Data structures in pictures. Hashmap
Greetings to you!
I keep trying to visualize data structures in Java. In previous episodes, we’ve already reviewed ArrayList and LinkedList , but today we’ll look at HashMap.
')
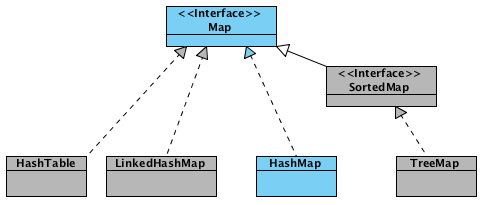
HashMap - is based on hash tables, implements the Map interface (which means storing data in the form of key / value pairs). Keys and values can be of any type, including null. This implementation does not guarantee the order of the elements over time. Collision resolution is performed using the chaining method .
The newly appeared hashmap object contains a number of properties:

You can specify your capacity and load factor using the HashMap (capacity) and HashMap (capacity, loadFactor) constructors . The maximum capacity you can set is half the maximum int value (1073741824).
When adding an item, the sequence of steps is as follows:
To demonstrate how the HashMap is populated, let's add some more elements.
As mentioned above, if you added null as a key when adding an item, the actions will be different. The putForNullKey (value) method will be called, inside which there is no call to the hash () and indexFor () methods (because all items with null keys are always placed in table [0] ), but there are such actions:
Now consider the case when a collision occurs when adding an element.
When the table [] array is filled to the limit value, its size is doubled and the elements are redistributed. As you can see for yourself, there is nothing difficult in the resize (capacity) and transfer (newTable) methods .
The transfer () method enumerates all elements of the current storage, recalculates their indices (taking into account the new size) and redistributes the elements over the new array.
If we add, say, 15 more elements to the original hashmap , then the size will be increased and the distribution of elements will change.

HashMap has the same “problem” as ArrayList - when deleting elements, the size of the array table [] does not decrease. And if the trimToSize () method is provided in the ArrayList, then there are no such methods in the HashMap (although, as one colleague said, “ Or maybe it is not necessary? ”).
A small test to demonstrate what is written above. The source object is 496 bytes. Add, for example, 150 elements.
Now remove the same 150 items, and measure again.
As you can see, the size did not even come close to the original. If there is a desire / need to correct the situation, you can, for example, use the HashMap (Map) designer.
HashMap has built-in iterators such that you can get a list of all keySet () keys, all values () values, or all key / value entrySet () pairs. Below are some options for iterating over elements:
It is worth remembering that if during the work of the HashMap iterator was changed (without using the iterator’s own methods), then the result of iterating over the elements will be unpredictable.
- Adding an element is performed in O (1) time, because new elements are inserted at the beginning of the chain;
- The operations of obtaining and deleting an element can be performed in O (1) time, if the hash function evenly distributes the elements and there are no collisions. The mean running time will be Θ (1 + α), where α is the load factor. In the worst case, the execution time can be Θ (n) (all elements in one chain);
- Keys and values can be of any type, including null. For storage of primitive types, the corresponding wrapper classes are used;
- Not synchronized.
HashMap source
HashMap source from JDK7
Sources JDK OpenJDK & trade 6 Source Release - Build b23
Measurement tools - memory-measurer and Guava (Google Core Libraries).
I keep trying to visualize data structures in Java. In previous episodes, we’ve already reviewed ArrayList and LinkedList , but today we’ll look at HashMap.
')
HashMap - is based on hash tables, implements the Map interface (which means storing data in the form of key / value pairs). Keys and values can be of any type, including null. This implementation does not guarantee the order of the elements over time. Collision resolution is performed using the chaining method .
Object creation
Map<String, String> hashmap = new HashMap<String, String>(); Footprint{Objects=2, References=20, Primitives=[int x 3, float]}
Object size: 120 bytesThe newly appeared hashmap object contains a number of properties:
- table - An array of type Entry [] , which is a repository of references to lists (chains) of values;
- loadFactor - load factor. The default value of 0.75 is a good compromise between the access time and the amount of stored data;
- threshold - The limit on the number of elements that, when reached, will double the size of the hash table. Calculated by the formula (capacity * loadFactor) ;
- size - The number of HashMap elements;
// // capacity - 16 table = new Entry[capacity]; You can specify your capacity and load factor using the HashMap (capacity) and HashMap (capacity, loadFactor) constructors . The maximum capacity you can set is half the maximum int value (1073741824).
Adding items
hashmap.put("0", "zero"); Footprint{Objects=7, References=25, Primitives=[int x 10, char x 5, float]}
Object size: 232 bytesWhen adding an item, the sequence of steps is as follows:
- First, the key is checked for null equality. If this check returns true, the putForNullKey (value) method will be called ( we will consider the option with adding a null key a little later ).
- Next, a hash is generated based on the key. For generation, the hash (hashCode) method is used, to which key.hashCode () is passed .
static int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
A comment from the source explains which results to expect - the hash (key) method ensures that the resulting hash codes will have only a limited number of collisions (approximately 8, with the default load factor).
In my case, for the key with the value “0” the hashCode () method returned the value 48, as a result:h ^ (h >>> 20) ^ (h >>> 12) = 48 h ^ (h >>> 7) ^ (h >>> 4) = 51 - Using the indexFor (hash, tableLength) method , the position in the array where the element will be placed is determined.
static int indexFor(int h, int length) { return h & (length - 1); }
With the hash value of 51 and the size of table 16 , we get the index in the array:h & (length - 1) = 3 - Now, knowing the index in the array, we get a list (chain) of elements attached to this cell. The hash and key of the new item are compared in turn with the hashes and keys of the items from the list and, if these parameters match, the value of the item is overwritten.
if (e.hash == hash && (e.key == key || key.equals(e.key))) { V oldValue = e.value; e.value = value; return oldValue; } - If the previous step did not reveal matches, the addEntry method (hash, key, value, index) will be called to add a new item.
void addEntry(int hash, K key, V value, int index) { Entry<K, V> e = table[index]; table[index] = new Entry<K, V>(hash, key, value, e); ... }
To demonstrate how the HashMap is populated, let's add some more elements.
hashmap.put("key", "one"); Footprint{Objects=12, References=30, Primitives=[int x 17, char x 11, float]}
Object size: 352 bytes- Skipped, key is not null
- '' key ''. hashCode () = 106079
h ^ (h >>> 20) ^ (h >>> 12) = 106054 h ^ (h >>> 7) ^ (h >>> 4) = 99486 - Determining the position in the array
h & (length - 1) = 14 - No items found
- Add item

