Information Threatology, Vulnerability and Supervision
Initially, this text was prepared as a response to the Chamberlain commentary on the topic Informational danger , but eventually it grew to the volume of a separate post, in connection with which it is published in this format.
 I will begin with the only moment in which you can agree 100% with the author of the original post - this is the non-constructiveness of the term “security”. By creating, due to its etymology, the idea of information security as a discipline of ensuring the absence of danger to information, this term is capable of misleading so deeply that it becomes extremely difficult to get out of it in the future. A more accurate and reflective essence of this subject area would be the term used as the name of this topic. But, unfortunately, the story decreed otherwise and the term “IB” is now interpreted as widely as, for example, the term “hacker”, with all the confusion and lack of understanding of IB as such. Let's try to figure out what underlies the information security, what tasks are solved within this subject area, and how exactly this happens.
I will begin with the only moment in which you can agree 100% with the author of the original post - this is the non-constructiveness of the term “security”. By creating, due to its etymology, the idea of information security as a discipline of ensuring the absence of danger to information, this term is capable of misleading so deeply that it becomes extremely difficult to get out of it in the future. A more accurate and reflective essence of this subject area would be the term used as the name of this topic. But, unfortunately, the story decreed otherwise and the term “IB” is now interpreted as widely as, for example, the term “hacker”, with all the confusion and lack of understanding of IB as such. Let's try to figure out what underlies the information security, what tasks are solved within this subject area, and how exactly this happens.
Unfortunately, to get an answer to our question, it is necessary to slightly delve into the theory. Leaving aside so dubious the term “security” for the time being, let us consider the first component of the name of our subject area - “information”. There is no single and standardized definition of this term, so we take the most common and widely used in many disciplines:
Information is the conscious knowledge about the world, expressed in signals, messages, news, notifications, etc., which are the object of storage, transformation, transmission and use.
')
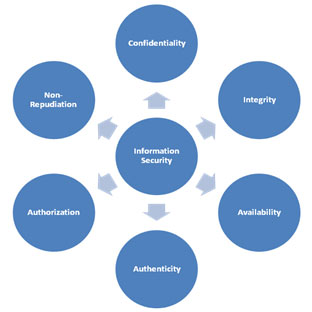
Despite the fact that information is the object of storage, transformation, transmission and use, it may well be considered in isolation from the means of carrying out these actions (media, sources, transmission channels and receivers) the totality of which is better known by the term "information system" ( Ip). It is worth noting that the term “IP”, hereinafter, is used in a wider sense than in the subject area of information technology, not limited to only technical methods for implementing such systems. Information, regardless of its system and the fourth dimension (I’m about time, if that), has a number of properties, such as cumulativeness, nonassociative and non-commutativeness, concentration, aging, scattering and other, called attributive properties. When considering information in conjunction with a specific system and taking into account time, information appears new properties - pragmatic, such as objectivity, reliability, completeness, accuracy, relevance, redundancy and security of interest to us. Pragmatic properties, due to their variability in time, it would be better to call states and security is no exception. This means that if the information is safe now, i.e. is in a state of security, it still does not mean that it will remain so in a moment. But what information can be called safe? From the pragmatism of this property, it follows that one that is stored, processed and transmitted in a system protected in the considered period of time. In other words, information - by itself, cannot be safe or insecure - this is entirely determined by the system in which it “lives”. The state of system security is a cumulative property consisting of three necessary, but not always sufficient states:
- confidentiality , - meaning that information can be obtained only by those subjects of IP who are entitled to it;
- integrity , - meaning that the information has not been subject to unauthorized modification;
- accessibility - meaning that each subject of IP, having the right to access information, has the opportunity to implement it.
These states form the so-called standard information security model "CIA". Depending on the specifics and details of the implementation of a specific IP and even a specific information flow or component, other states can also be considered. So, in the security model, on the basis of which the STRIDE threat modeling was widely used in technical information systems, three more states were introduced:
- authenticity - meaning that the subject or the IP object is exactly what he was identified or declared as;
- authorization - meaning that the range of actions of an authentic subject in relation to objects is limited;
- appealing , - meaning that the subject of IP is not able to abandon the authorship of the actions committed by him in relation to objects.
