Speedy sync of billion files
There are several identical servers (4 nodes) on Amazon EC2 with Ubuntu. Everyone generates and stores on their disk a cache that they would like to synchronize. But a simple rsync will not work here - there are several billion files, nfs is too slow, and so on. The full list of options discussed with explanations below.
In addition, from time to time, you need to delete obsolete files on all servers at once, which so far is done manually and takes several days. The question is the quickest for such Use Case file system I plan to describe later. I will only make a reservation that for several reasons XFS was chosen.
After the test, several cluster technologies and file systems, on the advice of a senior friend, decided to use the same rsync, but in conjunction with inotify. A little searching on the Internet for such a solution, so as not to reinvent the wheel, came across csyncd, inosync and lsyncd. On Habré there was already an article about csyncd , but it’s not suitable here, because It stores a list of files in the SQLite database, which can hardly work tolerably even with a million records. Yes, and an extra link with such volumes to anything. But lsyncd turned out to be exactly what we needed.
')
UPD: As practice has shown, a tangible change and addition in the text is necessary. I decided to make only minor changes to the main part, and share new conclusions at the end of the article.
Lsyncd is a daemon that monitors changes in the local directory, aggregates them, and after a certain time rsync starts to synchronize them.
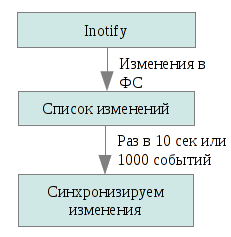
So, we cannot rsync all at once, but we can only update what has changed. The latter will be told to us by inotify , a kernel subsystem notifying applications about changes in the file system. Lsyncd monitors the changes to the local file tree, collects this information in 10 seconds (you can specify any other time) or until 1000 events are collected (depending on which event occurs first), and starts rsync to send these files to other nodes in our cluster. Rsync starts with the update parameter, that is, the file on the receiver will be replaced with the one sent only if the latter is newer. This makes it possible to avoid collisions and unnecessary operations (for example, if the same file was generated in parallel on both the sender and the receiver).
The installation process is described for Ubuntu 11.10. In other versions there may be differences.
1. Configure ssh so that you can log in from any node to another without authorization. Most likely, everyone knows how to do it, but I will describe it just in case.
Passphrase leave blank.
Next we add the contents of ~ / .ssh / id_rsa.pub to all the other nodes in the cluster in ~ / .ssh / authorized_keys. Naturally, we select the $ HOME of the user who has rights to write to the synchronization folder. It is easiest if it is / root, but it is not the best choice in terms of security.
It is also advisable to register all nodes in / etc / hosts. I called them node01, node02, node03.
Repeat on all nodes.
2. Install lsyncd
3. Config though you need to create manually, but it is quite simple. Written in Lua . An interesting comment on the reasons for choosing Lua from the author lsyncd. I have also created a separate directory for logs.
The contents of the config with comments:
It is easier to make a config once and then post it to all nodes, commenting out the extra block for each server. Comments - everything between "- [[" and "]]".
Used rsync call options:
a - archiving mode; is equivalent to -rlptgoD, that is, to copy recursively, along with symlinks and special files, while retaining the permissions, group, owner.
l - copy symlinks;
u - do not update files on the recipient if they are newer;
t, p, o, g - copy time, permissions, owner, group, respectively.
s - just in case the space appears in the file name.
S - optimize data transfer consisting of zeros.
Read more in man lsyncd or in the documentation .
4. We start the demon on all nodes:
If you left "nodaemon = true" in the config, you can see what is happening.
Next, copy / create / delete something in the directory that we specified for synchronization (I have this / raid), wait a few seconds and check the result of synchronization.
The data transfer rate reaches 300 Mbps and this has little effect on the server load (compared to the same GlusterFS, for example), and the delay in this case smoothes the peaks. Much more depends on the FS used. Here I also had to do a little research, with numbers and graphs, since the situation is quite specific and the results of existing published tests do not reflect what is required in the task.
The entire study was aimed at working with Amazon EC2, given its limitations and features, therefore, the findings mainly relate to her.
