QNX RTOS: Flow Planning
 Continuing the cycle of QNX real-time operating system notes. This time I would like to talk about scheduling threads in QNX6 * . As readers already know (who have familiarized themselves with the previous note of the cycle ) , the QNX6 microkernel manages threads, not processes. And it is the microkernel that loads the context of the thread that should receive control in the next moment. Choosing a thread to be executed by the processor (i.e., actively using processor time) is scheduling threads.
Continuing the cycle of QNX real-time operating system notes. This time I would like to talk about scheduling threads in QNX6 * . As readers already know (who have familiarized themselves with the previous note of the cycle ) , the QNX6 microkernel manages threads, not processes. And it is the microkernel that loads the context of the thread that should receive control in the next moment. Choosing a thread to be executed by the processor (i.e., actively using processor time) is scheduling threads.When flow scheduling occurs
The QNX Neutrino microkernel does not run all the time, but only gets control of system calls, exceptions, and interrupts. The microkernel also performs thread scheduling during its work. From here, we can make a correct conclusion that the operation of scheduling flows does not happen by itself, but by some event. In fact, there are few such events:
- Crowding out. If a thread with a higher priority than the currently running one has entered the READY state, then the microkernel stops the thread that is currently running, switches contexts and starts the thread with a higher priority. The thread that was running before this will remain the first in the queue for execution.
- Blocking A thread during its execution (i.e. during operation) may call a function that will lead to its blocking. For example, it will attempt to capture a semaphore or transmit a message using the system function
MsgSend()(directly or indirectly). In this case, the kernel will remove such a process from the execution queue and transfer control to another thread. - Cession (transfer of control, yield). A thread can voluntarily transfer control if it calls the
sched_yield()function. In this case, the thread is put last in the queue for execution and the microkernel will transfer control to another thread (maybe the one that just gave up control).
Flow parameters affecting planning
One of the main functions of the QNX Neutrino microkernel ( and perhaps the most important after messaging ) is scheduling threads. It is the microkernel that switches contexts and selects which thread will be executed at the next moment in time. The microkernel does all this for a reason and not at the request of its left heel, but based on the following flow parameters:
- Thread priority (thread priority level). Each thread in the QNX6 RTOS is executed on a particular priority. The higher the priority, the more chances the thread will get the processor in the first place. If there are two or more threads in the system in the READY state (ready for execution), the microkernel will transfer control to the thread whose priority is higher.
- Discipline planning. Each flow in the system is performed with a certain planning discipline. The microkernel takes into account the planning discipline when there are two or more threads in the READY state that are running on the same priority.
-p program procnto . It should also be borne in mind that at the zero (lowest) priority, the idle thread is executed, which always receives control if there are no more threads in the system with higher priorities in the READY state.The QNX6 operating system supports several thread planning disciplines: FIFO , carousel (cyclic, round-robin, RR) and sporadic ** . This thread attribute will only be considered if the microkernel has to choose between threads with the same priority level. Planning disciplines will be described further.
')
There is another factor that influences the order in which threads are switched. All threads are ready to run and use the processor (i.e. threads in the READY state) are queued. There are 256 such queues in the system (by the number of priorities). All other things being equal, when the microkernel has to choose among two threads with the same priority level, the one that is first in the queue will start to run. Once again, when a stream is preempted by a higher priority, it is put first in the queue, and when assigning (calling
sched_yield() ), the thread becomes the last in the queue.FIFO planning discipline
If the flow has a FIFO (First In First Out) scheduling discipline, it is the first at the input, the first at the output), then it can be run indefinitely. Control will be transferred to another thread only if the thread is superseded by a higher priority thread, the thread is blocked, or voluntarily gives up control. When using this planning discipline, a thread that performs lengthy mathematical calculations can completely capture the processor (i.e., it will not allow threads with the same and lower priority to be executed).
Carousel planning discipline
This planning discipline is completely analogous to FIFO, except that the flow does not run “infinitely”, but only works for a certain time slice (timeslice). When the time slice expires, the microkernel puts the process at the end of a queue of threads that are ready for execution, and control is transferred to the next thread (at the same priority level). If at this priority level there are no other threads in the READY state, then another time quantum is allocated to the flow.
The quantum of time that is allocated to threads with a carousel dispatch discipline for work can be determined using the
sched_rr_get_interval() function. In fact, the time quantum (timeslice) is exactly four times the clock interval (ticksize). In turn, the clock interval is 1ms in systems with a 40 MHz processor and higher and 10ms in systems with a slower processor *** . It turns out that in time-familiar x86 computers and laptops, the time slice is 4ms.Sporadic planning discipline
As in FIFO scheduling, a thread for which sporadic scheduling is applied is executed until it is blocked or preempted by a thread with a higher priority. In addition, as in adaptive planning, the flow for which sporadic planning is applied receives a lower priority. However, sporadic planning provides significantly more accurate flow control.
