MySQL: optimized construction between
Optimization is clearly not a MySQL server ridge. The purpose of this article is to explain to developers who do not work closely with databases and sometimes do not understand why a query that successfully works in other DBMS in MySQL shamelessly slows down how the construction between MySQL is optimized.
MySQL uses the rule based optimizer. The rudiments of cost based optimization are certainly present in it, but not in the proper way in which I would like to see them. For this reason, often the powers obtained after applying filters of sets are calculated incorrectly. This leads to optimizer errors and a wrong execution plan. Moreover, the obtained optimization between them cannot be changed by explicitly specifying the indices for the execution of the query and the order of joining the tables.
To understand the essence of the bug, we will create a test data set of 125 million records.
The attributes table is essentially a directory, for big_table as well as it contains two columns limiting the interval of dates to one month.
For each attr_id , a large table contains 250,000 entries. Let's try to find out how many records are contained in big_table , taking into account the dates given by the attributes table for the attribute one.
We get about 500 records (the query execution time is negligible and amounted to 00.050 seconds). It is logical to assume that since the data is distributed equally for all attribute values, then when connecting to the attributes table, instead of explicitly specifying the bind variables, the query time should increase slightly, and be no more than 25 seconds. Well check:
Execution time: more than 15 minutes (at this point I interrupted the execution of the request). Why so? The fact is that MySQL does not support dynamic rankings, which is what we are told about by bug # 5982, which was created back in 2004. Let's see the execution plan:
The plan clearly shows that there is a full table scan of 125 million records. Strange decision. Correcting the situation will not help straight_join to change the join order or force index to explicitly specify to use the index. The thing is that at best we get a plan of the form:
Which tells us that the big_table table will be scanned by the desired index, but the index will not be fully utilized, that is, only the first column will be used from it . In some degenerate cases, we can achieve the plan we need and make full use of the index, however, due to the variability of the optimizer and the inability to apply this solution (I will not give here its code, it does not work in 90% of cases) in all 100% of cases, we need different approach.
This campaign offers us MySQL itself. We will explicitly specify bind variables. Of course, for a number of tasks this is not always effective, as it happens that a full scan is faster than the index one, but obviously not in our case when you need to select 500 records from 250,000. To solve the problem, we need to create the following procedure.
')
Those. at the beginning we open the cursor on five hundred entries of the attribute table, and for each row of this table we make a query from big_table . Let's look at the result:
Runtime: 0: 00: 05.017 IMHO the result is much better. Not perfect, but it works.
Now we can consider the opposite example, when the search is performed not in the “transactions” table, but vice versa in the fact table.
This bug occurs if you:
- working with the base GeoIP
- trying to analyze the schedule
- fix currency rates on Forex
- calculate the city according to the operator's number capacity
etc.
First, create a test data set of 25 million rows.
Get a table of the form
And on the move we will try to execute a query that is successfully optimized by all DBMSs except for MySQL:
Execution time: 0: 00: 22.412 . Generally not an option given the fact that we know that such a request should return one unique string. And the higher the value of the variable you select - the more records will be scanned, the query runtime grows exponentially.
MySQL itself to solve this problem offers the following workaround:
Execution time: 0: 00: 00.350 . Not bad. But this solution has several drawbacks, in particular, you will not be able to join with other tables. Those. This query can only exist atomically. To enable joins, use the standard RTree index solution (unless, of course, your directory does not need transactions or you ensure its integrity with triggers, since this type of indexes still works only for MyISAM). For those who do not know what geometric objects in MySQL will give an illustration of what they usually do in such cases:
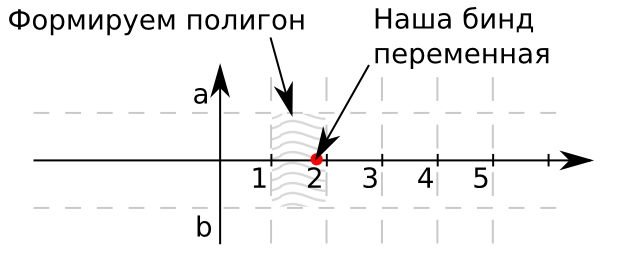
Imagine a plane. On the x-axis will be our search values. The ordinate of your point is equal to zero, since in this particular case, for simplicity, we will search between only for one criterion. If more criteria are needed, use multidimensional objects. As the boundaries of the rectangle a and b usually use 1 and -1, respectively. Thus, the values from our directory will cover the beam going out from 0. They will also be limited by the set of shaded rectangles. If the point belongs to the given rectangle, then the identifier of this rectangle gives us the required identifier of the entry in the table. Run the transformation:
For those who ventured to do this operation with me - monitor the end time update .
If you have reached this step - I advise you not to do it, because if the database settings are incorrect, the creation of this index can be delayed for a week.
Well now you can compare the speed of work. For a start, let's look at the speed of the initial version of the query and the "geometric" gradually increasing the value of the limit from 10 to 100.

