Testing ABBYY FineReader 11
The 11th version of the well-known ABBYY FineReader OCR software in Russia and in the world of the world has recently been released . This version announced a lot of improvements, and the main focus is on increasing performance and reducing errors. These improvements - in comparison with the 10th version. I have not used this program since my student years (from the beginning of the 2000s), and I probably missed the versions, six. In those years, the Internet and mobile technologies were not developed so much, and there was much time. Therefore, I was ready to take a book in the library for an hour, make copies, go to one end of the city to the computer, where there is a scanner, then to the other end, to where there is a FineReader, and then home, to correct the recognition and formatting errors in Word. files. Today, the user has become lazier and more demanding, so I want to consider working with the program from the perspective of modern available technologies and an acute shortage of time.
Thanks to dimonline and ABBYY for the promo key and the FineReader version 11 CE (Corporate Edition), thanks to which we managed to carry out several tests.
So, I took the book guidebook "Switzerland" and at a certain angle photographed on the iPhone a few turns. One of the turns:

')
In total, I took 14 photographs, which I quickly transferred to a laptop. Laptop configuration: MacBook Pro 15 "/ Core i7 2.66 GHz / RAM 8GB / Mac OS X Lion, and FineReader itself is running on VMware Fusion / Windows 7 x64 (2 processor cores and 2 GB RAM are allocated). I ran FineReader, selected the" File (image in PDF), chose the files, clicked “Open” and went to another window to go about their business. After about 15 minutes, the characteristic sound notified the end of the process and the finished PDF file with recognized pages appeared before my eyes. Here’s how one looks from the pages in the file itself:

However, the text is highlighted:

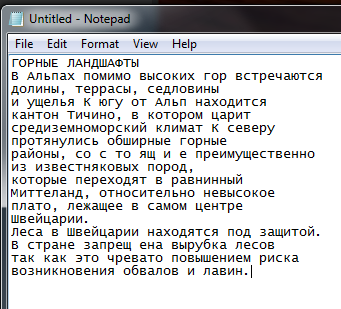
and in notebook looks like this:

Next, I went into image editing and eliminated the trapezoidal distortion by specifying the location of the corners of a rectangular page. Unfortunately, there are spherical distortions on my pages. In general, the page and its pictures began to look geometrically correct, but the text recognition did not change. Then I took a photo of the flash page, holding the phone vertically above the book. As a result, I have this page in PDF:

and the selected text reads well in notepad:
Old folk wisdom in action is better to shoot better than to retouch, or rather, to spend a few minutes preparing the set (light, background) and equipment (megapixels, focus), and then enjoy the automated (here ABBYY tried) recognition process.
In the home library there was a 500-page manual for a certain computer program (251-page PDF-file), taken in the Internet. In ordernot to incur the wrath of copyright gods to observe the conditions for the use of intellectual property, I do not insert screenshots. Pages are photographed with slight spherical distortion in the binding area. Many pictures and tables. Pictures, basically, are screenshots from the actual program described. Test results are as follows:
File opening time: 12 minutes.
Recognition time: 26 minutes.
Export time in Word: 2 minutes.
Project save time: 11 minutes.
Of the shortcomings, only one can be noted - most of the pictures are identified as text blocks. Perhaps because these pictures are screenshots that include the title bar and the program menu. To do this, I had to go to each page with a picture and change the type and borders of the blocks.
Block type adjustment time: 35 minutes.
I decided to draw conclusions on each of the announced improvements.
It is, indeed, more accurate, but many pictures were defined as text, although they have a rectangular shape and a lot of “non-text”. Perhaps, the program requires additional functionality in the form of a sensitivity setting, a slider with a scale, on one side of the scale the inscription “rather text”, and on the other - “rather picture”.
Yes, indeed, despite the fact that the program was executed on a virtual machine with many programs running in parallel, the process was stable, without failures. For fidelity, the recognition of a 500-page document was carried out 3 times.
Manual fix works, while automatic changes were not noticed. Although, the text on the distorted page was recognized correctly. But before (about 10 years ago) the slightest distortion inevitably led to errors.
There were no particular problems with working with a multi-page document.
There are such modes, but there is enough disk space and computer power for “Best quality”.
Quite useful and relevant features.
This feature is useful for post processing. If the purpose of recognition is simply to read and not print, then it is not necessary to use the function.
