Ferns as a pattern recognition method
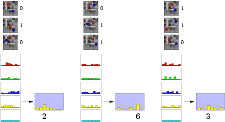 Good day!
Good day!As you know, one of the important tasks solved by image processing (in addition to dropping a couple of kg and covering skin defects on avatars) is searching and recognizing the objects we need on the scene. But this process is very complex and resource-intensive, which makes it inapplicable in real-time systems. Today we will talk, is it possible to somehow solve this problem and speed up the process of finding the desired object on the stage, with minimal losses in accuracy (or maybe without them at all). And anyway, where does the ferns?
PS
Traditionally, a lot of pictures.
Introductory
So, let's begin. The classic method of recognizing something consists of the following steps:
- Image preprocessing (alignment of brightness, selection of contours, adjusting the size and much more);
- Selection of local features (in English literature local descriptors / features, keypoints);
- We train the classifier.
After this, the actual workflow begins:
- Pre-processing of the current image;
- Extract key points;
- We give them to the classifier for recognition;
- We use the results obtained (“pink elephant in the upper corner”, “starboard man” ...) in solving an urgent task.
This approach has a very obvious problem - the allocation of local features. This is a rather slow process (especially for large images). Let's see if we can get rid of it (or, rather, replace it with something faster). It is worth noting that if the recognition rate is not critical, then this is an excellent method. For example, a young photographer can push thousands of his creations into folders automatically (“sea”, “university”, “work”, “hide from parents”). Not without errors, of course, but nonetheless. But let's talk about this approach another time.
Corner math
Let us approach formally our problem.
Suppose we have a small neighborhood around a certain point (in the English literature, image patch). We need to know which of the known classes it belongs to (picture next).

Obviously, we need a classifier, which accepts a lot of patch entries as input, yields the intended image class at the output. Patch'i and we can choose in different ways - you can stick with the mouse itself, you can take pixels with random coordinates. But the mind suggests that the easiest way to choose them with local features.