On the left - time, below - the limit value. As can be seen from the figure, the time between (blue) grows exponentially depending on whether we are at the beginning or closer to the end, since for each succeeding value of the variable band we need to scan more and more lines. The “geometric” solution (pink) on such small values is just a constant.
Let's try to compare order by limit 1 and geometry for larger values. To do this, we use the procedures to create equal conditions and conduct a random sample.
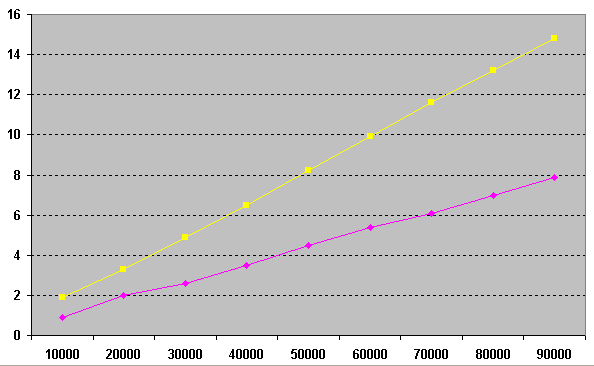
On the graph, we see the result of a consistent increase in the number of runs of procedures from 10,000 to 90,000 and the number of seconds spent on the corresponding operations. As you can see, the “geometric” solution (pink) is 2 times faster than the solution using order by limit 1 (yellow) and in addition, this solution can be applied in standard SQL.
I covered the topic, solely because these shoals are not visible on small amounts of data, but when the database grows and more than 10 users live on it, the performance degradation becomes monstrous, and these types of queries can be found in almost every industrial database.
Successful to you optimizations. If this article will be interesting next time I will tell about the bugs that not only do not interfere with life, but even vice versa - increase the performance of requests, if used correctly.
ZY
MySQL version 5.5.11
All queries were performed after restarting MySQL to exclude getting into the cache results.
MySQL settings are far from standard, but the size of innodb buffers does not exceed 300 Mb, the size of MyISAM buffers (with the exception of the moment the index is created) does not exceed 100Mb.
sizes of files used:
big_range_table.ibd 1740M
big_table.ibd 5520M - without indexes
big_table.ibd 8268M - with indexes
those. hit of objects in a cache of a DB before the beginning of request is completely excluded.
MySQL uses the rule based optimizer. The rudiments of cost based optimization are certainly present in it, but not in the proper way in which I would like to see them. For this reason, often the powers obtained after applying filters of sets are calculated incorrectly. This leads to optimizer errors and a wrong execution plan. Moreover, the obtained optimization between them cannot be changed by explicitly specifying the indices for the execution of the query and the order of joining the tables.
To begin, consider the bug: bugs.mysql.com/bug.php?id=5982 and possible ways to resolve it
To understand the essence of the bug, we will create a test data set of 125 million records.
drop table if exists pivot; drop table if exists big_table; drop table if exists attributes; create table pivot ( row_number int(4) unsigned auto_increment, primary key pk_pivot (row_number) ) engine = innodb; insert into pivot(row_number) select null from information_schema.global_status g1, information_schema.global_status g2 limit 500; create table attributes(attr_id int(10) unsigned auto_increment, attribute_name varchar(32) not null, start_date datetime, end_date datetime, constraint pk_attributes primary key(attr_id) ) engine = innodb; create table big_table(btbl_id int(10) unsigned auto_increment, attr_attr_id int(10) unsigned, record_date datetime, record_value varchar(128) not null, constraint pk_big_table primary key(btbl_id) ) engine = innodb; insert into attributes(attribute_name, start_date, end_date) select row_number, str_to_date("20000101", "%Y%m%d"), str_to_date("20000201", "%Y%m%d") from pivot; insert into big_table(attr_attr_id, record_date, record_value) select p1.row_number, date_add(str_to_date("20000101", "%Y%m%d"), interval p2.row_number + p3.row_number day), p2.row_number * 1000 + p3.row_number from pivot p1, pivot p2, pivot p3; create index idx_big_table_attr_date on big_table(attr_attr_id, record_date); The attributes table is essentially a directory, for big_table as well as it contains two columns limiting the interval of dates to one month.
| attr_id | attribute_name | start_date | end_date |
| one | one | 1/1/2000 12:00:00 AM | 2/1/2000 12:00:00 AM |
| 2 | 2 | 1/1/2000 12:00:00 AM | 2/1/2000 12:00:00 AM |
| 3 | 3 | 1/1/2000 12:00:00 AM | 2/1/2000 12:00:00 AM |
For each attr_id , a large table contains 250,000 entries. Let's try to find out how many records are contained in big_table , taking into account the dates given by the attributes table for the attribute one.
