ArBB, Cilk +, OpenMP, OpenCL, TBB - Knowledge Day or Election Day

Remember, have you made any significant choice in recent years without first reading the reviews of those who have already chosen this on the Internet?
We live in an era of "evolving recall".
Almost all purchases, the choice of a place of rest, work, study and treatment, a bank and a tank, a film and a company ... It is better to read one review than thousands of advertisements.
Although, most likely, the reviews you did not use in all cases.
For example, when choosing a companion / life partner.
Or when choosing a booth in a public toilet :).
Or - when choosing a way to parallelize programs. In the latter case, probably simply because you did not come across such reviews. I'll try to fix it. Namely, I will tell you what to expect from Cilk +, OpenMP, OpenCL, TBB and ArBB (Ct) in terms of their capabilities, ease of development and use, quality of documentation, as well as expected performance.
')
Immediately, I note that all the tools described below are either free or are included in the compiler price.
OpenMP.
A set of compiler pragmas for automatic parallelization (you can also use additional library functions).
It is supported by all major compilers, otherwise it is simply ignored, without causing errors.
It works on all common architectures (in theory - and on ARM) and OS (in theory - even on Android).
Documentation is good and is everywhere - right up to glossy magazines.
The ease of learning is exceptional. Time of development and implementation - minutes. For a complex project - no more than an hour.
Debugging is limited, but possible — see Intel Parallel Studio.
Disadvantages : does not use a GPU, does not support many functions necessary for “advanced” monitoring and synchronization of threads; does not always provide good performance; non-optimally “combined” in various components of the application and with other means of parallelization.
Example. A forMP loop using OpenMP will look like this:
#pragma omp parallel for for (i = 0; i < n; ++i) result[i] = a[i] * b[i]; OpenCL (Open Computing Language)
Young (2008 birth) standard of heterogeneous parallel programming. That is, inside it uses not only the CPU, but also the GPU, which is its main, and perhaps the only advantage. Supported by AMD, Apple, ARM, Intel, NVidia and all manufacturers of mobile phones. Not supported by Microsoft.
One more declared advantage of OpenCL is the automatic vectorization of the code with hardware capabilities. But the same effect can be achieved without using OpenCL :)
The concept of the standard: the central host and the set of OpenCL devices (Compute Unit), in parallel performing certain functions of the core programmer (kernel). Kernels are written in the C language dialect (C with some limitations and additions) and compiled by a special compiler.
The main program running on the host has a lot to do with everything :):
- create an OpenCL environment,
- create kernels
- define the execution platform = contexts, devices and queues,
- create and build a program (dynamic library for kernels),
- select and initialize objects in memory,
- identify the kernels and attach them to their arguments, and finally transfer the memory and kernels to the execution of OpenCL devices.
Documentation : very little.
The most difficult thing to learn / implement is a tool, especially given the lack of documentation and, especially, examples. The time of development and implementation - days. For a complex project - a week.
Other disadvantages : not the best performance on the existing examples, using only the CPU, the difficulty of debugging and finding problems with performance.
Example. Function for loop
void scalar_mul(int n, const float *a, const float *b, float *result) { int i; for (i = 0; i < n; ++i) result[i] = a[i] * b[i]; } translated to OpenCL, turn into a kernel:
__kernel void scalar_mul(__global const float *a, __global const float *b, __global float *result) { size_t id = get_global_id(0); result[id] = a[id] * b[id]; } ... plus you need another full screen of code (!) For the main host program (see above). This code, which calls special OpenCL functions, of course, can be written off from the Intel OpenCL SDK example, but you still have to understand it.
The following three tools for parallelizing programs form Inel Parallel Building Blocks:
Cilk Plus, TBB, ArBB.
Cilk Plus.
"Plus" means Cilk extensions for working with arrays.The C \ C ++ extension, supported exclusively by Intel compilers (Windows, Linux) and, from August 2011, is gcc 4.7, which immediately shows a flaw - the lack of real cross-platform functionality. GPU is also not supported.
Advantages:
Easy to learn . Cilk is a little harder than OpenMP. It is entered into the project in a matter of minutes, in the worst case - working hours.
At the same time, the performance exceeds OpenMP. In addition, ilk combines well with all Inel Parallel Building Blocks and OpenCL.
When using the Intel Cilk SDK, the code changes are minimal, the compiler performs all the work behind the scenes.
Documentation : a bit, but given the simplicity of Cilk, this is not a problem.
An example . Your favorite Cilk for loop would look like this:
cilk_for (i = 0; i < n; ++i) { result[i] = a[i] * b[i]; } TBB (Threading Building Blocks)
Created by Intel library C ++ templates for parallel programming. Works on Linux, Windows, Mac, and even on Xbox360, does not require an Intel compiler. Disadvantage : does not use a GPU.
