Data structures in pictures. LinkedHashMap
Hi Khabracheloveki!
After a long pause, I will try to continue to visualize the data structures in Java. In previous articles have been seen: ArrayList , LinkedList , HashMap . Today, look inside LinkedHashMap.
')
From the name you can guess that this structure is a symbiosis of linked lists and hash maps. Indeed, LinkedHashMap extends the HashMap class and implements the Map interface, but what’s so different about linked lists? Let's understand.
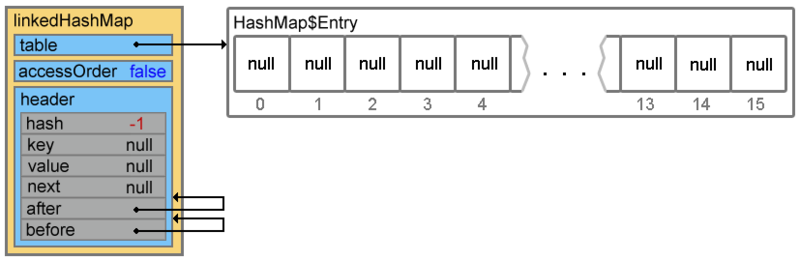
The newly created linkedHashMap object, in addition to the properties inherited from HashMap (such as table, loadFactor, threshold, size, entrySet, etc.), also contains two add. properties:
The constructors of the LinkedHashMap class are quite boring, all their work comes down to calling the parent class constructor and setting the accessOrder property. But the initialization of the header property occurs in the overridden init () method (it now becomes clear why the HashMap class constructors have a call to this function that does nothing ).
A new object is created, the properties are initialized, you can proceed to adding elements.
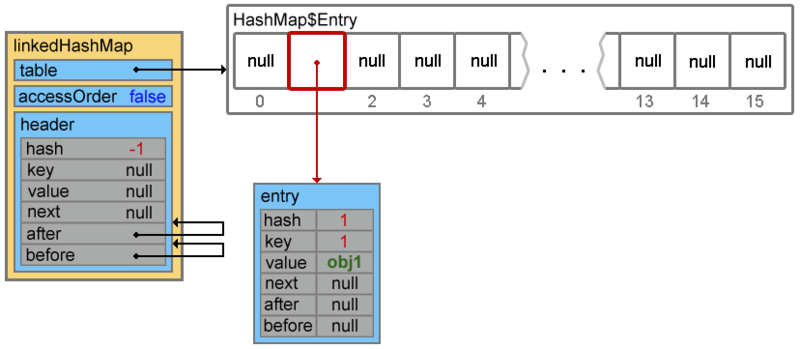
When adding an element, the createEntry method (hash, key, value, bucketIndex) is called first (by chain put () -> addEntry () -> createEntry () )
the first three lines add an element (in case of collisions, the addition will occur at the beginning of the chain, then we will see it)
fourth line overrides doubly linked list references
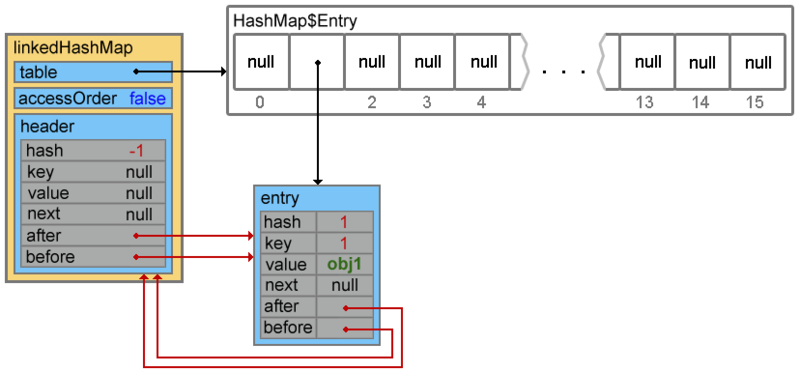
Everything that happens next in the addEntry () method either does not represent “functional interest” 1 or repeats the functionality of the parent class.