It is clear that since all the listed states are not permanent characteristics, at one time or more one or several of them may be violated. This possibility is called a threat.
In fact, the above-mentioned STRIDE is an abbreviation for the names of the threats of violation of each of the listed IP states:
- spoofing , - authenticity;
- tampering , - integrity;
- repudiation , - appealability;
- information disclosure ; - confidentiality;
- denial of service , - availability;
- elevation of privilege , - authorization.
It is obvious that not every threat is relevant for each of the IP objects. To identify current threats, their models are built. There are a lot of approaches to building threat models; the most common and formalized approach is based on data flow diagrams (DFD). A detailed consideration of this approach is the topic of a separate, rather rather big article, so we will consider it in general strokes. For a start, a high-level DFD is built for the simulated system. Traditionally, elements of such a chart are:
- process - a component of the IP, processing or transferring information;
- interactor , - external, with respect to the IP component, carrying out information exchange with any component of the IP;
- repository , - the component of the information system that stores or transfers information;
- data flow , - channel of information exchange between processes, interaktors and storages;
- boundary of trust , - passes through data streams and separates trusted IP components from untrusted.
After that, based on the relevance of threats for each type of component (these are all threats to processes; S and R for integrators; T, R, I, D for repositories and T, I, D for data streams), and also based on information about the intersection of trust boundaries by data flows; a list of actual threats is formed for the model in question. Then, each of the elements of the diagram is decomposed as if this component were a separate information system, and the data streams circulating inside it are also marked with boundaries of trust, if necessary. The received DFD again builds a list of current threats, complementing the previous one. This process is repeated recursively until the achieved level of detail of the model ceases to introduce new actual threats, or while decomposition is possible as such. As a result, a type diagram is obtained (the picture is taken from the article, the link to which is given below):
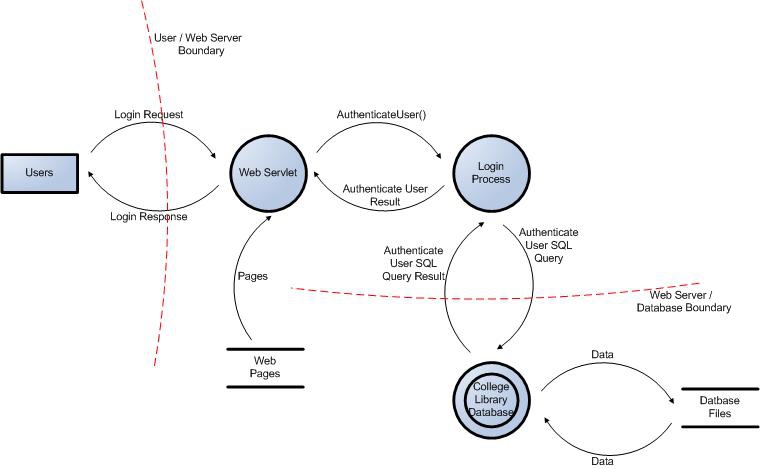
... and a very decent, even in the case of small systems, a list of information threats relevant to the IP under consideration. Please note that if a model reaches a sufficient degree of detail (and this degree is quite achievable in practice), we get a list of all the threats that are relevant to us. In more detail and with illustrations about this process, you can read, for example, here . In addition, I also recommend a very convenient tool based on Visio, which allows you to more automation of the threat modeling process using STRIDE: Threat Modeling Tool , the documentation for which contains a fairly detailed description of the process and an example of a finished model of a real system (a plug-in for integrating TMT with Visual Studio) TFS, to be precise).
