How to effectively import big data
Sometimes we need to import very large data into the database, which sometimes reaches several tens of gigabytes. We carry out regular backups, hot backups, in important services we use replication and High Availability. Most often, users rely on the built-in DBMS function, use it without any changes, wait until the import process is over, and sometimes they do not wait at all.
In this blog, I want to talk about different ways of importing data into the CUBRID DBMS , specifying which one is more efficient and why. Some of these recommendations can also be applied in other database management systems.
So, in CUBRID data import can be made using the following tools.
First, I will give the results of a small test so that you can see the big picture and understand why some of the above solutions work faster than others. Then I will talk about recommendations that will help you to significantly speed up the process of importing data.
For each of the methods we will test on a small amount of data (100,000 records) in order to understand which direction each of them is moving. The test will be conducted on Windows 7 x86 with CUBRID 8.4.0 installed. Thus, we will use:
The following configurations will also be present.
CSQL is a tool for interpreting and running SQL queries on the command line. Compared to CUBRID Manager, CSQL is much easier and faster. It can work in two modes. The first is the offline mode , and the second is the Client-Server mode .
More details about these modes can be found in the manual .
')
It's time to create a base for our test. We can do this on the command line by running the
Then we need to connect to this database using CSQL and create the necessary tables.
Since we have prepared everything, it remains to import all the data that is in the dbtest.sql file.
To run CSQL offline and read all data from a file, enter the following command.
To run CSQL in Client-server mode and read all data from a file, enter the following command.
For this we will use the same information about the database and its scheme. Then run the following script to enter 100,000 entries.
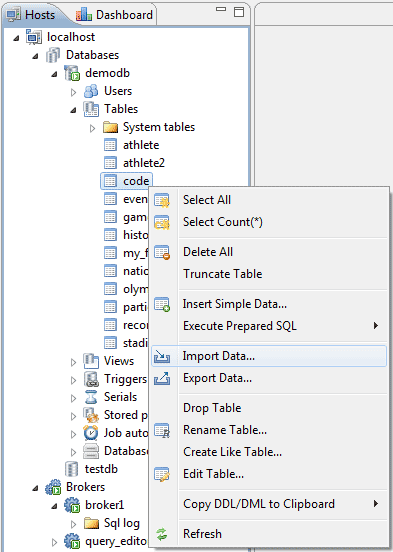
Here we will import data from the same file that we created in the CSQL test. Using the Import Data function (see screenshot below), we import all the data.
The following test results are shown in seconds.

As seen in the above graph, CSQL offline is the fastest way to import data into CUBRID. The reason for this is that it directly works with database files, bypassing server processes. In this mode, CSQL behaves like a server, not like a client connected to a server. Therefore, this tool imports data the fastest.
However, there are times when we cannot use CSQL offline, since in this mode more than one user cannot be connected. This means that CSQL should be the only application that works with the database at that time. And this in turn means that the database should be disabled. If the database is running, it means that another user (host) is using it. In this case, an attempt to connect to the database using CSQL offline will generate the following error.
In such cases, you need to either make sure that no one else is connected to the database by completely shutting it down, or use other methods of importing data. To disable the database on the command line, enter the
This is one of the most important recommendations for developers who plan to import large amounts of data.
Do not create any indexes before you finish importing all the data. This applies to indices such as:
Otherwise, every data entry (
There are two types of logging in CUBRID:
Client-side logging refers to the
When logging is enabled on the client side, every SQL statement processed by a CAS (CUBRID Application Server) will be saved in the DBMS logs. Accordingly, it will increase the total time of import. Therefore, if you do not need the logs of the entire import process (as, for example, in the High Availability mode), then turn it off for a while until the import is complete.
There are several ways to disable logging. Below I will show how to do this in the CUBRID Manager and in the command line.
CM example
To disable logging (

In the modal window, specify the value of the

To finally apply the changes, you must restart the Broker. Also, right-click on the Broker and select Broker Off to turn off, and then Broker On to launch the Broker. Now you can run the import.
Command line example
In a text editor, open cubrid_broker.conf , the broker configuration file, which is located in the conf directory where you installed CUBRID. In this file you can change the values of all Broker parameters, including
Then restart the Broker in the command line using the
Server-side logging refers to the media_failure_support parameter of the CUBRID Server itself, which determines the need to preserve archive logs in case of failure of storage devices. If the value of this parameter is yes , which is the default value, then all active logs will be copied to archive logs, when active logs are filled and the transaction is still active. If media_failure_support = no , then all archive logs created after the active logs have been filled will be automatically deleted. It is necessary to replace that any archive logs will be immediately deleted if the value of this parameter is changed to no .
Thus, by setting the value media_failure_support = no , you can reduce the total time to import data. To change this parameter, right-click on the host and select its properties (Properties).