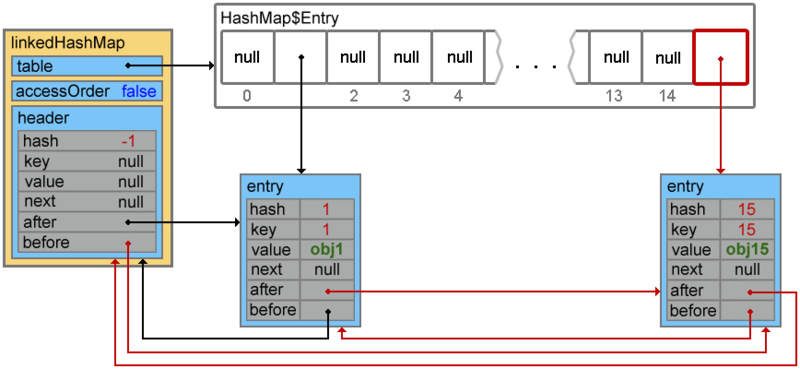
Add a couple more items.
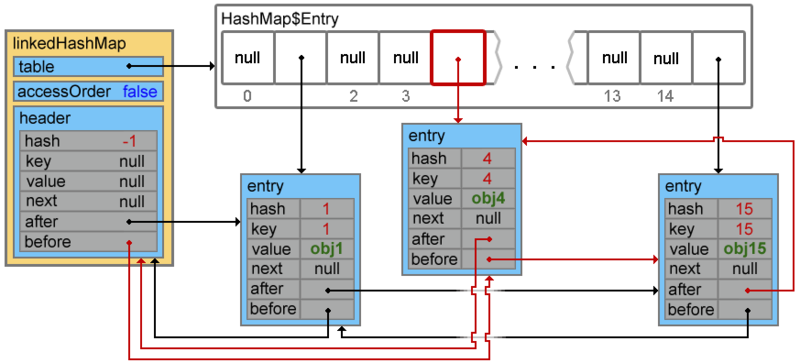
When the next element is added, a collision occurs, and elements with keys 4 and 38 form a chain
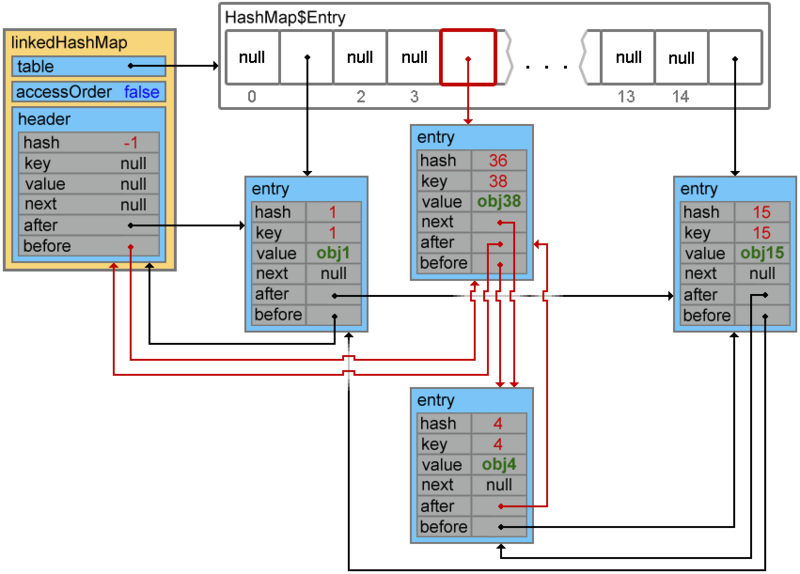
I draw your attention to the fact that in the case of re-inserting an element (an element with such a key already exists) the order of access to the elements will not change.