However, the model we have constructed does not take into account the specifics of the implementation of IP, which almost always closes a rather large percentage of actual threats. For example, if a protected channel is used to exchange information passing through the boundary of trust between the integrator and the process, then threats T and I for the corresponding data stream are already closed. If, in addition, cryptographic tools (client certificate, digital signature) are used to confirm the authenticity of the integrator, then we can talk about closing threat S in this component. And so on and so forth. In the end, we will receive a list of all threats, countermeasures against which are not implemented in our IP. The conditions that determine the existence of such threats in the system are called vulnerabilities.
Formally, “vulnerability” is a combination of factors and conditions that contribute to the realization of a particular information threat against the system or its individual components. One vulnerability can contribute to the realization of several threats at once. It should be noted that vulnerability is not always a specific way to implement a threat, and it is not less often the case that the realization of any threat determines the totality of a number of vulnerabilities and, eliminating any one of them, we will close this threat, although we will leave system conditions conducive to its implementation until then, until we eliminate all remaining vulnerabilities. And here we are faced with an interesting problem: is it worth eliminating them if the threat is already closed? And in general, should we eliminate all the identified threats? After all, it may be that the damage from the implementation of some of them will be significantly lower than the money spent on eliminating the vulnerabilities causing them. How to understand which threats we need to close in the first place, which in the second, and which ones - not to close at all? To do this, we need to consider each of the identified vulnerabilities, estimate the probability that specific information threats will be implemented through it, estimate the damage from their implementation, it is possible to take into account several other factors of interest, such as the cost of eliminating vulnerabilities, labor costs, etc. In other words, we need to assess the risks associated with the presence of each of the vulnerabilities in our system.
Something and risk assessment techniques are like dirt, since this process is not specific to the field of information security and is rather related to the discipline of risk management. Nevertheless, two methods are traditionally used to assess the risks of technical information systems vulnerabilities. The first one is called DREAD, which is an abbreviation of the factors that this scale takes into account:
- damage potential , - damage assessment from the realization of threats through exploitation of vulnerability;
- reproducibility , - reproducibility of the way of exploiting a vulnerability;
- exploitability , - ease of exploitation;
- affected users , - an assessment of the audience of users affected by the implementation of threats through the exploitation of vulnerabilities;
- discoverability , - detectability of vulnerability.
For each of the identified vulnerabilities, the factors listed are given a score from 0 to 10 and the total risk value is calculated using the formula:
Risk_DREAD = (DAMAGE + REPRODUCIBILITY + EXPLOITABILITY + AFFECTED USERS + DISCOVERABILITY) / 5
Then comes the understanding of what vulnerabilities need to be closed first. However, DREAD is rather evaluative in nature and does not take into account many factors, for example, which particular threats the estimated vulnerability allows to realize and what is its effect on the security status of the system as a whole. For a more detailed assessment, the CVSS (Common Vulnerability Score Sytem) scale is used, with which everyone who has subscribed to at least one bugtraq distribution has met. It has been found in the descriptions of vulnerabilities vectors of the type AV: N / AC: L / Au: N / C: N / I: N / A: C ? Here, this is the CVSS. The scale is quite complex, taking into account a much larger number of factors, so it will hardly be reasonable to paint it in detail here. The specification of this scale is here , the calculator (for the formulas there are a little more complicated than in DREAD) here .
Risk assessment, despite the fact that it was attributed to tinsel in the source topic, is essentially the ultimate goal in the process of managing information security: to get an idea of the information security risks associated with the exploitation of those or other vulnerabilities in the information system and to take measures to reduce these risks to acceptable levels. No more, but no less.
Actually, this is all that concerns the subject area of information security. However, both in the initial topic and in the comments to it, there were several questions that were left unlighted here. Consider them and finish it.
