The story of how lightning "killed" the Amazon cloud
As one of our partners wrote on his Twitter : “Write about five years ago,“ lightning caused a cloud to fall ”and you would be considered an idiot.” But this is exactly what happened on Sunday evening - lightning hit the transformer , which completely de-energized the Amazon data center in Ireland. Unfortunately, the sites of the company “1C-Bitrix” were located in this data center.

We sincerely apologize to all our customers and partners to whom the temporary unavailability of our sites could cause some inconvenience.
')
And today we want to tell you about “how it was”, about our actions and conclusions that we made after this incident.
The whole story "through the eyes of Amazon" is available on a special site that allows you to monitor all of the services of Amazon - status.aws.amazon.com :
The recorded beginning of the accident - August 7th (Sunday) at 21:13 (Moscow time).
The first minus in karma is to us - we, for our part, have not monitored the problem. Why did it happen?
All websites of our company are served by several servers in the “cloud”: two virtual machines — cluster backends, one machine — a load balancer between them, and another machine — a monitoring server that has nagios installed, monitoring a bunch of different services we need ( Load average on servers, correct replication in MySQL, launching the processes we need, etc.)
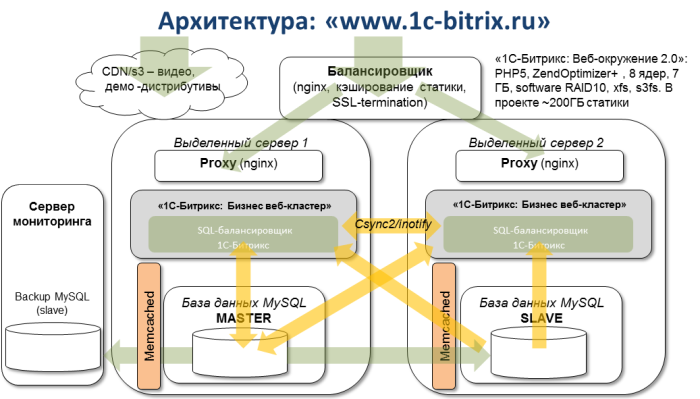
In fact, we are monitoring everything. In addition to the monitoring itself. And this server was in the same data center. That is why we learned about the problem only on Monday morning.
First conclusion: it is necessary to duplicate the monitoring, to use completely external resources for its purposes.
But, let's continue ... Monday, morning, sites are not available. The administrative interface of Amazon says that the machines are running. However, from the outside, only some of them are accessible from the Internet, and there is no connection between them inside. At the same time, the picture changes periodically, something that was previously available is no longer available, which gives some hope that Amazon engineers are working and everything will be available soon.
A small digression - why the data recovery process on the part of Amazon takes so long.
Raising the virtual machines themselves is not such a big problem. Worse discs. In terms of Amazon, this is EBS (Elastic Block Store) , some virtual block devices that can be mounted like regular drives, organized as RAID, and so on.
Due to the accident, the servers controlling EBS were de-energized. As a result, according to Amazon, it required many manual operations, the creation of additional copies of data and the emergency commissioning of additional capacity.
Back to our story. At about 11 am on Monday, it became clear that the quick recovery of our machines would not happen: both cluster backends (files, base) were inaccessible.
A quick launch option is to bring up a new virtual machine in another data center, but in the same Availability Zone .
Why so, and what is the Availability Zone?
One zone combines several data centers. It is within one zone that, for example, using Amazon tools, can quickly make a snapshot of a disk and connect it as a new disk to another server, even located in another data center. It is important that he be in the same “zone”. Also, it is within the same zone that you can switch between different servers (including - and in different data centers) Elastic IP - external IP-addresses by which virtual servers are available.
Amazon has several availability zones: US East, US West, Asia Pacific (Singapore), Asia Pacific (Tokyo) and the EU - Ireland, where our servers are located.
At the same time in Ireland - three data centers. Let's call them conditionally A, B, C.
The very first thought was the decision to launch in general in another zone. For example, somewhere in the States. But practice has shown that this would be an extremely long process - all the data (and we have several hundred gigabytes of it) would have to tediously and for a long time to copy over the network. And the main difficulty would be that for a start it would be necessary to raise the server from which everything can be copied.
(Well, if we have already found the opportunity to raise it, then why not just launch a website on it?)
