3/2-ε ) actions.
- the number of simple actions that do not exceed n , i.e., to O ( n 3/2-ε ) actions.One-liner
(n: Int) => (2 to n) |> (r => r.foldLeft(r.toSet)((ps, x) => if (ps(x)) ps -- (x * x to n by x) else ps)) on Scala closer to the Eratosthenes algorithm in that it avoids divisibility checking. However, the complexity of constructing the difference of sets is proportional to the size of the larger of them, so that the result is the same O ( n 3/2-ε ) operations.In general, the sieve of Eratosthenes is difficult to effectively implement within the functional paradigm of immutable variables. In case the functional language (for example, OCaml) allows, it is worth breaking the norms and having a variable array. In [ 3 ], it is discussed how to correctly implement the Eratosthenes sieve on Haskell with the help of a lazy strikeouts technique.
Sieve Eratosthenes and PHP
We write the algorithm of Eratosthenes in PHP. It turns out about the following:
define("LIMIT",1000000); define("SQRT_LIMIT",floor(sqrt(LIMIT))); $S = array_fill(2,LIMIT-1,true); for($i=2;$i<=SQRT_LIMIT;$i++){ if($S[$i]===true){ for($j=$i*$i; $j<=LIMIT; $j+=$i){ $S[$j]=false; } } } There are two problems here. The first one is related to the data type system and is characteristic of many modern languages. The fact is that the most effective sieve of Eratosthenes is realized in those PLs where it is possible to declare a homogeneous array consistently located in memory. Then the calculation of the address of the cell S [i] takes only a couple of processor commands. An array in PHP is in fact a heterogeneous dictionary, that is, it is indexed by arbitrary strings or numbers and may contain data of various types. In this case, finding S [i] becomes a much more laborious task.
The second problem: arrays in PHP are terrible in memory overhead. On my 64-bit system, each element of $ S from the code above eats up 128 bytes. As discussed above, it is not necessary to keep the entire sieve in memory at once, it is possible to process it in portions, but still such expenses should be considered inadmissible.
To solve these problems, it is enough to choose a more suitable data type - a string!
define("LIMIT",1000000); define("SQRT_LIMIT",floor(sqrt(LIMIT))); $S = str_repeat("\1", LIMIT+1); for($i=2;$i<=SQRT_LIMIT;$i++){ if($S[$i]==="\1"){ for($j=$i*$i; $j<=LIMIT; $j+=$i){ $S[$j]="\0"; } } } Now each element takes exactly 1 byte, and the operation time has decreased by approximately three times. Script for measuring speed .
Sieve Atkina
In 1999, Atkin and Bernstein proposed a new method of sowing compound numbers, called the Atkin sieve. It is based on the following theorem.
Theorem. Let n be a positive integer that is not divisible by any full square. Then
- if n can be represented as 4 k +1, then it is simple if and only if the number of natural solutions of the equation 4 x 2 + y 2 = n is odd.
- if n is representable as 6 k +1, then it is simple if and only if the number of natural solutions of the equation 3 x 2 + y 2 = n is odd.
- if n can be represented as 12 k -1, then it is simple if and only if the number of natural solutions of the equation 3 x 2 - y 2 = n , for which x > y , is odd.
From elementary number theory it follows that all simple, large 3, have the form 12 k +1 (case 1), 12 k +5 (again 1), 12 k +7 (case 2) or 12 k + 11 (case 3) .
To initialize the algorithm, fill the sieve S with zeros. Now for each pair ( x , y ), where
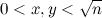 , increment the values in the cells S [4 x 2 + y 2 ], S [3 x 2 + y 2 ], and also, if x > y , then in S [3 x 2 - y 2 ]. At the end of the calculation, the cell numbers of the form 6 k ± 1, containing odd numbers, are either simple or are divided into simple squares.
, increment the values in the cells S [4 x 2 + y 2 ], S [3 x 2 + y 2 ], and also, if x > y , then in S [3 x 2 - y 2 ]. At the end of the calculation, the cell numbers of the form 6 k ± 1, containing odd numbers, are either simple or are divided into simple squares.As a final step, go through the supposedly simple numbers in sequence and cross out multiples of their squares.
From the description it can be seen that the complexity of the Atkin sieve is proportional to n , and not to n log log n as in the Eratosthenes algorithm.
The author's optimized C implementation is presented as primegen , the simplified version is in Wikipedia . On Habrahabr published Atkin's sieve on C #.
As in the sieve of Eratosthenes, using wheel factorization and segmentation, one can reduce the asymptotic complexity by log log n times, and the memory consumption - to O ( n ½ + o (1) ).
About logarithm of logarithm
In fact, the log log n factor is growing extremely. slow. For example, log log 10 10000 ≈ 10. Therefore, from a practical point of view, it can be considered a constant, and the complexity of the Eratosthenes algorithm is linear. Unless the search for simple is a key function in your project, you can use the basic version of the sieve of Eratosthenes (except save on even numbers) and not complex in this regard. However, when searching for simple ones at large intervals (from 2 32 ), the game is worth the trouble, optimization and Atkin's sieve can significantly improve performance.
PS The comments reminded about the Sundaram sieve . Unfortunately, it is only a mathematical wonder and is always inferior either to the sieves of Eratosthenes and Atkin, or to the check by divisors.
Literature
[1] Agrawal M., Kayal N., Saxena N. PRIMES is in P. - Annals of Math. 160 (2), 2004. pp. 781–793.
[2] Vasilenko O.N. Number-theoretic algorithms in cryptography. - M., MTSNMO, 2003. - 328 p.
[3] The Genuine Sieve of Eratosthenes . - 2008.
[4] Atkin AOL, Bernstein DJ Prime sieves using binary quadratic forms . - Math. Comp. 73 (246), 2003. pp. 1023-1030.
Source: https://habr.com/ru/post/133037/
All Articles