If, in the course of reading this post, someone had the feeling that threat modeling is a very painstaking and routine process, then he is absolutely right. This is indeed a very low-level approach that allows you to achieve very good results, but at the cost of fairly serious effort. On the other hand, if we consider technical information systems, it is quite possible to distinguish something in common between their separate groups. Take for example web applications: how do you think how many different web applications will have common threats identified at the first iterations of building a model? Most of. Consequently, why build a new model each time, if the specificity of the IP already provides some basic set of threats that will be relevant for each web application, regardless of the details of its implementation? And it was as a result of consideration of a certain generalized model, taking into account the specifics, tools and means of implementing web applications, the classification of vulnerabilities from WASC and OWASP appeared . XSS, SQLi, LFI, CSRF, various misconfigurations, etc. - this is from there. And this is not a vulnerability. These are their classes. Vulnerabilities will be specific factors and conditions specific to a particular IP: lack of shielding of input data when generating SQL query text or generating HTML text, insufficient control of path fragments passed in user parameters, lack of control of authenticity of the HTTP request source and t .P.
But can anyone say, apart from a specific IP, which specific information threats can be implemented through the operation of XSS? Well, the main thing is clear: violation of the integrity of the document sent by the server to the user's browser, and then what? Session token confidentiality violation? Yes, it may well be. And this entails spoofig and non-appealability, at a minimum. And if an administrator session is hijacked, then privilege escalation. And if the session is not cogent, but there are conditions for CSRF? The same set of threats or another? And, by and large, the developers need it? After all, they know for sure that if there are no conditions for XSS in their code, then there will also be no threats that can be implemented through its operation, whatever these threats are. The classification of vulnerabilities in specific IP engineering subject areas is simply the next level of abstraction, allowing you to move away from painstaking threat modeling to take specific countermeasures already formulated for you, nothing more. And, of course, the less your system will comply with the generalized model, the less effective these countermeasures will be.
Standards are an even higher level of abstraction, designed not so much to ensure the state of security of your system, but to convince others that it is provided. Any standard is too general to speak about the effectiveness of the countermeasures described in it. It solves other tasks, and is subject to addition and refinement for almost every system, if you are faced with the task not only to receive a document confirming that you meet this standard, but also to have a well-protected system. As for certifications, this is a direct consequence of the main purpose of the standards. And since there is an interest of a number of large corporations and states, it is worth it as an inevitable evil, through which one must go in order to continue to be engaged in this or that business, nothing more. Standards are standards, certifications are certifications, and the provision of information security is a process, although intersecting with them, but still a little bit different.
Information security is really hard to measure. It is difficult and to shift it to the language of mathematics and algorithms (this is about the same as asking PM to algorithmize in detail the development and project management processes), because, no matter how cool, but the main factor, even in technical IS, is people. At least, because they develop them. But the point here is that all this is not the goal of this subject area. I myself do not like white-collar workers, who argue about the need to comply with standards with a smart look, call some poor writings on the theme of threats as “how I have spent all summer in the office” and try to introduce countermeasures, not understanding what threats are in terms voiced above, they really close. Although everything is on the selection - "experts on information security", yes, yes. Therefore, if someone starts to operate the limits as an assessment of IP security, or talk about the need to ensure that there are no dangers in any system, I ask you: poke a finger in his eye and tell him that it is from me, okay? Because the tasks of information security is to identify all relevant threats that cause their vulnerabilities and manage the risks associated with their operation.
Threat, Vulnerability, and Draw.
I will begin with the only moment in which you can agree 100% with the author of the original post - this is the non-constructiveness of the term “security”. By creating, due to its etymology, the idea of information security as a discipline of ensuring the absence of danger to information, this term is capable of misleading so deeply that it becomes extremely difficult to get out of it in the future. A more accurate and reflective essence of this subject area would be the term used as the name of this topic. But, unfortunately, the story decreed otherwise and the term “IB” is now interpreted as widely as, for example, the term “hacker”, with all the confusion and lack of understanding of IB as such. Let's try to figure out what underlies the information security, what tasks are solved within this subject area, and how exactly this happens.A bit of information theory
Unfortunately, to get an answer to our question, it is necessary to slightly delve into the theory. Leaving aside so dubious the term “security” for the time being, let us consider the first component of the name of our subject area - “information”. There is no single and standardized definition of this term, so we take the most common and widely used in many disciplines:
Information is the conscious knowledge about the world, expressed in signals, messages, news, notifications, etc., which are the object of storage, transformation, transmission and use.