UPD: This solution performed well on tests (after which the article was written), but in combat conditions everything turned out to be completely different. Minimum production configuration - 584 thousand nested directories. And lsyncd puts inotify on each directory. Make it all at once for the whole tree is impossible. In memory, 584 thousand notifications, eat up relatively little, about 200 MB (out of 16 GB available), but this process takes 22 minutes. In principle, not scary: once launched and forgotten. But after that, with the standard configuration, lsyncd starts synchronization of all files, which in our conditions either buggy or took days. In general - not an option. 100% consistency is not required and you can do without initial synchronization. It remained to "turn off". Fortunately, the demon is written so that you can change almost all of its functions directly from the config. Also, to increase the performance, default.rsync was replaced by default.rsyncssh, and the kernel was changed to the limits of inotify. That is, the config above is suitable for most tasks, but in our particular situation the following works:
Kernel settings
Inotify has three parameters (see ls / proc / sys / fs / inotify /):
max_queued_events - the maximum number of events in the queue; default = 16384;
max_user_instances - how many inotify instances one user can start; default = 128;
max_user_watches - how many files a user can track; default = 8192.
Operating values:
So it all worked already in the production.
Thanks for attention!
In addition, from time to time, you need to delete obsolete files on all servers at once, which so far is done manually and takes several days. The question is the quickest for such Use Case file system I plan to describe later. I will only make a reservation that for several reasons XFS was chosen.
After the test, several cluster technologies and file systems, on the advice of a senior friend, decided to use the same rsync, but in conjunction with inotify. A little searching on the Internet for such a solution, so as not to reinvent the wheel, came across csyncd, inosync and lsyncd. On Habré there was already an article about csyncd , but it’s not suitable here, because It stores a list of files in the SQLite database, which can hardly work tolerably even with a million records. Yes, and an extra link with such volumes to anything. But lsyncd turned out to be exactly what we needed.
')
UPD: As practice has shown, a tangible change and addition in the text is necessary. I decided to make only minor changes to the main part, and share new conclusions at the end of the article.
Rsync + inotify = lsyncd
Lsyncd is a daemon that monitors changes in the local directory, aggregates them, and after a certain time rsync starts to synchronize them.
So, we cannot rsync all at once, but we can only update what has changed. The latter will be told to us by inotify , a kernel subsystem notifying applications about changes in the file system. Lsyncd monitors the changes to the local file tree, collects this information in 10 seconds (you can specify any other time) or until 1000 events are collected (depending on which event occurs first), and starts rsync to send these files to other nodes in our cluster. Rsync starts with the update parameter, that is, the file on the receiver will be replaced with the one sent only if the latter is newer. This makes it possible to avoid collisions and unnecessary operations (for example, if the same file was generated in parallel on both the sender and the receiver).
Implementation
The installation process is described for Ubuntu 11.10. In other versions there may be differences.
1. Configure ssh so that you can log in from any node to another without authorization. Most likely, everyone knows how to do it, but I will describe it just in case.
ssh-keygen Passphrase leave blank.
Next we add the contents of ~ / .ssh / id_rsa.pub to all the other nodes in the cluster in ~ / .ssh / authorized_keys. Naturally, we select the $ HOME of the user who has rights to write to the synchronization folder. It is easiest if it is / root, but it is not the best choice in terms of security.
It is also advisable to register all nodes in / etc / hosts. I called them node01, node02, node03.
Repeat on all nodes.
2. Install lsyncd
apt-get install lsyncd 3. Config though you need to create manually, but it is quite simple. Written in Lua . An interesting comment on the reasons for choosing Lua from the author lsyncd. I have also created a separate directory for logs.
mkdir -p /etc/lsyncd mkdir -p /var/log/lsyncd vi /etc/lsyncd/lsyncd.conf.lua The contents of the config with comments:
settings = {<br/> logfile = "/var/log/lsyncd/lsyncd.log", <br/> statusFile = "/var/log/lsyncd/lsyncd.status", <br/> nodaemon = true --<== . .<br/> } <br/> --[[<br/> sync { <br/> default.rsync, --<== rsync . -, - .<br/> source="/raid", --<== , <br/> target="node01:/raid", --<== dns- - <br/> rsyncOps={"-ausS", "--temp-dir=/mnt-is"}, --<== temp-dir .<br/> delay=10 --<== , <br/> } <br/> ]]<br/> sync { <br/> default.rsync, <br/> source="/raid", <br/> target="node02:/raid", <br/> rsyncOps={"-ausS", "--temp-dir=/mnt-is"}, <br/> delay=10 <br/> } <br/> <br/> sync { <br/> default.rsync, <br/> source="/raid", <br/> target="node03:/raid", <br/> rsyncOps={"-ausS", "--temp-dir=/mnt-is"}, <br/> delay=10<br/> } It is easier to make a config once and then post it to all nodes, commenting out the extra block for each server. Comments - everything between "- [[" and "]]".
