Instant search in 75 gigabytes
It will be a question of how a quick search was implemented for large amounts of data on this page . There you can search for a password by hash, for the PvPGN game server, and generate the same hashes.
The search is written in pure PHP, without the use of modules and third-party databases. In principle, this way you can increase the volume to many terabytes, there would be a place - the speed will not suffer much from this.
Further from the beginning to the end, the whole process is described, which includes brute force, the creation of a hash table, its sorting and, in fact, the search.
')
To prevent a hash table for searching for passwords, a password must be mixed with salt when creating it. But, having a list of hashes and knowing how salt is added, simple passwords can still be found brute-force.
The hash in PvPGN is generated without salt, so the idea was to generate a large key-value table (hash password).
I will give you the simplest example of C # brute-force that goes through passwords to search for an MD5 hash. And the generation of an unsorted table is reduced to a simple folding of the generated data into a file of the CSV type.
Example with the source of the link .
Run: BruteForce.exe [sought_hash] [password_length] [password_name]
Now it was necessary to sort the data by hash, because the result will be used binary search, which works only with sorted data.
Without thinking, I imported test 5 GB of data into MySQL on my computer. The index did not create, just by the request I started the sorting with export to CSV:
It took him 16 hours of time, but while this was done, 2 files were created in the TEMP folder: 16 and 25 gigabytes.
But even with the index (which was created a couple of hours), this option did not suit me anyway, if only because of the gigabytes absorbed when sorting, since increasing the size of the tables on my disk would simply not be enough space.
I tried to make a table in SQLite, but it was not designed for large volumes, so I worked very slowly (in 1 GB, the search by hash was performed for about 6 seconds). MySQL is faster, but in both cases it did not suit the final size, which was almost 2 or more times the original data (along with the index).
Since I have never dealt with sorting big data (without loading the entire file into memory), I picked up the first algorithm I got - bubble sorting :). I wrote a small C # code so that the file was sorted in itself, and launched a sample of 500 megabytes for the night. The file was still sorted the next day. It is understandable - because if the smallest entry is at the end of the file, then with this algorithm it will move down one line, and for each such shift you need to go through the entire file from beginning to end!
Began to look for other methods of sorting, merging and pyramid turned out to be suitable. I started to implement their hybrid, but I accidentally found information about the sort utility, which by default comes with Windows, starting with XP. As it turned out, she was perfect for my task! I do not know how it works, but the description says that it sorts the file in one pass (5 GB sorted out in half an hour). In the process of sorting, the utility requires as much additional free space as the source file weighs (for a temporary file).
But here, everything was not all smooth. When the 190 GB file was sorted, it took 3 times more space, and I began to search and delete something to free up disk space. In addition, incomprehensible "artifacts" appeared in the final file:
They were about 10 in random parts of the file. I ran the sort several times, waiting 24 hours each time, but the artifacts still appeared. I did not understand why this happened, I have 12 GB of RAM, Win7 x64, at that time the computer worked for a week without shutting down. I can assume that the memory during this time "clogged up", because after rebooting the system, the same sorting was successful the first time.
Now it seems silly, but before it always seemed to me that you could search through files only by loading the entire file into memory, or by reading the entire file line by line. Having tried binary search in a large file in practice, and seeing how fast it works, and also in PHP, for me it turned out to be a small discovery. Such a search can work as fast with mega large amounts of data, and, without loading the processor and not eating the memory.

Binary (aka binary) search works by the following principle:
And, of course, the main condition for binary search is that the array should be sorted by the search key.
In a file, binary search works in the same way. Move the offset position to the middle of the file using the fseek function and adjust the position to the beginning of the line (in case you hit the middle of the record), then read the entire record there.
It would be possible to dwell on this if not for one BUT ...