')
Despite the fact that information is the object of storage, transformation, transmission and use, it may well be considered in isolation from the means of carrying out these actions (media, sources, transmission channels and receivers) the totality of which is better known by the term "information system" ( Ip). It is worth noting that the term “IP”, hereinafter, is used in a wider sense than in the subject area of information technology, not limited to only technical methods for implementing such systems. Information, regardless of its system and the fourth dimension (I’m about time, if that), has a number of properties, such as cumulativeness, nonassociative and non-commutativeness, concentration, aging, scattering and other, called attributive properties. When considering information in conjunction with a specific system and taking into account time, information appears new properties - pragmatic, such as objectivity, reliability, completeness, accuracy, relevance, redundancy and security of interest to us. Pragmatic properties, due to their variability in time, it would be better to call states and security is no exception. This means that if the information is safe now, i.e. is in a state of security, it still does not mean that it will remain so in a moment. But what information can be called safe? From the pragmatism of this property, it follows that one that is stored, processed and transmitted in a system protected in the considered period of time. In other words, information - by itself, cannot be safe or insecure - this is entirely determined by the system in which it “lives”. The state of system security is a cumulative property consisting of three necessary, but not always sufficient states:
- confidentiality , - meaning that information can be obtained only by those subjects of IP who are entitled to it;
- integrity , - meaning that the information has not been subject to unauthorized modification;
- accessibility - meaning that each subject of IP, having the right to access information, has the opportunity to implement it.
These states form the so-called standard information security model "CIA". Depending on the specifics and details of the implementation of a specific IP and even a specific information flow or component, other states can also be considered. So, in the security model, on the basis of which the STRIDE threat modeling was widely used in technical information systems, three more states were introduced:
- authenticity - meaning that the subject or the IP object is exactly what he was identified or declared as;
- authorization - meaning that the range of actions of an authentic subject in relation to objects is limited;
- appealing , - meaning that the subject of IP is not able to abandon the authorship of the actions committed by him in relation to objects.
It is clear that since all the listed states are not permanent characteristics, at one time or more one or several of them may be violated. This possibility is called a threat.
Threat
In fact, the above-mentioned STRIDE is an abbreviation for the names of the threats of violation of each of the listed IP states:
- spoofing , - authenticity;
- tampering , - integrity;
- repudiation , - appealability;
- information disclosure ; - confidentiality;
- denial of service , - availability;
- elevation of privilege , - authorization.
It is obvious that not every threat is relevant for each of the IP objects. To identify current threats, their models are built. There are a lot of approaches to building threat models; the most common and formalized approach is based on data flow diagrams (DFD). A detailed consideration of this approach is the topic of a separate, rather rather big article, so we will consider it in general strokes. For a start, a high-level DFD is built for the simulated system. Traditionally, elements of such a chart are:
- process - a component of the IP, processing or transferring information;
- interactor , - external, with respect to the IP component, carrying out information exchange with any component of the IP;
- repository , - the component of the information system that stores or transfers information;
- data flow , - channel of information exchange between processes, interaktors and storages;
- boundary of trust , - passes through data streams and separates trusted IP components from untrusted.
After that, based on the relevance of threats for each type of component (these are all threats to processes; S and R for integrators; T, R, I, D for repositories and T, I, D for data streams), and also based on information about the intersection of trust boundaries by data flows; a list of actual threats is formed for the model in question. Then, each of the elements of the diagram is decomposed as if this component were a separate information system, and the data streams circulating inside it are also marked with boundaries of trust, if necessary. The received DFD again builds a list of current threats, complementing the previous one. This process is repeated recursively until the achieved level of detail of the model ceases to introduce new actual threats, or while decomposition is possible as such. As a result, a type diagram is obtained (the picture is taken from the article, the link to which is given below):
... and a very decent, even in the case of small systems, a list of information threats relevant to the IP under consideration. Please note that if a model reaches a sufficient degree of detail (and this degree is quite achievable in practice), we get a list of all the threats that are relevant to us. In more detail and with illustrations about this process, you can read, for example, here . In addition, I also recommend a very convenient tool based on Visio, which allows you to more automation of the threat modeling process using STRIDE: Threat Modeling Tool , the documentation for which contains a fairly detailed description of the process and an example of a finished model of a real system (a plug-in for integrating TMT with Visual Studio) TFS, to be precise).