Used rsync call options:
a - archiving mode; is equivalent to -rlptgoD, that is, to copy recursively, along with symlinks and special files, while retaining the permissions, group, owner.
u - do not update files on the recipient if they are newer;
s - just in case the space appears in the file name.
S - optimize data transfer consisting of zeros.
Read more in man lsyncd or in the documentation .
4. We start the demon on all nodes:
/etc/init.d/lsyncd start If you left "nodaemon = true" in the config, you can see what is happening.
Next, copy / create / delete something in the directory that we specified for synchronization (I have this / raid), wait a few seconds and check the result of synchronization.
The data transfer rate reaches 300 Mbps and this has little effect on the server load (compared to the same GlusterFS, for example), and the delay in this case smoothes the peaks. Much more depends on the FS used. Here I also had to do a little research, with numbers and graphs, since the situation is quite specific and the results of existing published tests do not reflect what is required in the task.
What else was considered and why it is not suitable in this case
The entire study was aimed at working with Amazon EC2, given its limitations and features, therefore, the findings mainly relate to her.
- DRBD - replication is at the block level. In case of degradation of one carrier both are killed. Limit of 2 nodes. (More is possible, but the 3rd and 4th can only be connected as slaves.)
- Ocfs2 is used either on top of DRBD (which is a good article in Habré), or you need to be able to mount one partition from several nodes. Impossible on ec2.
- Gfs2 is similar to ocfs2. I did not try, because according to the tests, this FS is slower than ocfs2, otherwise it is its analogue.
- GlusterFS - it all worked almost immediately and as it should! Simple and logical in administration. You can make a cluster of up to 255 nodes with an arbitrary value of replicas. Created a cluster partition from a pair of servers and mounted it on them but in a different directory (that is, the servers were also clients at the same time). Unfortunately on the client this cluster is mounted via FUSE, and the write speed was lower than 3 MB / s. And so, the impressions of use are very good.
- Luster - to start this thing in krenel mode you need to patch the kernel. Strangely enough, there is a package with these patches in the Ubuntu repository, but I couldn’t find any patches for it, or at least for Debian. And judging by the reviews, I realized that getting it in the deb-system is shamanism.
- Hadoop w / HDFS, Cloudera - did not try, because another solution was found (see below). But the first thing that catches the eye is written in Java, therefore there will be a lot of resources to eat, and the scale is not like that of Fesbuch or Yaha, there are only 4 nodes yet.
UPD: This solution performed well on tests (after which the article was written), but in combat conditions everything turned out to be completely different. Minimum production configuration - 584 thousand nested directories. And lsyncd puts inotify on each directory. Make it all at once for the whole tree is impossible. In memory, 584 thousand notifications, eat up relatively little, about 200 MB (out of 16 GB available), but this process takes 22 minutes. In principle, not scary: once launched and forgotten. But after that, with the standard configuration, lsyncd starts synchronization of all files, which in our conditions either buggy or took days. In general - not an option. 100% consistency is not required and you can do without initial synchronization. It remained to "turn off". Fortunately, the demon is written so that you can change almost all of its functions directly from the config. Also, to increase the performance, default.rsync was replaced by default.rsyncssh, and the kernel was changed to the limits of inotify. That is, the config above is suitable for most tasks, but in our particular situation the following works:
settings = { logfile = "/var/log/lsyncd/lsyncd.log", statusFile = "/var/log/lsyncd/lsyncd.status", statusInterval = 5, --<== } sync { default.rsyncssh, source = "/raid", host = "node02", targetdir = "/raid", rsyncOps = {"-ausS", "--temp-dir=/tmp"}, --<== delay = 3, --<== -, init = function(event) --<== . log("Normal","Skipping startup synchronization...") --<== , end } sync { default.rsyncssh, source = "/raid", host = "node03", targetdir = "/raid", rsyncOps = {"-ausS", "--temp-dir=/tmp"}, delay = 3, init = function(event) log("Normal","Skipping startup synchronization...") end } Kernel settings
Inotify has three parameters (see ls / proc / sys / fs / inotify /):
max_queued_events - the maximum number of events in the queue; default = 16384;
max_user_instances - how many inotify instances one user can start; default = 128;
max_user_watches - how many files a user can track; default = 8192.
Operating values:
echo " fs.inotify.max_user_watches = 16777216 # fs.inotify.max_queued_events = 65536 " >> /etc/sysctl.conf echo 16777216 > /proc/sys/fs/inotify/max_user_watches echo 65536 > /proc/sys/fs/inotify/max_queued_events So it all worked already in the production.
Thanks for attention!
Source: https://habr.com/ru/post/132098/
All Articles