Counting characters in Microsoft Equation formulas
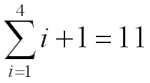
In our company there are several rates for proofreaders who read documents. Their duties also include reconciliation of typed and newly printed texts, with originals, which are originally on paper. Salary for specialists of this kind is calculated on the basis of the piece-rate principle, that is, how much I read, I received so much. As a unit of measure of work, signs are used which consist of all visible characters, with the exception of spaces, tabs, paragraph marks, etc.
Accordingly, there is a task to count the number of characters in the texts that go to work. When calculating a plain text, there are no problems and any student of the first or second year can easily cope with such a task. Problems in our case appeared when trying to take into account the signs in the elements typed using Microsoft Equation. In addition, the situation was aggravated by the fact that the service information, which described the content of the element, was removed from many documents. That is, from the formulas actually remained some pictures. Thus, the problem arose - to count the number of characters in the pictures remaining from Microsoft Equation.
')
First of all, it was necessary to deal with what these very "pictures" are. Having saved the document in the xml format and digging into it (of course in parallel using the great and powerful Google), it turned out that the pictures are nothing but WMF files that are pre-compressed using the Deflate algorithm (gzip) and converted to base64 .
It turned out that the original task was reduced to the need to count the number of characters in the WMF file. Considering that this format is vector and not raster, all data about the contained objects is available in it. Actually, in general, the solution to the problem at this stage is already clear, to run through the elements of the vector file and count their number. However, I will describe the data acquisition process in more detail below.
Since WMF is an obsolete format, and EMF has replaced it, all API functions already in Windows XP are focused on EMF. Therefore, for any further action, it is necessary to convert our original file to a new format. This can be done using the SetWinMetaFileBits API function. The next step is to retrieve the data contained in the file. To do this, we apply the API command EnumEnhMetaFile , which, using the callback function, will consistently transfer all the records from the EMF file to our application. The data will be transmitted in the form of an ENHMETARECORD structure containing many parameters, and the parameters will be different for different types of records. In our case, for counting characters, the key are records whose type ENHMETARECORD.iType is equal to the following constants EMR_EXTTEXTOUTW (84), EMR_MOVETOEX (27), EMR_LINETO (54).
Here, perhaps, it is necessary to pause and tell about a small nuance. All elements of the formulas in this vector format are divided into text (for example, letters of the Latin alphabet) and graphic, consisting of a set of lines (for example, a fraction sign, a root sign, etc.). Moreover, if for text elements you can simply count their number, then everything is a bit more complicated with lines. As a solution, I came up with the following method: for each line, we calculate and remember its angular coefficient (calculated from the coordinates of the beginning and end of the line). Further, using the fact that each graphic element is drawn by a sequential set of lines, any sign can be represented as a set of angular coefficients. For example, the division sign is one line, the slope of which is 0, and the large angle bracket> is two consecutive coefficients 104, 76. Thus, by examining various formulas, you can make up a finite set of such sequences that will actually be uniquely compared to displayed characters.
So, back to the counting. Using records with the type EMR_EXTTEXTOUTW we get data about text fragments, and their size is clearly indicated in the structure. And with the help of the EMR_MOVETOEX and EMR_LINETO records we can collect the coordinates of the beginning and end of all lines. Converting this data in the manner described above, we obtain the number of graphic characters. At this point, the calculation can be considered complete.
As a result, the program created on the basis of the algorithm described, shows the number of characters in the formulas, gives how many text characters there were and how many graphic ones, and also can tell which graphic characters were used.
I do not provide more detailed descriptions of the API functions and various constants, since all this data can be easily viewed here .
Source: https://habr.com/ru/post/126046/
All Articles