How does ConcurrentHashMap
In October, a wonderful article appeared on Habré about the work of HashMap . Continuing this topic, I'm going to talk about the implementation of java.util.concurrent.ConcurrentHashMap.
So, how did ConcurrentHashMap come about, what advantages did it have and how was it implemented.
Before the introduction of ConcurrentHashMap in JDK 1.5, there were several ways to describe hash tables.
Initially, JDK 1.0 was Hashtable class. Hashtable is a thread-safe and easy-to-use hash table implementation. The problem of the HashTable was, first of all, that when accessing the table elements it was completely locked. All Hashtable methods were synchronized. This was a serious limitation for a multi-threaded environment, since the cost of locking the entire table was very large.
In JDK 1.2, HashMap came to the aid of Hashtable and its thread-safe view, Collections.synchronizedMap. There were several reasons for this separation:
Thus, with JDK 1.2, the list of options for the implementation of hash cards in Java has been extended in two more ways. However, these methods did not save the developers from appearing race conditions in their code, which could lead to the appearance of ConcurrentModificationException. This article describes in more detail the possible reasons for their appearance in the code.
And so, in JDK 1.5, a more productive and scalable version finally appears.
By the time ConcurrentHashMap appeared, Java developers needed the following implementation of a hash map:
Doug Lea is an embodiment of a data structure that is included in JDK 1.5.
What are the main ideas for implementing ConcurrentHashMap?
Unlike the HashMap elements, the Entry in ConcurrentHashMap is declared as volatile. This is an important feature, also associated with changes in the JMM. Doug Lea's response to the need to use volatile and possible race condition can be found here .
')
ConcurrentHashMap also uses an improved hash function.
Let me remind you what it was in HashMap from JDK 1.2:
ConcurrentHashMap JDK 1.5 version:
What is the need to complicate the hash function? Tables in a hash map have a length determined by a power of two. For hash codes whose binary representations do not differ in the junior and senior positions, we will have collisions. Complicating the hash function just solves this problem, reducing the likelihood of collisions in the map.
The map is divided into N different segments (16 by default, the maximum value can be 16-bit and be a power of two). Each segment is a thread-safe table of map elements.
A dependency is established between the hash codes of the keys and their corresponding segments based on the application of a bit mask to the high-order bits.
Here’s how the map stores the elements:
Consider what a segment class is:
Given the pseudo-random distribution of key hashes within the table, it can be understood that increasing the number of segments will cause the modification operations to affect different segments, which will reduce the likelihood of locks during execution.
This parameter affects the use of the memory card and the number of segments in the card.
Let's look at the creation of the map and how the concurrencyLevel specified as a parameter of the constructor affects:
The number of segments will be chosen as the nearest power of two, greater than concurrencyLevel. The capacity of each segment, respectively, will be defined as the ratio of the default card capacity value rounded to the nearest greater degree two to the number of segments obtained.
It is very important to understand the following two things. An understating of concurrencyLevel leads to the fact that blocking by streams of map segments during recording is more likely. An overestimation of the indicator leads to inefficient use of memory.
If only one stream will change the map, and the rest will read, it is recommended to use the value 1.
It must be remembered that resize tables for storage inside a picture is an operation that requires additional time (and, often, is not performed quickly). Therefore, when creating a map, it is necessary to have some rough estimates of the statistics for the performance of possible read and write operations.
On javamex you can find an article on synchronizedMap versus ConcurrentHashMap scalability comparison:
As can be seen from the graph, between 5 and 10 million card access operations is a noticeable serious discrepancy, which determines the effectiveness of using ConcurrentHashMap in the case of a high amount of stored data and access operations to them.
So, the main advantages and features of the implementation of ConcurrentHashMap:
In conclusion, I would like to say that ConcurrentHashMap should be applied correctly, with a preliminary assessment of the ratio of reading and writing to the card. It also still makes sense to use HashMap in programs where there is no multiple access from multiple threads to a stored map.
Thank you for your attention!
Useful resources for parallel collections in Java and, in particular, for the work of ConcurrentHashMap:
So, how did ConcurrentHashMap come about, what advantages did it have and how was it implemented.
Prerequisites for creating a ConcurrentHashMap
Before the introduction of ConcurrentHashMap in JDK 1.5, there were several ways to describe hash tables.
Initially, JDK 1.0 was Hashtable class. Hashtable is a thread-safe and easy-to-use hash table implementation. The problem of the HashTable was, first of all, that when accessing the table elements it was completely locked. All Hashtable methods were synchronized. This was a serious limitation for a multi-threaded environment, since the cost of locking the entire table was very large.
In JDK 1.2, HashMap came to the aid of Hashtable and its thread-safe view, Collections.synchronizedMap. There were several reasons for this separation:
- Not every programmer and not every solution needed a thread-safe hash table.
- The programmer had to give a choice, which option is convenient for him to use
Thus, with JDK 1.2, the list of options for the implementation of hash cards in Java has been extended in two more ways. However, these methods did not save the developers from appearing race conditions in their code, which could lead to the appearance of ConcurrentModificationException. This article describes in more detail the possible reasons for their appearance in the code.
And so, in JDK 1.5, a more productive and scalable version finally appears.
ConcurrentHashMap
By the time ConcurrentHashMap appeared, Java developers needed the following implementation of a hash map:
- Thread safety
- No locks of the entire table while it is being accessed
- It is desirable that there were no table locks when performing a read operation.
Doug Lea is an embodiment of a data structure that is included in JDK 1.5.
What are the main ideas for implementing ConcurrentHashMap?
1. Map elements
Unlike the HashMap elements, the Entry in ConcurrentHashMap is declared as volatile. This is an important feature, also associated with changes in the JMM. Doug Lea's response to the need to use volatile and possible race condition can be found here .