The search turned out to be impossible for files that exceed the value of PHP_INT_MAX (2147483647 bytes). Moreover, sometimes the fseek function returns -1, and sometimes everything is fine with it, but the offset is set to where it is not clear. As a result, it does not read what is needed. The bug was not obvious, but in the process of finding the problem I found info in the bug tracker . Also on the PHP documentation site for the fseek function, there is a comment on how to search for files larger than 2 GB (the fseek64 function). It comes down to reading not from the beginning of the file, but from the current offset, to the required place, by iteration. But I checked it also does not work.
I had to split the files in parts. I did not find a suitable utility for breaking down the file (I was probably looking bad, but on the first page of the search there were only dubious installations). In the arsenal of Windows, oddly enough, there is no such utility. In the total commander can not be divided by bytes, but I needed accuracy.
I wrote a simple utility in C # that reads the source file by bytes and stores them sequentially in separate files of a given size.
Maybe someone will need to download the source from here .
Run: Split.exe [file] [size_in_bytes]
To begin with, I divided the sorted data into two separate files: .hash, .pass, in which hashes and passwords for them are stored, respectively. Then, all the data I just "packed" in hex. Numbers are easily packed in this way up to 2 times, and since the length of each value is fixed, 0xF is added to the missing gap.
How compression is done, and how the search takes place, is clearly seen in the following example (we are looking for the password for the hash 0dd5eac5b02376a456907c705c6f6fb0b5ff67cf):

Then I split the .pass file in parts so that the passwords are not cut off at the end of the file, and do not go beyond the border PHP_INT_MAX: 2147483647 - (2147483647% password size) bytes.
The maximum size of the .hash file is 185 mb, and it was not necessary to break it.
In fact, now the search is performed only in .hash files, and only passwords are loaded from .pass (from a certain position in the file). But this does not cancel the main topic of this article, I checked the speed on raw data was no lower.
All the raw files weighed 260 GB, and after compression we got 70 GB. This size includes passwords from 1 to 6 characters from numbers with letters, and from 7 to 10 characters - only numbers, totaling about 13.5 billion passwords. Later I added another 100 million vocabulary words. As a result, about 90% of the passwords from the real PvPGN server should be located (from my former PvPGN server found 93.5%).
One good person ported the hash function of PvPGN from PHP to JavaScript (he also provided me with a virtual server with 250 GB of space for tables).
I made measurements of the performance of different implementations of the hash:

Implementations in different languages are available for download harpywar.pvpgn.pl/?do=hash
Obviously, C is the fastest. In all browsers, the speed is about the same, although Firefox hangs for the duration of the script.
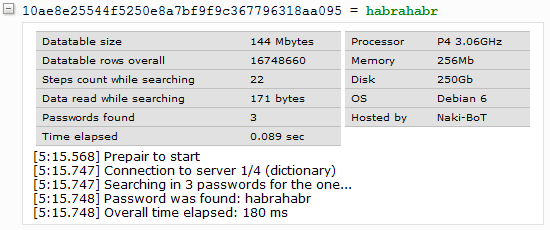
It turned out my search was slowing down because of PHP. Therefore, immediately after testing, I decided to send this resource-intensive task to the client in the browser. Moreover, for the client it will be completely unnoticeable - on average, no more than 1000 hashes are needed per search query. To redo what had already been done very little: the found passwords needed to be transferred to the client in the JSON array, and in the browser to iterate the passwords and generate hashes from them. If the generated hash fits the desired one, then the password is considered to be found.
A rough but illustrative example of how this works is in the screenshot (it still has an uncompressed file):
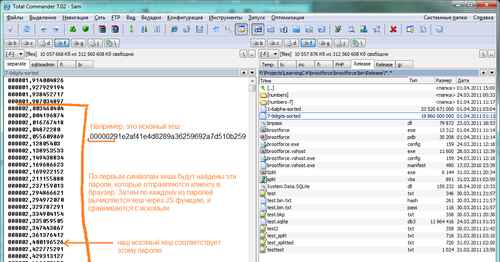
Probably, there are other ways of searching in large data arrays, or even ready-made solutions. But for a specific task, my implementation was very fast, and very important, rather compact. I spent about a week on this, including background generation and table sorting.