So. All our servers were located in the data center A. Yes, of course, it would be more correct to install them in different data centers (to ensure reliability). However, in terms of performance (file synchronization, replication in MySQL), it is more convenient to use a configuration in which there is minimal network latency between servers.
1. We have raised a new car in the data center B - a similar configuration.
2. The root section (/ - all software settings, etc.) was transferred from one of the cluster backends in several steps (fortunately, despite the fact that the machine was not available via the Internet, most of the operations could be performed from the Amazon admin panel ):
The whole operation (as opposed to a simple copy) is performed fairly quickly, takes minutes. By the way, this is the standard data transfer mechanism between different data centers in Amazon. But, as mentioned above, it works only within the same Availability Zone.
3. The next step is the transfer of basic data (content, database). We have them on RAID-10, which provides both speed and reliability.
And - the problem. Not from all disks of raid it turns out to make snapshot. We get in the admin short and not very capacious: " Internal error ".
For the files, we take a daily backup (snapshots of all the disks, including the raid disks, are automatically made once a day). Restoring RAID (the procedure for backup and restoring software RAID-10 is generally a separate topic, if someone is interested in it - write, tell).
4. I don’t really want to use a daily backup for the database, this is the most extreme measure. Losing the latest changes in the database, got from the site - very, very sad ...
And here we are saved by the fact that in our web cluster in MySQL replication, not one slave was connected (on the second backend), but two. The second slave was on the monitoring machine and was used only as a real-time backup: the data on this server was copied in real time, but requests to this server were not distributed.
It would seem that happiness is already close ... However, at the time of copying MySQL data to a new machine ... this machine is no longer available.
It was about 13: 00-13: 30. Ironically adds the fact that at about the same time the next, quite positive, Amazon update appeared:
It sounds positive, but in practice it means that the storage inside one zone is centralized. And even the fact that lightning has de-energized only one data center does not guarantee us that everything will work well in another data center.
We never saw the new car in the data center B anymore ...
By the way, it still remains in some “suspended” state (status - stopping):

At 13:30, the next stage of recovery began - we raised a new car in the data center C.
The above paragraphs 1-3 were repeated. Point 4 - successfully completed.
5. Switched the MySQL database from slave mode to master mode.
6. Corrected all configuration files, started all services.
7. Checked the work of the site, after which they switched the external Elastic IP (actually, the address to which www.1c-bitrix.ru resolves ) to a new machine in the admin panel of Amazon.
It was about 3:30 PM Monday.
* * *
The inaccessibility of sites is always unpleasant. However, even in spite of such a regrettable incident, we tried to extract a maximum of experience from it and draw several conclusions.
1. Many people asked the question: “ How did the cloud help you? "
It helped a lot - no matter how paradoxical it sounds, the speed of recovery. A few hours (in fact - for two restorations) - this is a very good result.
If we were located in a datacenter on real physical servers:
We didn’t have any disappointment in the cloud concept.
2. Another question: “ How did your cluster help you? "
The most important advantage is the availability of relevant data.
Without them, we would wait for the service to be restored in Amazon (as of Monday 19:30, the work of all services was not restored, for all users the sample instructions for moving to another data center described above were published; as of this writing The incident on the site status.aws.amazon.com was not closed - it took 39 hours) or they took data from the backup, losing the last changes (they are critical for our site).
In addition, we have made very important conclusions on the support of a symmetric web cluster in the 1C-Bitrix platform. It just allows you to run different nodes of a web project at once in several data centers at any distance from each other. Such a scheme would allow us to locate one node now, for example, in the same Ireland, and another - for example, in the USA. Failure of the entire Availability Zone, and not just one data center, would not affect another zone, and the downtime of our sites would be minimal.
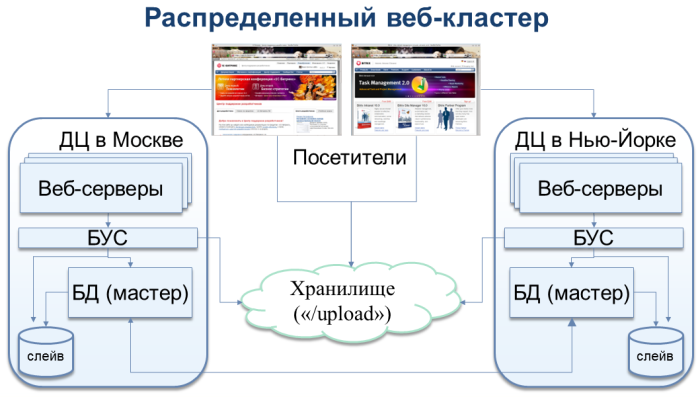
Support for this decision was announced at the latest partner conference "1C-Bitrix". It will be included in the next release of the 1C-Bitrix platform 10.5, which will be released this fall.