hashmap.put(null, null); Footprint{Objects=13, References=33, Primitives=[int x 18, char x 11, float]}
Object size: 376 bytesAs mentioned above, if you added null as a key when adding an item, the actions will be different. The putForNullKey (value) method will be called, inside which there is no call to the hash () and indexFor () methods (because all items with null keys are always placed in table [0] ), but there are such actions:
- All chaining elements bound to table [0] are alternately scanned for the element with the null key. If such an element in the chain exists, its value is overwritten.
- If the element with the null key was not found, the already familiar addEntry () method will be called.
addEntry(0, null, value, 0);
hashmap.put("idx", "two"); Footprint{Objects=18, References=38, Primitives=[int x 25, char x 17, float]}
Object size: 496 bytesNow consider the case when a collision occurs when adding an element.
- Skipped, key is not null
- '' idx ''. hashCode () = 104125
h ^ (h >>> 20) ^ (h >>> 12) = 104100 h ^ (h >>> 7) ^ (h >>> 4) = 101603 - Determining the position in the array
h & (length - 1) = 3 - No items found
- Add item
// table[3] ["0", "zero"] Entry<K, V> e = table[index]; // table[index] = new Entry<K, V>(hash, key, value, e);
Resize and Transfer
When the table [] array is filled to the limit value, its size is doubled and the elements are redistributed. As you can see for yourself, there is nothing difficult in the resize (capacity) and transfer (newTable) methods .
void resize(int newCapacity) { if (table.length == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor); } The transfer () method enumerates all elements of the current storage, recalculates their indices (taking into account the new size) and redistributes the elements over the new array.
If we add, say, 15 more elements to the original hashmap , then the size will be increased and the distribution of elements will change.
Deleting items
HashMap has the same “problem” as ArrayList - when deleting elements, the size of the array table [] does not decrease. And if the trimToSize () method is provided in the ArrayList, then there are no such methods in the HashMap (although, as one colleague said, “ Or maybe it is not necessary? ”).
A small test to demonstrate what is written above. The source object is 496 bytes. Add, for example, 150 elements.
Footprint{Objects=768, References=1028, Primitives=[int x 1075, char x 2201, float]}
Object size: 21064 bytesNow remove the same 150 items, and measure again.
Footprint{Objects=18, References=278, Primitives=[int x 25, char x 17, float]}
Object size: 1456 bytesAs you can see, the size did not even come close to the original. If there is a desire / need to correct the situation, you can, for example, use the HashMap (Map) designer.
hashmap = new HashMap<String, String>(hashmap); Footprint{Objects=18, References=38, Primitives=[int x 25, char x 17, float]}
Object size: 496 bytesIterators
HashMap has built-in iterators such that you can get a list of all keySet () keys, all values () values, or all key / value entrySet () pairs. Below are some options for iterating over elements:
// 1. for (Map.Entry<String, String> entry: hashmap.entrySet()) System.out.println(entry.getKey() + " = " + entry.getValue()); // 2. for (String key: hashmap.keySet()) System.out.println(hashmap.get(key)); // 3. Iterator<Map.Entry<String, String>> itr = hashmap.entrySet().iterator(); while (itr.hasNext()) System.out.println(itr.next()); It is worth remembering that if during the work of the HashMap iterator was changed (without using the iterator’s own methods), then the result of iterating over the elements will be unpredictable.
Results
- Adding an element is performed in O (1) time, because new elements are inserted at the beginning of the chain;
- The operations of obtaining and deleting an element can be performed in O (1) time, if the hash function evenly distributes the elements and there are no collisions. The mean running time will be Θ (1 + α), where α is the load factor. In the worst case, the execution time can be Θ (n) (all elements in one chain);
- Keys and values can be of any type, including null. For storage of primitive types, the corresponding wrapper classes are used;
- Not synchronized.
Links
HashMap source
HashMap source from JDK7
Sources JDK OpenJDK & trade 6 Source Release - Build b23
Measurement tools - memory-measurer and Guava (Google Core Libraries).
Source: https://habr.com/ru/post/128017/
All Articles