Probably, this is not the most suitable example of creating something, because passwords with so many characters get over relatively quickly if the bruteforce code is parallelized and ported to the GPU.
But in the process I received a lot of knowledge and experience, which I wanted to share.
Update
- Laid PHP source code for those interested, but not having table files, their study may be uninteresting: index.php , hashcrack.class.php .
- As an example, binary search in a file can be used to cut data in large logs (if you need to analyze the statistics "from" and "to" a specific date)
- With the total commander, I made a mistake - with the help of it, it is still possible to split a file into parts exactly by bytes (suggested by Joshua5 ).
- I am not very familiar with the features of various databases, which is why the search was long.
Alexey Pechnikov suggests that SQLite performance can be very high , and for the table it was necessary to use "fts4". Probably something similar is in MySQL.
- Below in the comments there are ideas how you could better organize the data and search.
- A comment from webhamster fully reflects what I wanted to show in this topic.
The search is written in pure PHP, without the use of modules and third-party databases. In principle, this way you can increase the volume to many terabytes, there would be a place - the speed will not suffer much from this.
Further from the beginning to the end, the whole process is described, which includes brute force, the creation of a hash table, its sorting and, in fact, the search.
')
Bruteforce
To prevent a hash table for searching for passwords, a password must be mixed with salt when creating it. But, having a list of hashes and knowing how salt is added, simple passwords can still be found brute-force.
The hash in PvPGN is generated without salt, so the idea was to generate a large key-value table (hash password).
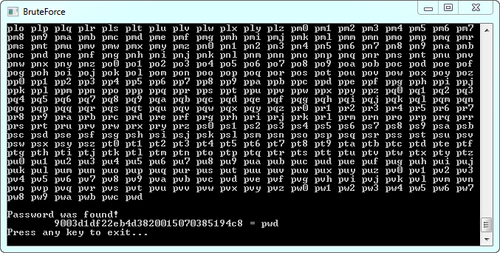
I will give you the simplest example of C # brute-force that goes through passwords to search for an MD5 hash. And the generation of an unsorted table is reduced to a simple folding of the generated data into a file of the CSV type.
class Program { static bool _isFound = false; static string _findHash; static string _symbols; static int _pass_lenght; static void Main(string[] args) { _findHash = args[0]; // _pass_lenght = int.Parse(args[1]); // _symbols = args[2]; // byte[] data = new byte[_symbols.Length]; Process(data, 0); Console.ReadLine(); } private static string hash; private static byte[] data_trim; private static string pass; // static void Process(byte[] data, int index) { // if (index == _pass_lenght) { data_trim = data.TakeWhile((v, idx) => data.Skip(idx).Any(w => w != 0x00)).ToArray(); // pass = Encoding.ASCII.GetString(data_trim); hash = GetHash(pass); Console.Write("{0} ", pass); if (hash == _findHash) { _isFound = true; Console.WriteLine("\n\nPassword was found!\n\t{0} = {1}", hash, pass); } return; } // foreach (byte c in _symbols) { if (_isFound) return; data[index] = c; Process(data, index + 1); } } // md5 hash static string GetHash(string value) { MD5 md5 = new MD5CryptoServiceProvider(); byte[] output = md5.ComputeHash(Encoding.ASCII.GetBytes(value)); return BitConverter.ToString(output).Replace("-", "").ToLower(); // hex string } } Example with the source of the link .
Run: BruteForce.exe [sought_hash] [password_length] [password_name]
Sorting
Now it was necessary to sort the data by hash, because the result will be used binary search, which works only with sorted data.
Without thinking, I imported test 5 GB of data into MySQL on my computer. The index did not create, just by the request I started the sorting with export to CSV:
SELECT hash, pass INTO OUTFILE 'd:\\result.csv' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '' LINES TERMINATED BY '\n' FROM hashes ORDER BY hash It took him 16 hours of time, but while this was done, 2 files were created in the TEMP folder: 16 and 25 gigabytes.
