Nodeload2: Download Engine - Reload
Nodeload, the first project of the GitHub team, performed using node.js, just turned 1 year old . Nodeload is the service that packs the contents of the Git repository into ZIP archives and tarballs. Since then, the load on the service has increased during the year, and we are faced with various problems. Read about the origin of Nodeload if you don’t remember why it works the way it does now.
Essentially, we have got too many requests going through the same nodeload server. These requests launched
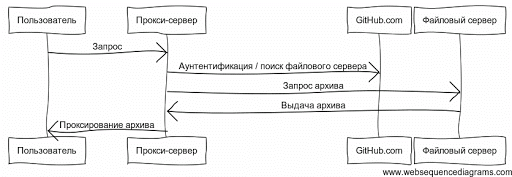
Now the Nodeload server only works as a simple proxy application. This proxy application searches for the appropriate file servers of the requested repository, and proxies the data directly from the file server. File servers now run an archiver application, which is basically the HTTP interface for
')
Node.js is great for this application because of the great streaming API. When implementing a proxy of any kind, you have to deal with clients who cannot read the data as quickly as you can send them. When the HTTP response stream cannot send more data on your part,
After the launch, we stumbled upon some strange problems at the weekend:
To track memory leaks, I tried to install v8-profiler ( including Felix Gnass patch to show heap retainers (objects that keep GC from releasing other objects)), and used node-inspector to monitor live Node processes in production. Webkit Web Inspector works great for profiling an application, but it never showed any obvious memory leaks.
By that time, @ tmm1 , @rtomayko and @rodjek came to the rescue to brainstorm other potential problems. Ultimately, they tracked the leak in the form of accumulation of FD file descriptors on processes.
The fix for this problem is handling the
Nodeload is now more stable than it was before. The rewritten code has become easier and better tested than before. Node.js works great. But the fact that we use HTTP everywhere means that we can easily replace any of the components. Our main task now is to install the best probes to monitor the Nodeload and improve service reliability.
Essentially, we have got too many requests going through the same nodeload server. These requests launched
git archive processes that started SSH processes to communicate with file servers. These requests constantly recorded gigabytes of data, and also transferred them through nginx. One simple idea was to order more servers, but this would create a duplicate cache of archived repositories. I wanted to avoid it, if possible. So, I decided to start over and rewrite the Nodeload from scratch. Now the Nodeload server only works as a simple proxy application. This proxy application searches for the appropriate file servers of the requested repository, and proxies the data directly from the file server. File servers now run an archiver application, which is basically the HTTP interface for
git archive . Cached repositories are now recorded in the TMPFS section to reduce the load on the I / O subsystem. The Nodeload proxy server also tries to use file backup servers instead of active file servers, shifting most of the load to unloaded backup servers.')
Node.js is great for this application because of the great streaming API. When implementing a proxy of any kind, you have to deal with clients who cannot read the data as quickly as you can send them. When the HTTP response stream cannot send more data on your part,
write() returns false. After receiving such a value, you can pause the proxied HTTP request flow until the response object generates a drain event. The drain event means that the response object is ready to send more data, and that you can now resume the proxied HTTP request stream. This logic is fully encapsulated in the ReadableStream.pipe() method. // proxy the file stream to the outgoing HTTP response var reader = fs.createReadStream('some/file'); reader.pipe(res); Heavy launch
After the launch, we stumbled upon some strange problems at the weekend:
- Nodeload servers still had a heavy load on the input / output (IO) system;
- File backup servers exhausted all available RAM;
- Nodeload servers ran out of available RAM;
topandpsdid not show that nodeload processes change their size. Nodeload processes worked well, but we observed that the available server memory was slowly decreasing in size.
proxy_buffering option. As soon as we turned it off, IO dropped sharply. This means that the streams run at the speed of the client. If clients cannot download the archive quickly enough, the proxy pauses the HTTP request flow. This is passed on to the archiver application, which pauses the file stream.To track memory leaks, I tried to install v8-profiler ( including Felix Gnass patch to show heap retainers (objects that keep GC from releasing other objects)), and used node-inspector to monitor live Node processes in production. Webkit Web Inspector works great for profiling an application, but it never showed any obvious memory leaks.
By that time, @ tmm1 , @rtomayko and @rodjek came to the rescue to brainstorm other potential problems. Ultimately, they tracked the leak in the form of accumulation of FD file descriptors on processes.
tmm1 @ arch1: ~ $ sudo lsof -nPp 17655 | grep ": 7005 ("
node 17655 git 16u IPv4 8057958 TCP 172.17.1.40:49232->172.17.0.148:7005 (ESTABLISHED)
node 17655 git 21u IPv4 8027784 TCP 172.17.1.40 Boron8054- 172.17.0.133:7005 (ESTABLISHED)
node 17655 git 22u IPv4 8058226 TCP 172.17.1.40:42498->172.17.0.134:7005 (ESTABLISHED)
The fix for this problem is handling the
close event of the HTTP request object on the server. pipe() does not actually handle this case, because it is written for a generic API readable stream. The “close” event is different from the more general “end” event, because the first event means that the HTTP request flow was terminated before response.end() was called. // check to see if the request is closed already if (req.connection.destroyed) { return; } var reader = fs.createReadStream('/some/file'); req.on('close', function() { reader.destroy(); }); reader.pipe(res); Conclusion
Nodeload is now more stable than it was before. The rewritten code has become easier and better tested than before. Node.js works great. But the fact that we use HTTP everywhere means that we can easily replace any of the components. Our main task now is to install the best probes to monitor the Nodeload and improve service reliability.
Source: https://habr.com/ru/post/125644/
All Articles