In sporadic planning, the priority of the flow can dynamically change between the foreground priority (foreground, normal priority) and background (lowered) priority. To control this sporadic transition, the following parameters are used:
- The initial budget of the flow (initial budget) (C) is the amount of time for which the flow can run with normal priority (N) before getting a lower priority (L).
- Low priority (L) - the priority level to which the thread priority will be reduced. With low priority (L), the thread runs in the background. If the thread has a normal priority (N), it is executed with a foreground priority.
- The replenishment period (T) is the period of time during which the flow can spend its execution budget.
- Maximum number of current replenishment (max number of pending replenishments) - this value sets a limit on the number of replenishment operations performed, thereby limiting the amount of system resources allocated to the sporadic planning discipline.
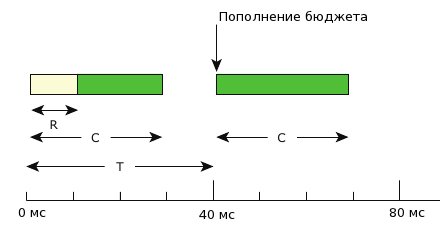
Fig. 1. Replenishment of the flow execution period occurs periodically.
With normal priority N, the flow is executed during the period of time set by its initial execution budget C. After this period expires, the priority of the flow decreases to a low level L until the replenishment operation occurs.
Imagine, for example, a system in which the flow is never blocked and not interrupted - fig. 2
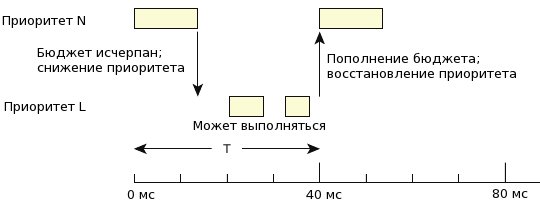
Fig. 2. The priority of a thread is reduced until it is replenished with its implementation budget.
In this case, the thread will go to a level with a lower priority (background mode), where its execution will depend on the priority of other threads in the system.
As soon as replenishment occurs, the priority of the flow rises to the initial level. Thus, in a properly configured system, the thread runs every time period T for the maximum time C. This ensures that the order in which each thread executed with priority N uses only C / T percent system resources.
When a flow is blocked several times, several top-up operations can occur at different times. This may mean that the budget for executing the flow within a period of time T will reach the value C; however, during this period the budget may not be continuous.

Fig. 3. The priority of flow varies between high and low.
In fig. 3, it can be seen that during each 40 ms replenishment period T, the execution budget for stream C is 10 ms.
- The flow is blocked after 3 ms, so a 3 ms refill operation will be scheduled for execution after 40 ms, i.e. at the time of completion of the first replenishment period.
- Flow execution resumes at the 6th millisecond, and this moment becomes the beginning of the next replenishment period T. There is still a 7 ms margin in the flow execution budget.
- The flow is executed without blocking for 7 ms, as a result of which the execution budget of the flow is exhausted, and the priority of the flow is reduced to the level L, at which it can or cannot receive control. A replenishment of 7 ms is scheduled for the 46th millisecond (40 + 6), i.e. after the period T.
- At the 40th millisecond, the flow budget is replenished by 3 ms (see step 1 in the diagram), as a result of which the priority of the flow rises to normal.
- The thread spends 3 ms of its budget and then goes back to low priority.
- At the 46th millisecond, the flow budget is replenished by 7 ms (see step 3), and the flow again gets normal priority.
