Ulcers and rakes of CSV and Excel: problems and solutions
CSV is a de facto standard for communicating heterogeneous systems between each other, for transmitting and processing bulk data with a “rigid” tabular structure. In many scripting programming languages there are built-in parsing and generation tools, it is well understood by both programmers and ordinary users, and problems with the data itself are well detected, as they say, to the eye.
The history of this format has at least 30 years. But even now, in the era of indiscriminate use of XML, CSV is still used to upload and download large amounts of data. And, despite the fact that the format itself is described quite well in the RFC, everyone understands it in his own way.
In this article, I will try to summarize the existing knowledge about this format, point out typical errors, and also illustrate the problems described using the example of the import-export implementation curve in Microsoft Office 2007. I will also show how to bypass these problems (including automatic type conversion). Excel in DATETIME and NUMBER) when opening .csv.
')
Let's start with the fact that the CSV format is actually called three different text formats that differ in separator characters: CSV itself (comma-separated values are comma-separated values), TSV (tab-separated values are tab-separated values) and SCSV (semicolon separated values - the values divided by a semicolon). In life, all three can be called one CSV, the separator symbol is at best chosen during export or import, and more often it is simply “sewn up” inside the code. This creates a lot of problems in trying to figure it out.
As an illustration, let's take a seemingly trivial task: import data from a spreadsheet into Microsoft Excel into Microsoft Outlook.
In Microsoft Excel, there are tools for exporting to CSV, and in Microsoft Outlook, there are corresponding import tools. What could be simpler - made a file, “fed” to the mail program and - was it done? As if not so.
Let's create a test plate in Excel:

... and try to export it in three text formats:
What conclusion do we draw from this? .. What Microsoft calls “CSV (comma delimited)” here is actually a semicolon delimited format. The format of Microsoft is strictly Windows-1251. Therefore, if you have Unicode characters in Excel, they will appear in question marks on the output in CSV. Also the fact that line breaks are always a couple of characters, the fact that Microsoft stupidly quotes everything where it sees a semicolon. Also the fact that if you do not have Unicode characters at all, you can save on file size. Also the fact that Unicode is supported only by UTF-16, and not by UTF-8, which would be much more logical.
Now let's see how Outlook looks at it. Let's try to import these files from it, specifying the same data sources. Outlook 2007: File -> Import and Export ... -> Import from another program or file. Next, select the data format: "Values separated by commas (Windows)" and "Values separated by tabs (Windows)".
Two Microsoft products do not understand each other, they are completely unable to transfer structured data through a text file. In order for everything to work, a programmer needs to “dance with a tambourine”.
We remember that Microsoft Excel can work with text files, import data from CSV, but in version 2007 it makes it very strange. For example, if you simply open the file through the menu, it will open without any recognition of the format, just as a text file, placed entirely in the first column. In case you make a double click on CSV, Excel gets another command and imports CSV as it should, without asking any questions. The third option is to insert a file on the current sheet. In this interface, you can customize the separators, immediately see what happened. But one thing: it works badly. For example, Excel does not understand quoted line breaks inside fields.
Moreover, the same saving function in CSV, called through the interface and through the macro, works differently. The macro option does not look at the regional settings at all.
Unfortunately, there is no CSV standard, but, meanwhile, there is a so-called. memo. This is the2005 RFC 4180, which describes everything quite sensibly. In the absence of anything more, it is right to adhere to at least the RFC. But for compatibility with Excel should take into account its property.
Here is a brief summary of the RFC 4180 recommendations and my comments in square brackets:
Here is a description of the format in ABNF notation:
Also, when implementing the format, it must be remembered that since there are no pointers to the number and type of columns, since there is no requirement to place a heading, there are conventions that you should not forget:
An example of a valid CSV that can be used for tests:
exactly the same SCSV:
The first file, which is really COMMA-SEPARATED, being saved in .csv, is not perceived by Excel at all.