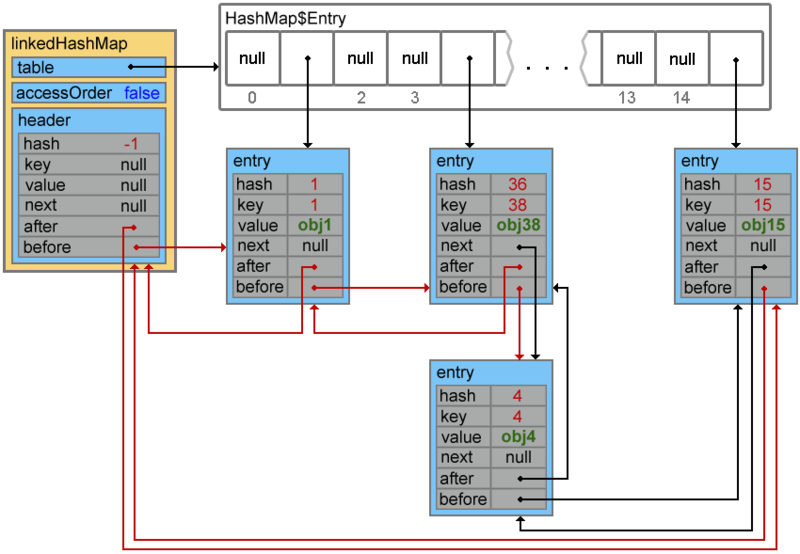
Now let's look at an example when the accessOrder property is true . In such a situation, the behavior of LinkedHashMap changes and when you call the get () and put () methods, the order of the elements will be changed - the element to be addressed will be placed at the end.
Everything is pretty trite:
Well, do not forget about fail-fast. If they have already started searching the elements, do not change the content or take care of synchronization in advance.
This structure may be slightly inferior in performance to the parent HashMap , while the execution time of the operations add (), contains (), remove () remains constant - O (1). It will take a little more memory space to store items and their connections, but this is a very small fee for additional fishes.
In general, due to the fact that all the main work is assumed by the parent class, there are few serious differences in the implementation of HashMap and LinkedHashMap . We can mention a couple of small ones:
LinkedHashMap source
Sources JDK OpenJDK & trade 6 Source Release - Build b23
Measurement tools - memory-measurer and Guava (Google Core Libraries).
1 - The call to removeEldestEntry (Map.Entry eldest) always returns false . It is assumed that this method can be redefined for any needs, for example, to implement Map- based caching structures (see ExpiringCache ). After removeEldestEntry () returns true , the oldest element will be deleted when the max is exceeded. number of items.
After a long pause, I will try to continue to visualize the data structures in Java. In previous articles have been seen: ArrayList , LinkedList , HashMap . Today, look inside LinkedHashMap.
')
From the name you can guess that this structure is a symbiosis of linked lists and hash maps. Indeed, LinkedHashMap extends the HashMap class and implements the Map interface, but what’s so different about linked lists? Let's understand.
Object creation
Map<Integer, String> linkedHashMap = new LinkedHashMap<Integer, String>(); Footprint{Objects=3, References=26, Primitives=[int x 4, float, boolean]}size: 160 bytesThe newly created linkedHashMap object, in addition to the properties inherited from HashMap (such as table, loadFactor, threshold, size, entrySet, etc.), also contains two add. properties:
- The header is the “head” of a doubly linked list. When initialized, points to itself;
- accessOrder - specifies how the elements will be accessed when using an iterator. If true , in order of last access (about this at the end of the article). If false, access is performed in the order in which the elements were inserted.
The constructors of the LinkedHashMap class are quite boring, all their work comes down to calling the parent class constructor and setting the accessOrder property. But the initialization of the header property occurs in the overridden init () method (it now becomes clear why the HashMap class constructors have a call to this function that does nothing ).
void init() { header = new Entry<K,V>(-1, null, null, null); header.before = header.after = header; } A new object is created, the properties are initialized, you can proceed to adding elements.