')
static final class HashEntry <K, V> {
final K key;
final int hash;
volatile V value;
final HashEntry <K, V> next;
HashEntry (K key, int hash, HashEntry <K, V> next, V value) {
this .key = key;
this .hash = hash;
this .next = next;
this .value = value;
}
@SuppressWarnings ("unchecked")
static final <K, V> HashEntry <K, V> [] newArray (int i) {
return new HashEntry [i];
}
}
2. Hash function
ConcurrentHashMap also uses an improved hash function.
Let me remind you what it was in HashMap from JDK 1.2:
static int hash (int h) {
h ^ = (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
ConcurrentHashMap JDK 1.5 version:
private static int hash (int h) {
h + = (h << 15) ^ 0xffffcd7d;
h ^ = (h >>> 10);
h + = (h << 3);
h ^ = (h >>> 6);
h + = (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
What is the need to complicate the hash function? Tables in a hash map have a length determined by a power of two. For hash codes whose binary representations do not differ in the junior and senior positions, we will have collisions. Complicating the hash function just solves this problem, reducing the likelihood of collisions in the map.
3. Segments
The map is divided into N different segments (16 by default, the maximum value can be 16-bit and be a power of two). Each segment is a thread-safe table of map elements.
A dependency is established between the hash codes of the keys and their corresponding segments based on the application of a bit mask to the high-order bits.
Here’s how the map stores the elements:
final Segment <K, V> [] segments;
transient Set <K> keySet;
transient Set <Map.Entry <K, V >> entrySet;
transient Collection <V> values;
Consider what a segment class is:
static final class Segment <K, V> extends ReentrantLock implements
Serializable {
private static final long serialVersionUID = 2249069246763182397L;
transient volatile int count;
transient int modCount;
transient int threshold;
transient volatile HashEntry <K, V> [] table;
final float loadFactor;
Segment (int initialCapacity, float lf) {
loadFactor = lf;
setTable (HashEntry. <K, V> newArray (initialCapacity));
}
...
}
Given the pseudo-random distribution of key hashes within the table, it can be understood that increasing the number of segments will cause the modification operations to affect different segments, which will reduce the likelihood of locks during execution.
4. ConcurrencyLevel
This parameter affects the use of the memory card and the number of segments in the card.
Let's look at the creation of the map and how the concurrencyLevel specified as a parameter of the constructor affects:
public ConcurrentHashMap (int initialCapacity, float loadFactor, int concurrencyLevel) {
if (! (loadFactor> 0) || initialCapacity <0
|| concurrencyLevel <= 0)
throw new IllegalArgumentException ();
if (concurrencyLevel> MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find the power-of-two sizes
int sshift = 0;
int ssize = 1;
while (ssize <concurrencyLevel) {
++ sshift;
ssize << = 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this .segments = Segment.newArray (ssize);
if (initialCapacity> MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize <initialCapacity)
++ c;
int cap = 1;
while (cap <c)
cap << = 1;
for (int i = 0; i <this .segments.length; ++ i)
this .segments [i] = new Segment <K, V> (cap, loadFactor);
}
The number of segments will be chosen as the nearest power of two, greater than concurrencyLevel. The capacity of each segment, respectively, will be defined as the ratio of the default card capacity value rounded to the nearest greater degree two to the number of segments obtained.
It is very important to understand the following two things. An understating of concurrencyLevel leads to the fact that blocking by streams of map segments during recording is more likely. An overestimation of the indicator leads to inefficient use of memory.
How to choose concurrencyLevel?
If only one stream will change the map, and the rest will read, it is recommended to use the value 1.
It must be remembered that resize tables for storage inside a picture is an operation that requires additional time (and, often, is not performed quickly). Therefore, when creating a map, it is necessary to have some rough estimates of the statistics for the performance of possible read and write operations.
Scalability estimates
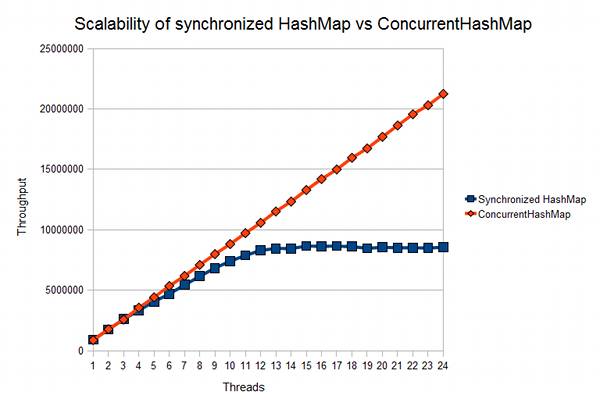
On javamex you can find an article on synchronizedMap versus ConcurrentHashMap scalability comparison:
As can be seen from the graph, between 5 and 10 million card access operations is a noticeable serious discrepancy, which determines the effectiveness of using ConcurrentHashMap in the case of a high amount of stored data and access operations to them.
Total
So, the main advantages and features of the implementation of ConcurrentHashMap:
- The card has a hashmap-like interaction interface.
- Read operations do not require locks and are performed in parallel
- Recordings can often also be performed concurrently without locks.
- During creation, the required concurrencyLevel is specified, which is determined by the read and write statistics
- Map elements have value declared as volatile.
In conclusion, I would like to say that ConcurrentHashMap should be applied correctly, with a preliminary assessment of the ratio of reading and writing to the card. It also still makes sense to use HashMap in programs where there is no multiple access from multiple threads to a stored map.
Thank you for your attention!
Useful resources for parallel collections in Java and, in particular, for the work of ConcurrentHashMap:
Source: https://habr.com/ru/post/132884/
All Articles