But even with the index (which was created a couple of hours), this option did not suit me anyway, if only because of the gigabytes absorbed when sorting, since increasing the size of the tables on my disk would simply not be enough space.
I tried to make a table in SQLite, but it was not designed for large volumes, so I worked very slowly (in 1 GB, the search by hash was performed for about 6 seconds). MySQL is faster, but in both cases it did not suit the final size, which was almost 2 or more times the original data (along with the index).
Since I have never dealt with sorting big data (without loading the entire file into memory), I picked up the first algorithm I got - bubble sorting :). I wrote a small C # code so that the file was sorted in itself, and launched a sample of 500 megabytes for the night. The file was still sorted the next day. It is understandable - because if the smallest entry is at the end of the file, then with this algorithm it will move down one line, and for each such shift you need to go through the entire file from beginning to end!
Began to look for other methods of sorting, merging and pyramid turned out to be suitable. I started to implement their hybrid, but I accidentally found information about the sort utility, which by default comes with Windows, starting with XP. As it turned out, she was perfect for my task! I do not know how it works, but the description says that it sorts the file in one pass (5 GB sorted out in half an hour). In the process of sorting, the utility requires as much additional free space as the source file weighs (for a temporary file).
But here, everything was not all smooth. When the 190 GB file was sorted, it took 3 times more space, and I began to search and delete something to free up disk space. In addition, incomprehensible "artifacts" appeared in the final file:
They were about 10 in random parts of the file. I ran the sort several times, waiting 24 hours each time, but the artifacts still appeared. I did not understand why this happened, I have 12 GB of RAM, Win7 x64, at that time the computer worked for a week without shutting down. I can assume that the memory during this time "clogged up", because after rebooting the system, the same sorting was successful the first time.
Search
Now it seems silly, but before it always seemed to me that you could search through files only by loading the entire file into memory, or by reading the entire file line by line. Having tried binary search in a large file in practice, and seeing how fast it works, and also in PHP, for me it turned out to be a small discovery. Such a search can work as fast with mega large amounts of data, and, without loading the processor and not eating the memory.
Binary (aka binary) search works by the following principle:
- The array is divided into 2 halves and the reading position moves to the middle.
- The current value that is found in the middle is compared with the desired one.
- If the desired is> current, then the second half of the array is taken, if the sought <current is the first half.
- Perform 1 to 3 step with this half of the array.
And, of course, the main condition for binary search is that the array should be sorted by the search key.
In a file, binary search works in the same way. Move the offset position to the middle of the file using the fseek function and adjust the position to the beginning of the line (in case you hit the middle of the record), then read the entire record there.
It would be possible to dwell on this if not for one BUT ...
Division
The search turned out to be impossible for files that exceed the value of PHP_INT_MAX (2147483647 bytes). Moreover, sometimes the fseek function returns -1, and sometimes everything is fine with it, but the offset is set to where it is not clear. As a result, it does not read what is needed. The bug was not obvious, but in the process of finding the problem I found info in the bug tracker . Also on the PHP documentation site for the fseek function, there is a comment on how to search for files larger than 2 GB (the fseek64 function). It comes down to reading not from the beginning of the file, but from the current offset, to the required place, by iteration. But I checked it also does not work.
I had to split the files in parts. I did not find a suitable utility for breaking down the file (I was probably looking bad, but on the first page of the search there were only dubious installations). In the arsenal of Windows, oddly enough, there is no such utility. In the total commander can not be divided by bytes, but I needed accuracy.
I wrote a simple utility in C # that reads the source file by bytes and stores them sequentially in separate files of a given size.
Maybe someone will need to download the source from here .