In the modal window, specify the value of the

To apply all changes, restart the server.
If you decide to work with CUBRID Manager to import data, be sure to specify the number of threads, as well as the number of transactions in one commit.
Streams will allow the CM to use multiple parallel connections to make INSERT requests. To determine the number of threads, specify their number in the Thread count . However, you must also remember that too much will not lead to anything good. It all depends on the capabilities of your hardware. Usually we recommend from 5 to 10 streams.

Also, the import time depends on the number of transactions in one commit cycle . This value determines how often the entered data is recorded. Frequent commit transactions will result in poor performance. But on the other hand, a rare fix may require a lot of RAM. Therefore, again, it depends on the configurations of iron.
data_buffer_size is one of the important parameters in optimizing the operation of the entire CUBRID server. It determines the amount of data pages that need to be stored in the server's CUBRID cache. The larger the data_buffer_size value, the more data pages can be stored in the server's buffer, which can significantly reduce the number of I / O operations, which means that the overall performance.
But if the value of this parameter is too large, the buffer pool between the operating system and the server can be swapped due to lack of sufficient memory, and if a swap disk is not created, then the database (note, not the server, but the database itself) will not start, because it simply simply does not have enough memory. Therefore, based on the physical potential of iron, it is recommended to adjust the value of the data_buffer_size parameter equal to about two thirds of the size of system memory. By default, data_buffer_size = 512M (megabytes).
insert_execution_mode is a very useful parameter that allows you to run INSERT requests on the server side rather than on the client side . This is useful when there is very little memory available on the client side, or you need a dirty read before entering data for periodic backups.
The parameter can take 7 values (see Database Server Parameters for details). The default value is insert_execution_mode = 1 , which means that all INSERT INTO ... SELECT ... queries of the view will be launched on the server side. Since we do not use this query structure when importing data, we need to change the value to 2 , which will allow us to run all queries in the form of INSERT INTO ... VALUES ... on the server side (see the figure below).