Many programs from ancient times have such windows. I always closed them and put a tick "Do not show this window again." But in this case I decided to use it (perhaps the transition to Mac and iPhone had an effect) and I liked it, since FineReader has only used this window. And to climb the menu was too lazy.
Usability is quite a modern trend and software is nice to use. For a certain category of office workers, it will greatly save time and nerves. The stated improvements really work. If I were a student again, I would simply photograph passages of books on the phone in the library and recognize them at home (for abstracts and dissertations). Now, I need such functionality no more than 1-2 times a year, so an online service with paging will be useful for me.
I want to wish the ABBYY team to continue to delight and amaze the consumer.
* For rightholders:
The materials mentioned in this article were recognized solely for the purpose of verifying the functionality and performance of the software. All recognition results, as well as digital images of book pages, were subsequently irrevocably destroyed.
PS Concerning a question from vmb about accents . This link takes a screenshot of the following text in Greek:
Ἐχεκράτης
[57a] αὐτός, ὦ Φαίδων, παρεγένου Σωκράτει ἐκείνῃ τῇ ἡμέρᾳ ᾗ τὸ φάρμακον ἔπιεν ἐν τῷ δεμμττρίῳ, ἢἢυςςςςςςςςςςςυννάάάά
Φαίδων
αὐτός, ὦ Ἐχέκρατες.
Ἐχεκράτης
τί οὖν δή ἐστιν ἅττα εἶπεν ἀνὴρ πρὸ τοῦ θανάτου; καὶ πῶς ἐτελεύτα; ἡδέως γὰρ ἂν ἐγὼ ἀκούσαιμι. καὶ γὰρ οὔτε [τῶν πολιτῶν] Φλειασίων οὐδεὶς πάνυ τι ἐπιχωριάζει τὰ νῦν Ἀθήναζε, οὔτε τις ξένος ἀφῖκται χρόνου συχνοῦ [57b] ἐκεῖθεν ὅστις ἂν ἡμῖν σαφές τι ἀγγεῖλαι οἷός τ ἦν περὶ τούτων, πλήν γε δὴ ὅτι φάρμακον πιὼν ἀποθάνοι · τῶν δὲ ἄλλων οὐδὲν εἶχεν φράζειν.
which, when selecting only the Greek language, was recognized by FineReader as:
Έχεκράτης
[57β] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τό φάρμακον έπιεν έν τώ δεμμττρρω, ή ς ς σ σ σ σ σ λ σ σ δ δ δ δ σ σ σ σ
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εΐπεν άνήρ προ του θανάτου; καί πώς έτελεύτα; ήδέως γάρ άν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδείς πάνυ τι επιχωριάζει τά νυν Άθήναζε, οΰτε τις ξένος άφΐκται χρόνου συχνού [57β] έκεΐθεν όστις άν ήμΐν σαφές τι άγγεΐλαι οΐός τ 'ήν περί τούτων, πλήν γε δή ότι φάρμακον πιών άποθάνοι · τών δέ άλλων ούδέν ειχεν φράζειν.
when choosing Greek and English - so:
Έχεκράτης
[57a] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τό φάρμακον έπιεν έν τώ δεμμττρρω, ή ς υ υ υ υ υ υ υ υ υ υ υ δ δ δ δ
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εΐπεν άνήρ προ του θανάτου; καί πώς έτελεύτα; ήδέως γάρ άν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδείς πάνυ τι επιχωριάζει τά νυν Άθήναζε, οΰτε τις ξένος άφΐκται χρόνου συχνού [57b] έκεΐθεν όστις άν ήμΐν σαφές τι άγγεΐλαι οΐός τ 'ήν περί τούτων, πλήν γε δή ότι φάρμακον πιών άποθάνοι · τών δέ άλλων ούδέν ειχεν φράζειν.
and when creating a copy of the Greek language and adding all the characters with accents there it turned out like this:
Έχεκράτης
[57ā] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η ττ φάρμακον επιεν έν τω δεσμωττρίω, ήσστάφρα, ήπτεεν έν τω δπστρραα, τσφρεα τω δπσεα τν τπ
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εĩπεν άνήρ πρò τοû θανάτου; καί πώς έτελεύτα; ήδέως γάρ αν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδεìς πάνυ τι επιχωριάζει τά νûν Άθήναζε, οΰτε τις ξένος άφîκται χρόνου συχνού [57ċ>] έκεîθεν öστις αν ήμîν σαφές τι άγγεΐλαι οîός τ 'ήν περί τούτων, πλήν γε δή öτι φάρμακον πιών άποθάνοι- τών δέ άλλων ούδέν εĩχεν φράζειν.