Run: Split.exe [file] [size_in_bytes]
Compression
To begin with, I divided the sorted data into two separate files: .hash, .pass, in which hashes and passwords for them are stored, respectively. Then, all the data I just "packed" in hex. Numbers are easily packed in this way up to 2 times, and since the length of each value is fixed, 0xF is added to the missing gap.
How compression is done, and how the search takes place, is clearly seen in the following example (we are looking for the password for the hash 0dd5eac5b02376a456907c705c6f6fb0b5ff67cf):
0D D5 EA - the first 6 characters of the hash. Thus, there will be duplicate hashes, but there are not so many of them. And since all passwords are saved, even from a thousand passwords, you can quickly restore the original hash.70 FF - the number 70 is packed here; this is the number of passwords that is contained in the digits.pass file for hashes starting at 0dd5ea59 99 95 68 FF FF - the number 59999568 is packed here, this is the starting position for reading passwords in the digits.pass file11a19a90 - the position from which reading of 70 passwords starts in the digits.pass file; it is calculated like this: 59999568 * 5 (the length of any password already compressed, in bytes) = 299997840 (translate to hex)84 04 05 38 8F - the number 840405388 is packed here, this is the password corresponding to the desired hashThen I split the .pass file in parts so that the passwords are not cut off at the end of the file, and do not go beyond the border PHP_INT_MAX: 2147483647 - (2147483647% password size) bytes.
The maximum size of the .hash file is 185 mb, and it was not necessary to break it.
In fact, now the search is performed only in .hash files, and only passwords are loaded from .pass (from a certain position in the file). But this does not cancel the main topic of this article, I checked the speed on raw data was no lower.
All the raw files weighed 260 GB, and after compression we got 70 GB. This size includes passwords from 1 to 6 characters from numbers with letters, and from 7 to 10 characters - only numbers, totaling about 13.5 billion passwords. Later I added another 100 million vocabulary words. As a result, about 90% of the passwords from the real PvPGN server should be located (from my former PvPGN server found 93.5%).
Little optimization
One good person ported the hash function of PvPGN from PHP to JavaScript (he also provided me with a virtual server with 250 GB of space for tables).
I made measurements of the performance of different implementations of the hash:
Implementations in different languages are available for download harpywar.pvpgn.pl/?do=hash
Obviously, C is the fastest. In all browsers, the speed is about the same, although Firefox hangs for the duration of the script.
It turned out my search was slowing down because of PHP. Therefore, immediately after testing, I decided to send this resource-intensive task to the client in the browser. Moreover, for the client it will be completely unnoticeable - on average, no more than 1000 hashes are needed per search query. To redo what had already been done very little: the found passwords needed to be transferred to the client in the JSON array, and in the browser to iterate the passwords and generate hashes from them. If the generated hash fits the desired one, then the password is considered to be found.
A rough but illustrative example of how this works is in the screenshot (it still has an uncompressed file):
Total
Probably, there are other ways of searching in large data arrays, or even ready-made solutions. But for a specific task, my implementation was very fast, and very important, rather compact. I spent about a week on this, including background generation and table sorting.
Probably, this is not the most suitable example of creating something, because passwords with so many characters get over relatively quickly if the bruteforce code is parallelized and ported to the GPU.
But in the process I received a lot of knowledge and experience, which I wanted to share.
Update
- Laid PHP source code for those interested, but not having table files, their study may be uninteresting: index.php , hashcrack.class.php .
- As an example, binary search in a file can be used to cut data in large logs (if you need to analyze the statistics "from" and "to" a specific date)
- With the total commander, I made a mistake - with the help of it, it is still possible to split a file into parts exactly by bytes (suggested by Joshua5 ).
- I am not very familiar with the features of various databases, which is why the search was long.
Alexey Pechnikov suggests that SQLite performance can be very high , and for the table it was necessary to use "fts4". Probably something similar is in MySQL.
- Below in the comments there are ideas how you could better organize the data and search.
- A comment from webhamster fully reflects what I wanted to show in this topic.
Source: https://habr.com/ru/post/127569/
All Articles