The second file, which, according to the SCSV logic, is recognized by Excel, and this is what comes out:

Excel errors when importing:
If you use the import functionality (Data -> From File) and call all fields as text when importing, then the following picture will be displayed:
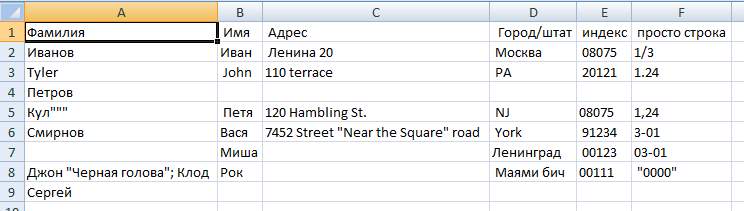
Type conversion worked, but now line feeds are not processed normally, and there is a problem with leading zeros, quotes, and extra spaces. Yes, and so users open CSV is extremely inconvenient.
There is an effective way to make Excel not type types when we don’t need it. But it will be a CSV "specifically for Excel." This is done by placing the “=” sign in front of quotes wherever there may potentially be a problem with types. At the same time remove extra spaces.
And that's what happened if we open this file in Excel:
I summarize.
To generate a CSV that could be used, the user should be given the opportunity to make the following settings before exporting:
To build a good and convenient CSV importer, you need to remember the following:
Rauf Aliyev,
Deputy Technical Director, Mail.Ru Group
The history of this format has at least 30 years. But even now, in the era of indiscriminate use of XML, CSV is still used to upload and download large amounts of data. And, despite the fact that the format itself is described quite well in the RFC, everyone understands it in his own way.
In this article, I will try to summarize the existing knowledge about this format, point out typical errors, and also illustrate the problems described using the example of the import-export implementation curve in Microsoft Office 2007. I will also show how to bypass these problems (including automatic type conversion). Excel in DATETIME and NUMBER) when opening .csv.
')
Let's start with the fact that the CSV format is actually called three different text formats that differ in separator characters: CSV itself (comma-separated values are comma-separated values), TSV (tab-separated values are tab-separated values) and SCSV (semicolon separated values - the values divided by a semicolon). In life, all three can be called one CSV, the separator symbol is at best chosen during export or import, and more often it is simply “sewn up” inside the code. This creates a lot of problems in trying to figure it out.
As an illustration, let's take a seemingly trivial task: import data from a spreadsheet into Microsoft Excel into Microsoft Outlook.
In Microsoft Excel, there are tools for exporting to CSV, and in Microsoft Outlook, there are corresponding import tools. What could be simpler - made a file, “fed” to the mail program and - was it done? As if not so.
Let's create a test plate in Excel:
... and try to export it in three text formats:
| "Unicode Text" | Encoding - UTF-16, delimiters - tabulation, line breaks - 0 × 0D, 0 × 0A, file size - 222 bytes |
| "CSV (comma delimited)" | The encoding is Windows-1251, the delimiters are a semicolon (not a comma!), In the second line the value of the phones is not quoted, despite the comma, but the value is in quotes the value “01; 02”, which is correct. Line breaks are 0 × 0D, 0 × 0A. File size - 110 bytes |
| "Text files (tab delimited)" | The encoding is Windows-1251, the delimiters are tabulation, the line breaks are 0 × 0D, 0 × 0A. The value "01; 02" is placed in quotes (without special need). File size - 110 bytes |
What conclusion do we draw from this? .. What Microsoft calls “CSV (comma delimited)” here is actually a semicolon delimited format. The format of Microsoft is strictly Windows-1251. Therefore, if you have Unicode characters in Excel, they will appear in question marks on the output in CSV. Also the fact that line breaks are always a couple of characters, the fact that Microsoft stupidly quotes everything where it sees a semicolon. Also the fact that if you do not have Unicode characters at all, you can save on file size. Also the fact that Unicode is supported only by UTF-16, and not by UTF-8, which would be much more logical.
Now let's see how Outlook looks at it. Let's try to import these files from it, specifying the same data sources. Outlook 2007: File -> Import and Export ... -> Import from another program or file. Next, select the data format: "Values separated by commas (Windows)" and "Values separated by tabs (Windows)".
| “Tab-separated values (Windows)” | We feed the tsv file to the autluk, with tab-separated values and! .. - so that you think? .. Outlook glues the fields and does not notice the tabulation. We replace tabs with commas in the file and, as we see, the fields are already parsed, well done. |
| "Comma Separated Values (Windows)" | But Autluk just understands everything correctly. Comma is a comma. Therefore, it expects a comma as a delimiter. And we have after Excel - semicolon. As a result, Autluk recognizes all wrong. |
Two Microsoft products do not understand each other, they are completely unable to transfer structured data through a text file. In order for everything to work, a programmer needs to “dance with a tambourine”.