However, the model we have constructed does not take into account the specifics of the implementation of IP, which almost always closes a rather large percentage of actual threats. For example, if a protected channel is used to exchange information passing through the boundary of trust between the integrator and the process, then threats T and I for the corresponding data stream are already closed. If, in addition, cryptographic tools (client certificate, digital signature) are used to confirm the authenticity of the integrator, then we can talk about closing threat S in this component. And so on and so forth. In the end, we will receive a list of all threats, countermeasures against which are not implemented in our IP. The conditions that determine the existence of such threats in the system are called vulnerabilities.
Vulnerable behavior
Formally, “vulnerability” is a combination of factors and conditions that contribute to the realization of a particular information threat against the system or its individual components. One vulnerability can contribute to the realization of several threats at once. It should be noted that vulnerability is not always a specific way to implement a threat, and it is not less often the case that the realization of any threat determines the totality of a number of vulnerabilities and, eliminating any one of them, we will close this threat, although we will leave system conditions conducive to its implementation until then, until we eliminate all remaining vulnerabilities. And here we are faced with an interesting problem: is it worth eliminating them if the threat is already closed? And in general, should we eliminate all the identified threats? After all, it may be that the damage from the implementation of some of them will be significantly lower than the money spent on eliminating the vulnerabilities causing them. How to understand which threats we need to close in the first place, which in the second, and which ones - not to close at all? To do this, we need to consider each of the identified vulnerabilities, estimate the probability that specific information threats will be implemented through it, estimate the damage from their implementation, it is possible to take into account several other factors of interest, such as the cost of eliminating vulnerabilities, labor costs, etc. In other words, we need to assess the risks associated with the presence of each of the vulnerabilities in our system.
Drawing
Something and risk assessment techniques are like dirt, since this process is not specific to the field of information security and is rather related to the discipline of risk management. Nevertheless, two methods are traditionally used to assess the risks of technical information systems vulnerabilities. The first one is called DREAD, which is an abbreviation of the factors that this scale takes into account:
- damage potential , - damage assessment from the realization of threats through exploitation of vulnerability;
- reproducibility , - reproducibility of the way of exploiting a vulnerability;
- exploitability , - ease of exploitation;
- affected users , - an assessment of the audience of users affected by the implementation of threats through the exploitation of vulnerabilities;
- discoverability , - detectability of vulnerability.
For each of the identified vulnerabilities, the factors listed are given a score from 0 to 10 and the total risk value is calculated using the formula:
Risk_DREAD = (DAMAGE + REPRODUCIBILITY + EXPLOITABILITY + AFFECTED USERS + DISCOVERABILITY) / 5
Then comes the understanding of what vulnerabilities need to be closed first. However, DREAD is rather evaluative in nature and does not take into account many factors, for example, which particular threats the estimated vulnerability allows to realize and what is its effect on the security status of the system as a whole. For a more detailed assessment, the CVSS (Common Vulnerability Score Sytem) scale is used, with which everyone who has subscribed to at least one bugtraq distribution has met. It has been found in the descriptions of vulnerabilities vectors of the type AV: N / AC: L / Au: N / C: N / I: N / A: C ? Here, this is the CVSS. The scale is quite complex, taking into account a much larger number of factors, so it will hardly be reasonable to paint it in detail here. The specification of this scale is here , the calculator (for the formulas there are a little more complicated than in DREAD) here .