The library implemented:
• thread-safe containers: vector, queue, hash table;
• parallel algorithms for, reduce, scan, pipeline, sort, and so on.
• scalable memory allocators;
• mutexes and atomic operations;
Documentation and examples : a lot, good quality.
Easy to learn and use . For those who do not have experience using patterns in the code, it is quite difficult. For those who have it, it is also not always elementary. Significant code changes may be required. The time of studying \ implementation is from one working day to a week.
Advantages : excellent performance, independence from the compiler, the ability to use the individual components of the library independently.
Example.
void scalar_mul(int n, const float *a, const float *b, float *result) { for (int i = 0; i < n; ++i) result[i] = a[i] * b[i]; } with the use of TBB, it is necessary to turn it into an operator () of the so-called Body class (cycle body):
using namespace tbb; class ApplyMul { public: void operator()( const blocked_range<size_t>& r ) const { float *a = my_a; float *b = my_b; float *result = my_result; for( size_t i=r.begin(); i!=r.end(); ++i ) result[i] = a[i] * b[i]; } ApplyMul( float a[], float b[], float result []) : my_a(a), my_b(b), my_result(result) {} }; Where blocked_range is a templite iterator provided by tbb.
And only after that you can use tbb parallel_for
void parallel_mul ( float a[], float b[],float result[], int n ) { parallel_for(blocked_range<size_t>(0,n), ApplyMul(a, b, result)); } ArBB (Array Building Blocks).
In girlhood - Ct, about which izard has already written in this blog . Intel library of C ++ templates for parallel programming.
Intel ArBB runs on Windows * and Linux *, and is supported by Intel, Microsoft Visual C ++ and GCC compilers. With the appropriate run-nime should work on the GPU and the upcoming Intel MIC
Advantages : the in-line full security inherent in the design (no data race) uses TBB inside itself, respectively, it is well combined in different modules.
Documentation : alas, laconic, examples are quite normal.
The difficulty of mastering / implementing is at the level of TBB.
Disadvantages:
Still in beta.
Designed to handle large data arrays, on small arrays at the expense of overhead does not provide good performance.
Example:
What will the notorious for loop in ArBB turn into? At first glance in the documentation you might think that in _for. But no. _for in ArBB is just an indication that the loop has dependencies in iterations and can only be executed sequentially. There is no “parallel for” in ArBB at all.
And all the same
void scalar_mul(int n, const float *a, const float *b, float *result) { for (int i = 0; i < n; ++i) result[i] = a[i] * b[i]; } void parallel_mul(dense<f32> a, dense<f32> b, dense<f32> &result) { result = a * b; } with a challenge
dense<f32> va; bind (va, a, n); dense<f32> vb; bind (vb, b, n); dense<f32> vres; bind (vres, result, n); call(parallel_mul)(va, vb, vres); Summary №1
Selection table.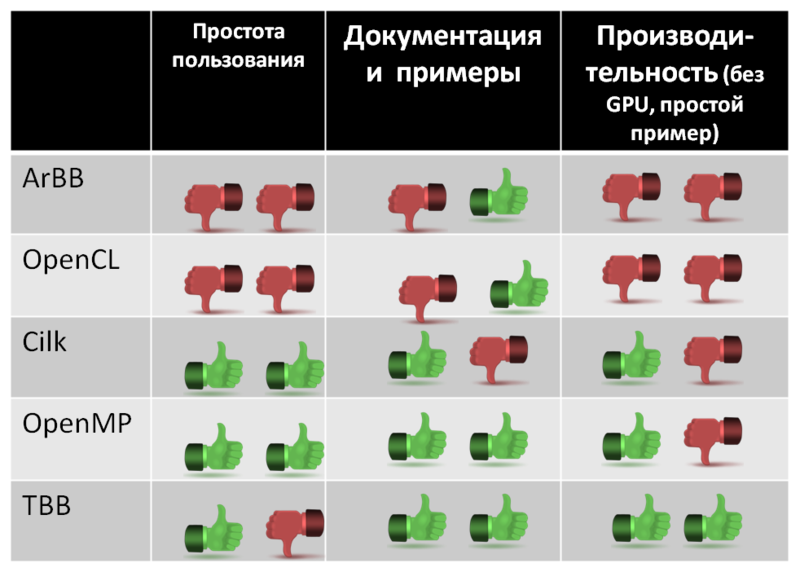
Summary number 2
The horizontal lines in the picture at the beginning of this post are parallel. Although it is possible that according to observers, it turns out that it does not.
Source: https://habr.com/ru/post/127491/
All Articles