Thanks to dimonline and ABBYY for the promo key and the FineReader version 11 CE (Corporate Edition), thanks to which we managed to carry out several tests.
Functionality test
So, I took the book guidebook "Switzerland" and at a certain angle photographed on the iPhone a few turns. One of the turns:
')
In total, I took 14 photographs, which I quickly transferred to a laptop. Laptop configuration: MacBook Pro 15 "/ Core i7 2.66 GHz / RAM 8GB / Mac OS X Lion, and FineReader itself is running on VMware Fusion / Windows 7 x64 (2 processor cores and 2 GB RAM are allocated). I ran FineReader, selected the" File (image in PDF), chose the files, clicked “Open” and went to another window to go about their business. After about 15 minutes, the characteristic sound notified the end of the process and the finished PDF file with recognized pages appeared before my eyes. Here’s how one looks from the pages in the file itself:
However, the text is highlighted:
and in notebook looks like this:
Next, I went into image editing and eliminated the trapezoidal distortion by specifying the location of the corners of a rectangular page. Unfortunately, there are spherical distortions on my pages. In general, the page and its pictures began to look geometrically correct, but the text recognition did not change. Then I took a photo of the flash page, holding the phone vertically above the book. As a result, I have this page in PDF:
and the selected text reads well in notepad:
Old folk wisdom in action is better to shoot better than to retouch, or rather, to spend a few minutes preparing the set (light, background) and equipment (megapixels, focus), and then enjoy the automated (here ABBYY tried) recognition process.
Performance test
In the home library there was a 500-page manual for a certain computer program (251-page PDF-file), taken in the Internet. In order
File opening time: 12 minutes.
Recognition time: 26 minutes.
Export time in Word: 2 minutes.
Project save time: 11 minutes.
Of the shortcomings, only one can be noted - most of the pictures are identified as text blocks. Perhaps because these pictures are screenshots that include the title bar and the program menu. To do this, I had to go to each page with a picture and change the type and borders of the blocks.
Block type adjustment time: 35 minutes.
findings
I decided to draw conclusions on each of the announced improvements.
More precise definition of block types
It is, indeed, more accurate, but many pictures were defined as text, although they have a rectangular shape and a lot of “non-text”. Perhaps, the program requires additional functionality in the form of a sensitivity setting, a slider with a scale, on one side of the scale the inscription “rather text”, and on the other - “rather picture”.
More stable work with large (more than 100 files) document packages
Yes, indeed, despite the fact that the program was executed on a virtual machine with many programs running in parallel, the process was stable, without failures. For fidelity, the recognition of a 500-page document was carried out 3 times.
Improved automatic and manual correction of distortions of photographed documents
Manual fix works, while automatic changes were not noticed. Although, the text on the distorted page was recognized correctly. But before (about 10 years ago) the slightest distortion inevitably led to errors.
Improved work with multipage documents
There were no particular problems with working with a multi-page document.
Availability of saving modes in PDF: "Best quality", "Small size" and "Balanced mode"
There are such modes, but there is enough disk space and computer power for “Best quality”.
Saving and converting document images and PDF files to ODT (OpenOffice.org Writer), DjVu, ePub, fb2 format
Quite useful and relevant features.
Style editor
This feature is useful for post processing. If the purpose of recognition is simply to read and not print, then it is not necessary to use the function.
In the "New Task" window, the functions that are most often needed are
Many programs from ancient times have such windows. I always closed them and put a tick "Do not show this window again." But in this case I decided to use it (perhaps the transition to Mac and iPhone had an effect) and I liked it, since FineReader has only used this window. And to climb the menu was too lazy.
Conclusion
Usability is quite a modern trend and software is nice to use. For a certain category of office workers, it will greatly save time and nerves. The stated improvements really work. If I were a student again, I would simply photograph passages of books on the phone in the library and recognize them at home (for abstracts and dissertations). Now, I need such functionality no more than 1-2 times a year, so an online service with paging will be useful for me.
I want to wish the ABBYY team to continue to delight and amaze the consumer.