Let's get ready for the raging of the elements and we will believe that nature has no bad weather. :)
We sincerely apologize to all our customers and partners to whom the temporary unavailability of our sites could cause some inconvenience.
')
And today we want to tell you about “how it was”, about our actions and conclusions that we made after this incident.
The whole story "through the eyes of Amazon" is available on a special site that allows you to monitor all of the services of Amazon - status.aws.amazon.com :
| 11:13 AM PDT We are investigating connectivity issues in the EU-WEST-1 region. 11:27 AM PDT EC2 APIs in the EU-WEST-1 region are currently impaired. We are working to restore full service. We are also investigating an instance of the availability zone. |
The recorded beginning of the accident - August 7th (Sunday) at 21:13 (Moscow time).
The first minus in karma is to us - we, for our part, have not monitored the problem. Why did it happen?
All websites of our company are served by several servers in the “cloud”: two virtual machines — cluster backends, one machine — a load balancer between them, and another machine — a monitoring server that has nagios installed, monitoring a bunch of different services we need ( Load average on servers, correct replication in MySQL, launching the processes we need, etc.)
In fact, we are monitoring everything. In addition to the monitoring itself. And this server was in the same data center. That is why we learned about the problem only on Monday morning.
First conclusion: it is necessary to duplicate the monitoring, to use completely external resources for its purposes.
But, let's continue ... Monday, morning, sites are not available. The administrative interface of Amazon says that the machines are running. However, from the outside, only some of them are accessible from the Internet, and there is no connection between them inside. At the same time, the picture changes periodically, something that was previously available is no longer available, which gives some hope that Amazon engineers are working and everything will be available soon.
| 9:36 PM PDT We have now recovered 75% of the impacted instances. |
A small digression - why the data recovery process on the part of Amazon takes so long.
Raising the virtual machines themselves is not such a big problem. Worse discs. In terms of Amazon, this is EBS (Elastic Block Store) , some virtual block devices that can be mounted like regular drives, organized as RAID, and so on.
Due to the accident, the servers controlling EBS were de-energized. As a result, according to Amazon, it required many manual operations, the creation of additional copies of data and the emergency commissioning of additional capacity.
Back to our story. At about 11 am on Monday, it became clear that the quick recovery of our machines would not happen: both cluster backends (files, base) were inaccessible.
A quick launch option is to bring up a new virtual machine in another data center, but in the same Availability Zone .
Why so, and what is the Availability Zone?
One zone combines several data centers. It is within one zone that, for example, using Amazon tools, can quickly make a snapshot of a disk and connect it as a new disk to another server, even located in another data center. It is important that he be in the same “zone”. Also, it is within the same zone that you can switch between different servers (including - and in different data centers) Elastic IP - external IP-addresses by which virtual servers are available.
Amazon has several availability zones: US East, US West, Asia Pacific (Singapore), Asia Pacific (Tokyo) and the EU - Ireland, where our servers are located.
At the same time in Ireland - three data centers. Let's call them conditionally A, B, C.
The very first thought was the decision to launch in general in another zone. For example, somewhere in the States. But practice has shown that this would be an extremely long process - all the data (and we have several hundred gigabytes of it) would have to tediously and for a long time to copy over the network. And the main difficulty would be that for a start it would be necessary to raise the server from which everything can be copied.
(Well, if we have already found the opportunity to raise it, then why not just launch a website on it?)
So. All our servers were located in the data center A. Yes, of course, it would be more correct to install them in different data centers (to ensure reliability). However, in terms of performance (file synchronization, replication in MySQL), it is more convenient to use a configuration in which there is minimal network latency between servers.