Adding items
linkedHashMap.put(1, "obj1"); Footprint{Objects=7, References=32, Primitives=[char x 4, int x 9, float, boolean]}size: 256 bytesWhen adding an element, the createEntry method (hash, key, value, bucketIndex) is called first (by chain put () -> addEntry () -> createEntry () )
void createEntry(int hash, K key, V value, int bucketIndex) { HashMap.Entry<K,V> old = table[bucketIndex]; Entry<K,V> e = new Entry<K,V>(hash, key, value, old); table[bucketIndex] = e; e.addBefore(header); size++; } the first three lines add an element (in case of collisions, the addition will occur at the beginning of the chain, then we will see it)
fourth line overrides doubly linked list references
Everything that happens next in the addEntry () method either does not represent “functional interest” 1 or repeats the functionality of the parent class.
Add a couple more items.
linkedHashMap.put(15, "obj15"); Footprint{Objects=11, References=38, Primitives=[float, boolean, char x 9, int x 14]}size: 352 bytes linkedHashMap.put(4, "obj4"); Footprint{Objects=11, References=38, Primitives=[float, boolean, char x 9, int x 14]}size: 448 bytesWhen the next element is added, a collision occurs, and elements with keys 4 and 38 form a chain
linkedHashMap.put(38, "obj38"); Footprint{Objects=20, References=51, Primitives=[float, boolean, char x 18, int x 24]}size: 560 bytesI draw your attention to the fact that in the case of re-inserting an element (an element with such a key already exists) the order of access to the elements will not change.
accessOrder == true
Now let's look at an example when the accessOrder property is true . In such a situation, the behavior of LinkedHashMap changes and when you call the get () and put () methods, the order of the elements will be changed - the element to be addressed will be placed at the end.
Map<Integer, String> linkedHashMap = new LinkedHashMap<Integer, String>(15, 0.75f, true) {{ put(1, "obj1"); put(15, "obj15"); put(4, "obj4"); put(38, "obj38"); }}; // {1=obj1, 15=obj15, 4=obj4, 38=obj38} linkedHashMap.get(1); // or linkedHashMap.put(1, "Object1"); // {15=obj15, 4=obj4, 38=obj38, 1=obj1} Iterators
Everything is pretty trite:
// 1. Iterator<Entry<Integer, String>> itr1 = linkedHashMap.entrySet().iterator(); while (itr1.hasNext()) { Entry<Integer, String> entry = itr1.next(); System.out.println(entry.getKey() + " = " + entry.getValue()); } // 2. Iterator<Integer> itr2 = linkedHashMap.keySet().iterator(); while(itr2.hasNext()) System.out.println(itr2.next()); // 3. Iterator<String> itr3 = linkedHashMap.values().iterator(); while (itr3.hasNext()) System.out.println(itr3.next()); Well, do not forget about fail-fast. If they have already started searching the elements, do not change the content or take care of synchronization in advance.
Instead of totals
This structure may be slightly inferior in performance to the parent HashMap , while the execution time of the operations add (), contains (), remove () remains constant - O (1). It will take a little more memory space to store items and their connections, but this is a very small fee for additional fishes.
In general, due to the fact that all the main work is assumed by the parent class, there are few serious differences in the implementation of HashMap and LinkedHashMap . We can mention a couple of small ones:
- The transfer () and containsValue () methods are slightly simpler because of the presence of a bidirectional connection between the elements;
- The LinkedHashMap.Entry class implements the recordRemoval () and recordAccess () methods (the one that puts the element at the end when accessOrder = true ). In HashMap, both of these methods are empty.
Links
LinkedHashMap source
Sources JDK OpenJDK & trade 6 Source Release - Build b23
Measurement tools - memory-measurer and Guava (Google Core Libraries).
1 - The call to removeEldestEntry (Map.Entry eldest) always returns false . It is assumed that this method can be redefined for any needs, for example, to implement Map- based caching structures (see ExpiringCache ). After removeEldestEntry () returns true , the oldest element will be deleted when the max is exceeded. number of items.
Source: https://habr.com/ru/post/129037/
All Articles