We remember that Microsoft Excel can work with text files, import data from CSV, but in version 2007 it makes it very strange. For example, if you simply open the file through the menu, it will open without any recognition of the format, just as a text file, placed entirely in the first column. In case you make a double click on CSV, Excel gets another command and imports CSV as it should, without asking any questions. The third option is to insert a file on the current sheet. In this interface, you can customize the separators, immediately see what happened. But one thing: it works badly. For example, Excel does not understand quoted line breaks inside fields.
Moreover, the same saving function in CSV, called through the interface and through the macro, works differently. The macro option does not look at the regional settings at all.
Unfortunately, there is no CSV standard, but, meanwhile, there is a so-called. memo. This is the
Here is a brief summary of the RFC 4180 recommendations and my comments in square brackets:
- between lines - CRLF line translation [in my opinion, they shouldn’t be limited to two bytes, i.e. both CRLF (0 × 0D, 0 × 0A) and CR 0 × 0D]
- delimiters are commas, there should not be a comma at the end of the line,
- the last line of the CRLF is optional,
- The first line can be a header line (it is not marked in any way).
- spaces surrounding the comma delimiter are ignored.
- if the value contains CRLF, CR, LF (string delimiter characters), double quote or comma (field delimiter character), then quoting the value is necessary. Otherwise - valid.
- those. line breaks are allowed inside the field. But such field values must necessarily be quoted,
- if inside the quoted part there are double quotes, then specific quoting of quotes in CSV is used - their duplication.
Here is a description of the format in ABNF notation:
file = [header CRLF] record *(CRLF record) [CRLF] header = name *(COMMA name) record = field *(COMMA field) name = field field = (escaped / non-escaped) escaped = DQUOTE *(TEXTDATA / COMMA / CR / LF / 2DQUOTE) DQUOTE non-escaped = *TEXTDATA COMMA = %x2C DQUOTE = %x22 LF = %x0A CRLF = CR LF TEXTDATA = %x20-21 / %x23-2B / %x2D-7E Also, when implementing the format, it must be remembered that since there are no pointers to the number and type of columns, since there is no requirement to place a heading, there are conventions that you should not forget:
- a string value of numbers that is not enclosed in quotation marks may be perceived by the program as a numeric one, due to which information may be lost, for example, leading zeros,
- the number of values in each line may differ and it is necessary to handle this situation correctly. In some situations, you need to warn the user, in others - to create additional columns and fill them with empty values. You can decide that the number of columns is given by the title, or you can add them dynamically, as CSV is imported,
- Quoting quotes through "slash" is not according to the standard, so do not.
- Since there is no typing of fields, there is no requirement for them. The separators of the whole and fractional parts are different in different countries, and this leads to the fact that the same CSV generated by the application is “understood” in one Excel, not in the other. Because Microsoft Office is focused on the regional settings of Windows, and there could be anything. In Russia, it is indicated that the separator is a comma,
- If CSV is not opened through the “Data” menu, but directly, then Excel does not ask unnecessary questions, and it makes it seem right to it. For example, a field with a value of 1.24 is understood by default as "January 24th".
- Excel kills leading zeros and leads types even when the value is specified in quotes. It is not necessary to do so, this is a mistake. But to get around this problem of Excel, you can make a small “hack” - the value starts with an “equal” sign, and then put in quotes what needs to be transferred without changing the format.
- Excel has a special character “equal”, which in CSV is considered as an identifier of a formula. That is, if CSV meets = 2 + 3, he adds two and three and writes the result into the cell. According to the standard, he should not do this.
An example of a valid CSV that can be used for tests:
, , , /, , ,, 20, , 08075, "1/3" Tyler, John,110 terrace, PA,20121, "1.24" " """"", ,120 Hambling St., NJ,08075, "1,24" ,,"7452 Street ""Near the Square"" road", York, 91234, "3-01" ,,,, 00123, "03-01" " "" "", ",,"", ,00111, "0000" ,, exactly the same SCSV:
; ; ; /; ; ;; 20; ; 08075;"1/3" Tyler; John;110 terrace; PA; 20121;"1.24" " """""; ;120 Hambling St.; NJ;08075;"1,24" ;;"7452 Street ""Near the Square"" road"; York; 91234;"3-01" ;;;; 00123;"03-01" " "" ""; ";;""; ;00111; "0000" ;; The first file, which is really COMMA-SEPARATED, being saved in .csv, is not perceived by Excel at all.