1. We have raised a new car in the data center B - a similar configuration.
2. The root section (/ - all software settings, etc.) was transferred from one of the cluster backends in several steps (fortunately, despite the fact that the machine was not available via the Internet, most of the operations could be performed from the Amazon admin panel ):
- made a snapshot of the disk from the old machine in the data center A;
- a disk (volume) made available in data center B was made from a snapshot;
- The new drive is mounted on a new machine in the data center B.
The whole operation (as opposed to a simple copy) is performed fairly quickly, takes minutes. By the way, this is the standard data transfer mechanism between different data centers in Amazon. But, as mentioned above, it works only within the same Availability Zone.
3. The next step is the transfer of basic data (content, database). We have them on RAID-10, which provides both speed and reliability.
And - the problem. Not from all disks of raid it turns out to make snapshot. We get in the admin short and not very capacious: " Internal error ".
For the files, we take a daily backup (snapshots of all the disks, including the raid disks, are automatically made once a day). Restoring RAID (the procedure for backup and restoring software RAID-10 is generally a separate topic, if someone is interested in it - write, tell).
4. I don’t really want to use a daily backup for the database, this is the most extreme measure. Losing the latest changes in the database, got from the site - very, very sad ...
And here we are saved by the fact that in our web cluster in MySQL replication, not one slave was connected (on the second backend), but two. The second slave was on the monitoring machine and was used only as a real-time backup: the data on this server was copied in real time, but requests to this server were not distributed.
It would seem that happiness is already close ... However, at the time of copying MySQL data to a new machine ... this machine is no longer available.
It was about 13: 00-13: 30. Ironically adds the fact that at about the same time the next, quite positive, Amazon update appeared:
| 2:26 AM PDTs, we’ve been able to keep track of the EBS backed EC2 instances. We're continuing to bring additional capacity online. We will continue to post updates as we have new information. |
It sounds positive, but in practice it means that the storage inside one zone is centralized. And even the fact that lightning has de-energized only one data center does not guarantee us that everything will work well in another data center.
We never saw the new car in the data center B anymore ...
By the way, it still remains in some “suspended” state (status - stopping):
At 13:30, the next stage of recovery began - we raised a new car in the data center C.
The above paragraphs 1-3 were repeated. Point 4 - successfully completed.
5. Switched the MySQL database from slave mode to master mode.
6. Corrected all configuration files, started all services.
7. Checked the work of the site, after which they switched the external Elastic IP (actually, the address to which www.1c-bitrix.ru resolves ) to a new machine in the admin panel of Amazon.
It was about 3:30 PM Monday.
* * *
The inaccessibility of sites is always unpleasant. However, even in spite of such a regrettable incident, we tried to extract a maximum of experience from it and draw several conclusions.
1. Many people asked the question: “ How did the cloud help you? "
It helped a lot - no matter how paradoxical it sounds, the speed of recovery. A few hours (in fact - for two restorations) - this is a very good result.
If we were located in a datacenter on real physical servers:
- If this data center were de-energized, we would not have access to our data. At all. We would wait for it to rise.
- If you did not want to wait, you would need to take data from the backup. From which? How and where to do it? In another datacenter?
- The good question is which other data center to move during an accident. Finding the server we need configuration - not the most trivial task. Time consuming.
- Moved It is necessary to change the DNS. It is time again.
We didn’t have any disappointment in the cloud concept.
2. Another question: “ How did your cluster help you? "
The most important advantage is the availability of relevant data.
Without them, we would wait for the service to be restored in Amazon (as of Monday 19:30, the work of all services was not restored, for all users the sample instructions for moving to another data center described above were published; as of this writing The incident on the site status.aws.amazon.com was not closed - it took 39 hours) or they took data from the backup, losing the last changes (they are critical for our site).
In addition, we have made very important conclusions on the support of a symmetric web cluster in the 1C-Bitrix platform. It just allows you to run different nodes of a web project at once in several data centers at any distance from each other. Such a scheme would allow us to locate one node now, for example, in the same Ireland, and another - for example, in the USA. Failure of the entire Availability Zone, and not just one data center, would not affect another zone, and the downtime of our sites would be minimal.
Support for this decision was announced at the latest partner conference "1C-Bitrix". It will be included in the next release of the 1C-Bitrix platform 10.5, which will be released this fall.
Let's get ready for the raging of the elements and we will believe that nature has no bad weather. :)
Source: https://habr.com/ru/post/125932/
All Articles