Risk assessment, despite the fact that it was attributed to tinsel in the source topic, is essentially the ultimate goal in the process of managing information security: to get an idea of the information security risks associated with the exploitation of those or other vulnerabilities in the information system and to take measures to reduce these risks to acceptable levels. No more, but no less.
Actually, this is all that concerns the subject area of information security. However, both in the initial topic and in the comments to it, there were several questions that were left unlighted here. Consider them and finish it.
Classifications, standards, certification
If, in the course of reading this post, someone had the feeling that threat modeling is a very painstaking and routine process, then he is absolutely right. This is indeed a very low-level approach that allows you to achieve very good results, but at the cost of fairly serious effort. On the other hand, if we consider technical information systems, it is quite possible to distinguish something in common between their separate groups. Take for example web applications: how do you think how many different web applications will have common threats identified at the first iterations of building a model? Most of. Consequently, why build a new model each time, if the specificity of the IP already provides some basic set of threats that will be relevant for each web application, regardless of the details of its implementation? And it was as a result of consideration of a certain generalized model, taking into account the specifics, tools and means of implementing web applications, the classification of vulnerabilities from WASC and OWASP appeared . XSS, SQLi, LFI, CSRF, various misconfigurations, etc. - this is from there. And this is not a vulnerability. These are their classes. Vulnerabilities will be specific factors and conditions specific to a particular IP: lack of shielding of input data when generating SQL query text or generating HTML text, insufficient control of path fragments passed in user parameters, lack of control of authenticity of the HTTP request source and t .P.
But can anyone say, apart from a specific IP, which specific information threats can be implemented through the operation of XSS? Well, the main thing is clear: violation of the integrity of the document sent by the server to the user's browser, and then what? Session token confidentiality violation? Yes, it may well be. And this entails spoofig and non-appealability, at a minimum. And if an administrator session is hijacked, then privilege escalation. And if the session is not cogent, but there are conditions for CSRF? The same set of threats or another? And, by and large, the developers need it? After all, they know for sure that if there are no conditions for XSS in their code, then there will also be no threats that can be implemented through its operation, whatever these threats are. The classification of vulnerabilities in specific IP engineering subject areas is simply the next level of abstraction, allowing you to move away from painstaking threat modeling to take specific countermeasures already formulated for you, nothing more. And, of course, the less your system will comply with the generalized model, the less effective these countermeasures will be.
Standards are an even higher level of abstraction, designed not so much to ensure the state of security of your system, but to convince others that it is provided. Any standard is too general to speak about the effectiveness of the countermeasures described in it. It solves other tasks, and is subject to addition and refinement for almost every system, if you are faced with the task not only to receive a document confirming that you meet this standard, but also to have a well-protected system. As for certifications, this is a direct consequence of the main purpose of the standards. And since there is an interest of a number of large corporations and states, it is worth it as an inevitable evil, through which one must go in order to continue to be engaged in this or that business, nothing more. Standards are standards, certifications are certifications, and the provision of information security is a process, although intersecting with them, but still a little bit different.
The author of the original post
Information security is really hard to measure. It is difficult and to shift it to the language of mathematics and algorithms (this is about the same as asking PM to algorithmize in detail the development and project management processes), because, no matter how cool, but the main factor, even in technical IS, is people. At least, because they develop them. But the point here is that all this is not the goal of this subject area. I myself do not like white-collar workers, who argue about the need to comply with standards with a smart look, call some poor writings on the theme of threats as “how I have spent all summer in the office” and try to introduce countermeasures, not understanding what threats are in terms voiced above, they really close. Although everything is on the selection - "experts on information security", yes, yes. Therefore, if someone starts to operate the limits as an assessment of IP security, or talk about the need to ensure that there are no dangers in any system, I ask you: poke a finger in his eye and tell him that it is from me, okay? Because the tasks of information security is to identify all relevant threats that cause their vulnerabilities and manage the risks associated with their operation.
Threat, Vulnerability, and Draw.
Source: https://habr.com/ru/post/129386/
All Articles