* For rightholders:
The materials mentioned in this article were recognized solely for the purpose of verifying the functionality and performance of the software. All recognition results, as well as digital images of book pages, were subsequently irrevocably destroyed.
PS Concerning a question from vmb about accents . This link takes a screenshot of the following text in Greek:
Ἐχεκράτης
[57a] αὐτός, ὦ Φαίδων, παρεγένου Σωκράτει ἐκείνῃ τῇ ἡμέρᾳ ᾗ τὸ φάρμακον ἔπιεν ἐν τῷ δεμμττρίῳ, ἢἢυςςςςςςςςςςςυννάάάά
Φαίδων
αὐτός, ὦ Ἐχέκρατες.
Ἐχεκράτης
τί οὖν δή ἐστιν ἅττα εἶπεν ἀνὴρ πρὸ τοῦ θανάτου; καὶ πῶς ἐτελεύτα; ἡδέως γὰρ ἂν ἐγὼ ἀκούσαιμι. καὶ γὰρ οὔτε [τῶν πολιτῶν] Φλειασίων οὐδεὶς πάνυ τι ἐπιχωριάζει τὰ νῦν Ἀθήναζε, οὔτε τις ξένος ἀφῖκται χρόνου συχνοῦ [57b] ἐκεῖθεν ὅστις ἂν ἡμῖν σαφές τι ἀγγεῖλαι οἷός τ ἦν περὶ τούτων, πλήν γε δὴ ὅτι φάρμακον πιὼν ἀποθάνοι · τῶν δὲ ἄλλων οὐδὲν εἶχεν φράζειν.
which, when selecting only the Greek language, was recognized by FineReader as:
Έχεκράτης
[57β] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τό φάρμακον έπιεν έν τώ δεμμττρρω, ή ς ς σ σ σ σ σ λ σ σ δ δ δ δ σ σ σ σ
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εΐπεν άνήρ προ του θανάτου; καί πώς έτελεύτα; ήδέως γάρ άν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδείς πάνυ τι επιχωριάζει τά νυν Άθήναζε, οΰτε τις ξένος άφΐκται χρόνου συχνού [57β] έκεΐθεν όστις άν ήμΐν σαφές τι άγγεΐλαι οΐός τ 'ήν περί τούτων, πλήν γε δή ότι φάρμακον πιών άποθάνοι · τών δέ άλλων ούδέν ειχεν φράζειν.
when choosing Greek and English - so:
Έχεκράτης
[57a] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η τό φάρμακον έπιεν έν τώ δεμμττρρω, ή ς υ υ υ υ υ υ υ υ υ υ υ δ δ δ δ
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εΐπεν άνήρ προ του θανάτου; καί πώς έτελεύτα; ήδέως γάρ άν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδείς πάνυ τι επιχωριάζει τά νυν Άθήναζε, οΰτε τις ξένος άφΐκται χρόνου συχνού [57b] έκεΐθεν όστις άν ήμΐν σαφές τι άγγεΐλαι οΐός τ 'ήν περί τούτων, πλήν γε δή ότι φάρμακον πιών άποθάνοι · τών δέ άλλων ούδέν ειχεν φράζειν.
and when creating a copy of the Greek language and adding all the characters with accents there it turned out like this:
Έχεκράτης
[57ā] αύτός, ώ Φαίδων, παρεγένου Σωκράτει εκείνη τη ήμερα η ττ φάρμακον επιεν έν τω δεσμωττρίω, ήσστάφρα, ήπτεεν έν τω δπστρραα, τσφρεα τω δπσεα τν τπ
Φαίδων
αύτός, ώ Έχέκρατες.
Έχεκράτης
τί οΰν δή έστιν άττα εĩπεν άνήρ πρò τοû θανάτου; καί πώς έτελεύτα; ήδέως γάρ αν έγώ άκούσαιμι. καί γάρ οΰτε [τών πολιτών] Φλειασίων ούδεìς πάνυ τι επιχωριάζει τά νûν Άθήναζε, οΰτε τις ξένος άφîκται χρόνου συχνού [57ċ>] έκεîθεν öστις αν ήμîν σαφές τι άγγεΐλαι οîός τ 'ήν περί τούτων, πλήν γε δή öτι φάρμακον πιών άποθάνοι- τών δέ άλλων ούδέν εĩχεν φράζειν.
Source: https://habr.com/ru/post/127978/
All Articles