What if we take one of the simplest operations as a basis - a comparison that gives us 0 or 1 depending on the fulfillment of the condition?
We formulate as follows:
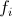 - actually, our primitive test (for example, we will compare the brightness of two pixels, although it does not matter in principle - in many respects the choice of condition is determined by the problem being solved);
- actually, our primitive test (for example, we will compare the brightness of two pixels, although it does not matter in principle - in many respects the choice of condition is determined by the problem being solved);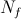 - the number of tests in the classifier;
- the number of tests in the classifier;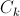 - index of a certain class of images.
- index of a certain class of images.
With such a view of things, our task can be described as follows:
for given
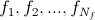 choose such a class
choose such a class  , what
, what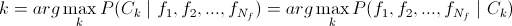 . We also take into account that the probability of choosing a particular class is evenly distributed.
. We also take into account that the probability of choosing a particular class is evenly distributed.Working with a bunch of conditions is somehow not very convenient. Therefore, we combine them into small groups, which we call fern'ami (yes, ferns). Moreover, the results of one fern does not affect the work of others. Let's write it all formally:
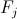 - actually, fern. Represents a set of conditions, or, in the form of a formula,
- actually, fern. Represents a set of conditions, or, in the form of a formula,  ;
;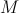 - the number of ferns, yes such that
- the number of ferns, yes such that 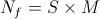
It is important to note that the number of ferns and tests carries a curious property - in fact, it determines the type of classifier:
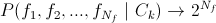 - the so-called optimal classifier. Not applicable due to the huge number of tests;
- the so-called optimal classifier. Not applicable due to the huge number of tests;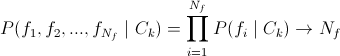 - in fact, a naive Bayes classifier ( tyk ). Not a bad decision, but does not take into account the links between the parameters, which is very important;
- in fact, a naive Bayes classifier ( tyk ). Not a bad decision, but does not take into account the links between the parameters, which is very important;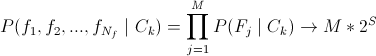 - As you guessed it, the editorial choice. Semi-naive (half-naive? In Russian literature, I did not see anything like that, who knows — tell me) a Bayesian classifier. It takes into account the relationship between the parameters, which makes it very interesting in the framework of the task.
- As you guessed it, the editorial choice. Semi-naive (half-naive? In Russian literature, I did not see anything like that, who knows — tell me) a Bayesian classifier. It takes into account the relationship between the parameters, which makes it very interesting in the framework of the task.
Practice
Fuh, math mastered, move on to the most interesting - pictures!
What we have at the moment:
- The simplest test for comparing the brightness of 2 pixels, which returns 0 and 1 as a result of the test
- A set of such tests fern. When all the checks pass, we get a binary number (10100011101 ...)
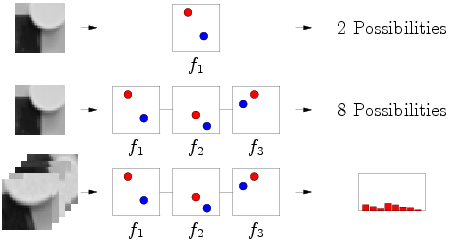 Obviously, for 1 test for 1 picture, it will give 2 variations - 0 or 1. But this is inaccurate, and there may be many classes. Then, the set of tests (fern) will give us a set of zeros and ones (in the range from 0 to
Obviously, for 1 test for 1 picture, it will give 2 variations - 0 or 1. But this is inaccurate, and there may be many classes. Then, the set of tests (fern) will give us a set of zeros and ones (in the range from 0 to 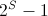 ). If we have a lot of different pictures belonging to the same class - we get the probability distribution . Yes, an important detail - the test can be absolutely any, but! We must once and for all, for all images and fern's, choose one test variant, for example, always and everywhere the blue pixel should be brighter than red. If we want the opposite - please, but then the opposite should be everywhere.
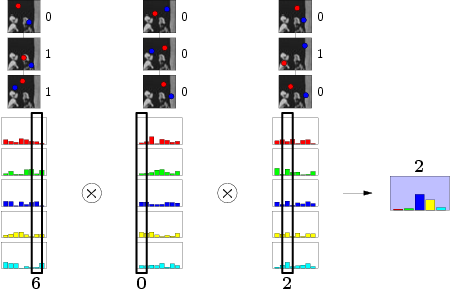
). If we have a lot of different pictures belonging to the same class - we get the probability distribution . Yes, an important detail - the test can be absolutely any, but! We must once and for all, for all images and fern's, choose one test variant, for example, always and everywhere the blue pixel should be brighter than red. If we want the opposite - please, but then the opposite should be everywhere. Take a simple situation - we have 3 tests, 3 fern'a and, for example, 5 classes of pictures. At the training stage, we feed 1 sample of class 1 to fern and they conduct a series of pixel brightness checks. As a result, each fern forms a binary number, in this case 101, 011, 100 (for the lazy, in the decimal numbering system 5, 6 and 1, respectively). These numbers allow us to increment the corresponding column in the distribution. Oh, by the way, so that no one was hurt, we initialize it as a uniform distribution of the Dirichlet probability ( tyk ).
Take a simple situation - we have 3 tests, 3 fern'a and, for example, 5 classes of pictures. At the training stage, we feed 1 sample of class 1 to fern and they conduct a series of pixel brightness checks. As a result, each fern forms a binary number, in this case 101, 011, 100 (for the lazy, in the decimal numbering system 5, 6 and 1, respectively). These numbers allow us to increment the corresponding column in the distribution. Oh, by the way, so that no one was hurt, we initialize it as a uniform distribution of the Dirichlet probability ( tyk ).We continue in the same spirit for all classes:

After all classes have been successfully mastered, you can begin to recognize. We submit to the input any image, fern'y regularly form the binary number of the column. At this stage, the values of the columns should be normalized, and then some kind of fern can pull the whole blanket over itself. Since somewhere in the beginning we postulated the independence of the results, we can safely multiply the values of the columns. And, most interestingly, the result column with the highest value will indicate the most likely class. That was what we needed, right? :)
')
results
We have achieved the desired - we got a fast and extremely simple classifier. Its main advantage is the speed of operation of a sufficiently high quality of recognition. Independence of the results also leads us to the idea of parallel processing (by fern to core and forward!). The downside is the need for a large training set (very little information is used during training, we have to compensate). It is also worth noting a certain restriction on the ferns themselves - it is desirable that they are small, even better there will be more.
Copyright
- All images are from V. Lepetit.
- Formulas are built in the online interpreter Latex
Pulp fiction at night
- Fast Keypoint Recognition using Random Ferns M. Özuysal, M. Calonder, V. Lepetit, P. Fua
- Fast Keypoint Recognition in Ten Lines of Code M. Özuysal, P. Fua, V. Lepetit
- Full version of the above material in English
Source: https://habr.com/ru/post/129685/
All Articles