So, to reduce the total import time and increase the performance of the CUBRID server, follow these tips:
Did I miss something? Write in the comments about your experience and how often you import data.
In this blog, I want to talk about different ways of importing data into the CUBRID DBMS , specifying which one is more efficient and why. Some of these recommendations can also be applied in other database management systems.
So, in CUBRID data import can be made using the following tools.
- The easiest way is to use the CUBRID Manager.
- You can also use PHP, Java and other drivers.
- Otherwise, you can use the CSQL , CUBRID SQL interpreter in the command line.
- You can also configure replication or High Availability, but this is beyond the scope of this article.
First, I will give the results of a small test so that you can see the big picture and understand why some of the above solutions work faster than others. Then I will talk about recommendations that will help you to significantly speed up the process of importing data.
About the test
For each of the methods we will test on a small amount of data (100,000 records) in order to understand which direction each of them is moving. The test will be conducted on Windows 7 x86 with CUBRID 8.4.0 installed. Thus, we will use:
- CSQL
-S offline mode (stand-alone mode)
-C client-server mode (Client-server mode) - CUBRID Manager
- PHP API
The following configurations will also be present.
- Commitment of transactions will be every 5000 times (Commit cycle)
- We will measure only the launch time of INSERT queries, so the database and the necessary tables will be created in advance.
Test script
Running CSQL on the command line (-S and -C modes)
CSQL is a tool for interpreting and running SQL queries on the command line. Compared to CUBRID Manager, CSQL is much easier and faster. It can work in two modes. The first is the offline mode , and the second is the Client-Server mode .
- In offline mode, CSQL works directly with database files and processes all requests and server commands. In other words, requests can be processed bypassing the server. However, due to the fact that only one active user is allowed offline, it can work only for administrative tasks.
- In Client mode, the CSQL server works as a client, and as a regular client, it sends all requests for processing to the server.
More details about these modes can be found in the manual .
')
It's time to create a base for our test. We can do this on the command line by running the
cubrid createdb dbtest .Then we need to connect to this database using CSQL and create the necessary tables.
$> csql demodb
CUBRID SQL Interpreter
Type `;help' for help messages.
csql> CREATE TABLE test1(a int, b TIMESTAMP, c int AUTO_INCREMENT)
csql> ;ru
Current transaction has been committed.
1 command(s) successfully processed.
csql> ;ex- In the CSQL command ; ru means “run the entered queries” (run).
- The command ; ex - exit (exit). About all possible commands you can find here .
Since we have prepared everything, it remains to import all the data that is in the dbtest.sql file.
INSERT INTO test1 VALUES (0 , SYS_TIMESTAMP, NULL);
INSERT INTO test2 VALUES (1 , SYS_TIMESTAMP, NULL);
……………………
INSERT INTO test1 VALUES (99998 , SYS_TIMESTAMP, NULL);
INSERT INTO test1 VALUES (99999 , SYS_TIMESTAMP, NULL);
To run CSQL offline and read all data from a file, enter the following command.
$> csql -u dba -p 1111 –S -i dbtest1.sql dbtestTo run CSQL in Client-server mode and read all data from a file, enter the following command.
$> csql -u dba -p 1111 –C -i dbtest1.sql dbtestImport to PHP
For this we will use the same information about the database and its scheme. Then run the following script to enter 100,000 entries.
$ host_ip = "localhost";
$ host_port = 33000;
$ db_name = "dbtest";
$ userId = "dba";
$ password = "1111";
$ cubrid_con = @cubrid_connect ($ host_ip, $ host_port, $ db_name, $ userId, $ password);
if ($ cubrid_con)
{
$ sql = "insert into". $ db_name. "(a, b) values (?, SYS_TIMESTAMP)";
$ reg = cubrid_prepare ($ cubrid_con, $ sql, CUBRID_INCLUDE_OID);
// Insert 100,000 records in the loop.
for ($ i = 0; $ i <100000; ++ $ i)
{
$ res = cubrid_bind ($ reg, 1, $ i);
$ res = cubrid_execute ($ reg);
// Commit once in 5,000 times (commit cycle).
if (($ i + 1)% 5000 == 0)
{
cubrid_commit ($ cubrid_con);
echo $ i, "
";
}
}
} Import data into CUBRID Manager
Here we will import data from the same file that we created in the CSQL test. Using the Import Data function (see screenshot below), we import all the data.
Test results
The following test results are shown in seconds.
| 50,000 records | 100,000 records | 300,000 records | |
|---|---|---|---|
| csql-s | five | ten | 29 |
| csql-c | 111 | 224 | 599 |
| Php | 68 | 136 | 413 |
| CM | 17 | 33 | 96 |
Conclusion and recommendations
Use CSQL offline
As seen in the above graph, CSQL offline is the fastest way to import data into CUBRID. The reason for this is that it directly works with database files, bypassing server processes. In this mode, CSQL behaves like a server, not like a client connected to a server. Therefore, this tool imports data the fastest.
However, there are times when we cannot use CSQL offline, since in this mode more than one user cannot be connected. This means that CSQL should be the only application that works with the database at that time. And this in turn means that the database should be disabled. If the database is running, it means that another user (host) is using it. In this case, an attempt to connect to the database using CSQL offline will generate the following error.
$> csql -S demodb
ERROR: Unable to mount disk volume "C:CUBRIDdatabasesdemodbdemodb_lgat".
The database "C:CUBRIDDATABA~1demodbdemodb", to which the disk volume belongs,
is in use by user USER-PC$ on process 3096 of host user-PC since Thu Sep 22 11:04:01 2011.In such cases, you need to either make sure that no one else is connected to the database by completely shutting it down, or use other methods of importing data. To disable the database on the command line, enter the
cubrid server stop dbtest1 .Create any CONSTRAINT after importing data
This is one of the most important recommendations for developers who plan to import large amounts of data.