The second file, which, according to the SCSV logic, is recognized by Excel, and this is what comes out:
Excel errors when importing:
- Learned spaces surrounding delimiters
- The last column was not really recognized at all, despite the fact that the data is in quotes. The exception is the line with "Petrov" - 1.24 was recognized there correctly.
- In the Excel index field "lowered" leading zeros.
- in the rightmost field of the last line, spaces before quotes no longer point to the special character
If you use the import functionality (Data -> From File) and call all fields as text when importing, then the following picture will be displayed:
Type conversion worked, but now line feeds are not processed normally, and there is a problem with leading zeros, quotes, and extra spaces. Yes, and so users open CSV is extremely inconvenient.
There is an effective way to make Excel not type types when we don’t need it. But it will be a CSV "specifically for Excel." This is done by placing the “=” sign in front of quotes wherever there may potentially be a problem with types. At the same time remove extra spaces.
;;;/;; ;; 20;;="08075";="1/3" Tyler; John;110 terrace;PA;="20121";="1.24" " """"";;120 Hambling St.;NJ;="08075";="1,24" ;;"7452 Street ""Near the Square"" road";York;="91234";="3-01" ;;;;="00123";="03-01" " "" "";";;""; ;="00111";="0000" ;; And that's what happened if we open this file in Excel:
I summarize.
To generate a CSV that could be used, the user should be given the opportunity to make the following settings before exporting:
- select encoding . As a rule, it is important UTF-8, UTF-16, Windows-1251, KOI8-R. Most often, there are no other options. One of them should go by default. If the data contains characters that have no analogues in the target encoding, you need to warn the user that the data will be broken;
- select a separator between fields . Options - tabulation, comma, semicolon. The default is a semicolon. Do not forget that if a separator is entered in the text, it will be very difficult to enter a tab there, it is also an unprintable character;
- select a separator between the lines (CRLF 0 × 0D 0 × 0A or CR 0 × 0D);
- select integer and fractional separator for numeric data (full stop or comma).
- choose whether to display the title bar;
- choose how to implement quoting of special characters (especially the translation of strings and quotes). In principle, you can deviate from the standard and quota them as \ n and \ ", but in this case you should not forget to quota yourself if they meet and do not forget to make it an option when exporting and importing. But compatibility will go through the forest, because any RFC-standard parser construction ..., "abc \« ", ... considers it an error;
- quite ideally - put a tick "for Excel" and take into account there those non-standards that have made Microsoft . For example, replace the values of numeric fields, "similar to the date", with the structure = "<field value>".
- to decide whether to leave the "tail" of the empty separators , if it is formed. For example, from 20 fields only the first one contains data, and the rest are empty. As a result, the line can either be placed after the first 19 separators, or not. For large amounts of data, this can save milliseconds of processing and reduce file size.
To build a good and convenient CSV importer, you need to remember the following:
- file parsing should be done on lexemes in accordance with the grammar above or use well-proven ready-made libraries (Excel works differently, because with the import problem);
- provide the user with the ability to choose the encoding (top 4 enough);
- allow the user to select a separator between fields (comma, tab, semicolon is enough);
- to allow the user to choose a separator between the lines , but in addition to the CR and CRLF options, it is necessary to provide “CR or CRLF” This is because, for example, when exporting a table with line breaks inside cells, Excel exports these line breaks as CR, and the rest of the lines are shared by CRLF. At the same time, when importing a file, it doesn’t matter to him, CR there or CRLF;
- provide the user with the ability to select a separator between the integer and fractional parts (comma or period);
- decide on the parsing method - first we read everything into memory, then we process or process line by line. In the first case, more memory may be needed, in the second case, an error in the middle will cause only partial imports, which can cause problems. Preferred the first option.
Rauf Aliyev,
Deputy Technical Director, Mail.Ru Group
Source: https://habr.com/ru/post/129476/
All Articles