How to set the priority and discipline of planning from the program
Each thread at startup inherits its priority and planning discipline from the parent thread. During operation, a thread can change these attributes. For this purpose, the following functions are present in QNX6:
| POSIX call | Description |
|---|---|
sched_getparam() | Get priority. |
sched_setparam() | Set priority. |
sched_getscheduler() | Get the planning discipline. |
sched_setscheduler() | Establish a planning discipline. |
SchedGet() and SchedSet() .Little administration
In the previous post I already referred to the
pidin command. This time we will meet two more teams that are specific to QNX. Each QNX6 administrator should know and be able to use these commands. And, perhaps, of the most important commands is use .The
use utility is in some way analogous to the man command. The utility allows you to get help on the executable module (binary executable file, script or shared library). The principle of use somewhat different from man , since All reference information is stored in the executable module itself, and not separately. The command is called, quite simple, for example: # use sleep sleep - suspend execution for an interval (POSIX) sleep time Where: time is the number of seconds to sleep and can be a non-negative floating point number (0 <= time <= 4294967295). The
use utility displays a little help on working with a command, a full description is available in the help system.Another useful command that must be in the arsenal of every self-respecting QNX6 administrator is
pidin . This utility provides various kinds of information about the system, including on executing threads and processes (in this case, the utility is similar to the ps utility). For example, to view general system information, run the following command: # pidin in CPU:X86 Release:6.5.0 FreeMem:166Mb/255Mb BootTime:Jul 05 15:53:27 MSKS 2011 Processes: 43, Threads: 107 Processor1: 131758 Pentium II Stepping 5 2593MHz FPU Calling the utility without parameters displays information on all processes and threads. To obtain information on the process of interest, it is sufficient to specify the
-P key, for example: # pidin -P io-audio pid tid name prio STATE Blocked 90127 1 sbin/io-audio 10o SIGWAITINFO 90127 2 sbin/io-audio 10o RECEIVE 1 90127 3 sbin/io-audio 10o RECEIVE 1 90127 4 sbin/io-audio 10o RECEIVE 1 90127 5 sbin/io-audio 50r INTR 90127 6 sbin/io-audio 50r RECEIVE 7 You can see how the process uses memory, for this you need to run the following command:
# pidin -P io-audio mem pid tid name prio STATE code data stack 90127 1 sbin/io-audio 10o SIGWAITINFO 128K 112K 8192(516K)* 90127 2 sbin/io-audio 10o RECEIVE 128K 112K 4096(132K) 90127 3 sbin/io-audio 10o RECEIVE 128K 112K 8192(132K) 90127 4 sbin/io-audio 10o RECEIVE 128K 112K 4096(132K) 90127 5 sbin/io-audio 50r INTR 128K 112K 4096(132K) 90127 6 sbin/io-audio 50r RECEIVE 128K 112K 4096(132K) libc.so.3 @b0300000 472K 12K a-ctrl-audiopci.so @b8200000 12K 4096 deva-mixer-ac97.so @b8204000 24K 8192 Information is even displayed about the shared libraries used. This is very convenient in my opinion. The
pidin utility supports quite a lot of commands and options, a list and description of which can be viewed in the QNX help system.And last for today, but not least, the
slay utility. As it is not difficult to guess, this command is used to send signals to processes. By default, a SIGTERM signal is sent, which usually leads to the completion of the process. You can specify another signal to send to the process. With this use, slay similar to the kill command, but most interestingly, the slay command accepts not only the process identifier (PID), but also the name of the process. This is also very convenient when administering. In addition to sending signals, the utility can be used to change the priority or discipline of process planning. If you want to change the characteristics of a single thread, you can specify the key -T . The following several commands change the priority and planning discipline of the 3 io-audio process threads: [22:47:33 root]# pidin -P io-audio pid tid name prio STATE Blocked 90127 1 sbin/io-audio 10o SIGWAITINFO 90127 2 sbin/io-audio 10o RECEIVE 1 90127 3 sbin/io-audio 10o RECEIVE 1 90127 4 sbin/io-audio 10o RECEIVE 1 90127 5 sbin/io-audio 50r INTR 90127 6 sbin/io-audio 50r RECEIVE 7 [22:47:36 root]# slay -T 3 -P 11r io-audio [22:47:38 root]# pidin -P io-audio pid tid name prio STATE Blocked 90127 1 sbin/io-audio 10o SIGWAITINFO 90127 2 sbin/io-audio 10o RECEIVE 1 90127 3 sbin/io-audio 11r RECEIVE 1 90127 4 sbin/io-audio 10o RECEIVE 1 90127 5 sbin/io-audio 50r INTR 90127 6 sbin/io-audio 50r RECEIVE 7 A full description of the
slay utility is available in the QNX help system.Just in case, I would like to note that in QNX6 there are also familiar UNIX utilities
ps and kill . However, it is much more convenient to pidin and slay in QNX6, since they take into account the specifics of the system.Conclusion
After reading this note, you got an idea about flow planning in QNX6, sufficient knowledge of planning priorities and disciplines, system functions and utilities for managing processes and flows. QNX also has an interesting technology, Adaptive Partitioning (adaptive decomposition), which allows you to form groups of processes and assign them a percentage of CPU usage. In order not to throw everything in one pile, I will try to describe this technology in one of the following notes.
Bibliography
- QNX Neutrino Real-Time Operating System 6.3. System architecture ISBN 5-94157-827-X
- QNX Neutrino Real-Time Operating System 6.3. User's manual. ISBN 978-5-9775-0370-9
- Rob Krten, “An Introduction to QNX Neutrino 2. A Guide for Real-Time Application Developers,” 2nd Edition. ISBN 978-5-9775-0681-6
* QNX6 in this note is QNX 6.5.0. Since the QNX Neutrino core can be improved in one of the following versions, the flow scheduling mechanisms outlined here can change.
** In QNX6, there is also another planning discipline (OTHER, o), which is identical to the carousel (round-robin, RR, r).
*** The clock interval (ticksize) can be changed, for example, using the
ClockPeriod() function.Source: https://habr.com/ru/post/125835/
All Articles