Do not create any indexes before you finish importing all the data. This applies to indices such as:
INDEX (regular index), UNIQUE (unique index), REVERSE INDEX (reverse index), REVERSE UNIQUE (reverse unique index) and even PRIMARY KEY (the primary key will automatically create a regular index).Otherwise, every data entry (
INSERT ) during the import process will entail mandatory indexing, which will increase the total import time. Therefore, follow these instructions:- Create a table.
- Add all the required columns and specify their data types, but do not specify any restrictions, even the primary key .
- Import all the data.
- And only then create all the necessary indexes and primary keys.
Disable logging during import.
There are two types of logging in CUBRID:
- Client side logging
- Server side logging
Client side logging
Client-side logging refers to the
SQL_LOG parameter in the CUBRID Broker . The default value is SQL_LOG = ON .When logging is enabled on the client side, every SQL statement processed by a CAS (CUBRID Application Server) will be saved in the DBMS logs. Accordingly, it will increase the total time of import. Therefore, if you do not need the logs of the entire import process (as, for example, in the High Availability mode), then turn it off for a while until the import is complete.
There are several ways to disable logging. Below I will show how to do this in the CUBRID Manager and in the command line.
CM example
To disable logging (
SQL_LOG = OFF ), right-click on the Broker and select Properties .In the modal window, specify the value of the
SQL_LOG parameter as OFF . Then save the changes by clicking on OK .To finally apply the changes, you must restart the Broker. Also, right-click on the Broker and select Broker Off to turn off, and then Broker On to launch the Broker. Now you can run the import.
Command line example
In a text editor, open cubrid_broker.conf , the broker configuration file, which is located in the conf directory where you installed CUBRID. In this file you can change the values of all Broker parameters, including
SQL_LOG . See the code cut below.[broker]
...
SQL_LOG =OFF
...Then restart the Broker in the command line using the
cubrid broker restart command.Server side logging
Server-side logging refers to the media_failure_support parameter of the CUBRID Server itself, which determines the need to preserve archive logs in case of failure of storage devices. If the value of this parameter is yes , which is the default value, then all active logs will be copied to archive logs, when active logs are filled and the transaction is still active. If media_failure_support = no , then all archive logs created after the active logs have been filled will be automatically deleted. It is necessary to replace that any archive logs will be immediately deleted if the value of this parameter is changed to no .
Thus, by setting the value media_failure_support = no , you can reduce the total time to import data. To change this parameter, right-click on the host and select its properties (Properties).
In the modal window, specify the value of the
media_failure_support parameter as no . Then save the changes by clicking on OK .To apply all changes, restart the server.
Specify the number of threads and transaction commits.
If you decide to work with CUBRID Manager to import data, be sure to specify the number of threads, as well as the number of transactions in one commit.
Streams will allow the CM to use multiple parallel connections to make INSERT requests. To determine the number of threads, specify their number in the Thread count . However, you must also remember that too much will not lead to anything good. It all depends on the capabilities of your hardware. Usually we recommend from 5 to 10 streams.
Also, the import time depends on the number of transactions in one commit cycle . This value determines how often the entered data is recorded. Frequent commit transactions will result in poor performance. But on the other hand, a rare fix may require a lot of RAM. Therefore, again, it depends on the configurations of iron.
Use data_buffer_size
data_buffer_size is one of the important parameters in optimizing the operation of the entire CUBRID server. It determines the amount of data pages that need to be stored in the server's CUBRID cache. The larger the data_buffer_size value, the more data pages can be stored in the server's buffer, which can significantly reduce the number of I / O operations, which means that the overall performance.
But if the value of this parameter is too large, the buffer pool between the operating system and the server can be swapped due to lack of sufficient memory, and if a swap disk is not created, then the database (note, not the server, but the database itself) will not start, because it simply simply does not have enough memory. Therefore, based on the physical potential of iron, it is recommended to adjust the value of the data_buffer_size parameter equal to about two thirds of the size of system memory. By default, data_buffer_size = 512M (megabytes).
Use insert_execution_mode
insert_execution_mode is a very useful parameter that allows you to run INSERT requests on the server side rather than on the client side . This is useful when there is very little memory available on the client side, or you need a dirty read before entering data for periodic backups.
The parameter can take 7 values (see Database Server Parameters for details). The default value is insert_execution_mode = 1 , which means that all INSERT INTO ... SELECT ... queries of the view will be launched on the server side. Since we do not use this query structure when importing data, we need to change the value to 2 , which will allow us to run all queries in the form of INSERT INTO ... VALUES ... on the server side (see the figure below).
So, to reduce the total import time and increase the performance of the CUBRID server, follow these tips:
- Use CSQL offline
- Create any CONSTRAINT after importing data
- Disable logging during import.
- Specify the number of threads and transaction commits.
- Use data_buffer_size
- Use insert_execution_mode
Did I miss something? Write in the comments about your experience and how often you import data.
Source: https://habr.com/ru/post/128847/
All Articles