select attr_attr_id, max(record_date), min(record_date), max(record_value), count(1) from big_table where attr_attr_id = 1 and record_date between str_to_date("20000101", "%Y%m%d") and str_to_date("20000201", "%Y%m%d") group by attr_attr_id; | attr_attr_id | max (record_date) | min (record_date) | count (1) |
| one | 2/1/2000 12:00:00 AM | 1/3/2000 12:00:00 AM | 465 |
We get about 500 records (the query execution time is negligible and amounted to 00.050 seconds). It is logical to assume that since the data is distributed equally for all attribute values, then when connecting to the attributes table, instead of explicitly specifying the bind variables, the query time should increase slightly, and be no more than 25 seconds. Well check:
select b.attr_attr_id, max(b.record_date), min(b.record_date), max(b.record_value), count(1) from attributes a join big_table b on b.attr_attr_id = a.attr_id and b.record_date between a.start_date and a.end_date group by b.attr_attr_id; Execution time: more than 15 minutes (at this point I interrupted the execution of the request). Why so? The fact is that MySQL does not support dynamic rankings, which is what we are told about by bug # 5982, which was created back in 2004. Let's see the execution plan:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| one | SIMPLE | b | ALL | idx_big_table_attr_date | 125443538 | Using temporary; Using filesort | |||
| one | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | four | test.b.attr_attr_id | one | Using where |
The plan clearly shows that there is a full table scan of 125 million records. Strange decision. Correcting the situation will not help straight_join to change the join order or force index to explicitly specify to use the index. The thing is that at best we get a plan of the form:
| PRIMARY | b | ref | idx_big_table_attr_date | idx_big_table_attr_date | five | a.attr_id | 6949780 | Using where |
Which tells us that the big_table table will be scanned by the desired index, but the index will not be fully utilized, that is, only the first column will be used from it . In some degenerate cases, we can achieve the plan we need and make full use of the index, however, due to the variability of the optimizer and the inability to apply this solution (I will not give here its code, it does not work in 90% of cases) in all 100% of cases, we need different approach.
This campaign offers us MySQL itself. We will explicitly specify bind variables. Of course, for a number of tasks this is not always effective, as it happens that a full scan is faster than the index one, but obviously not in our case when you need to select 500 records from 250,000. To solve the problem, we need to create the following procedure.
drop procedure if exists get_big_table_data;
delimiter $$
create procedure get_big_table_data(i_attr_from int (10))
main_sql:
begin
declare v_attr_id int (10);
declare v_start_date datetime;
declare v_end_date datetime;
declare ex_no_records_found int (10) default 0;
declare
attr cursor for
select attr_id, start_date, end_date
from attributes
where attr_id > i_attr_from;
declare continue handler for not found set ex_no_records_found = 1;
declare continue handler for sqlstate '42S01' begin
end ;
create temporary table if not exists temp_big_table_results(
attr_attr_id int (10) unsigned,
max_record_date datetime,
min_record_date datetime,
max_record_value varchar (128),
cnt int (10)
)
engine = innodb;
truncate table temp_big_table_results;
open attr;
repeat
fetch attr
into v_attr_id, v_start_date, v_end_date;
if not ex_no_records_found then
insert into temp_big_table_results(attr_attr_id,
max_record_date,
min_record_date,
max_record_value,
cnt
)
select attr_attr_id,
max (record_date) max_record_date,
min (record_date) min_record_date,
max (record_value) max_record_value,
count (1) cnt
from big_table b
where attr_attr_id = v_attr_id and record_date between v_start_date and v_end_date
group by attr_attr_id;
end if ;
until ex_no_records_found
end repeat;
close attr;
select attr_attr_id,
max_record_date,
min_record_date,
max_record_value,
cnt
from temp_big_table_results;
end
$$
delimiter ;
* This source code was highlighted with Source Code Highlighter .')
Those. at the beginning we open the cursor on five hundred entries of the attribute table, and for each row of this table we make a query from big_table . Let's look at the result:
call get_big_table_data(0);
* This source code was highlighted with Source Code Highlighter .Runtime: 0: 00: 05.017 IMHO the result is much better. Not perfect, but it works.
Now we can consider the opposite example, when the search is performed not in the “transactions” table, but vice versa in the fact table.
Now let's look at the bugs.mysql.com/bug.php?id=8113 bug
This bug occurs if you:
- working with the base GeoIP
- trying to analyze the schedule
- fix currency rates on Forex
- calculate the city according to the operator's number capacity
etc.
First, create a test data set of 25 million rows.
drop table if exists big_range_table; create table big_range_table(rtbl_id int(10) unsigned auto_increment, value_from int(10) unsigned, value_to int(10) unsigned, range_value varchar(128), constraint pk_big_range_table primary key(rtbl_id) ) engine = innodb; insert into big_range_table(value_from, value_to, range_value) select @row_number := @row_number + 1, @row_number + 1, p1.row_number + p2.row_number + p3.row_number from (select * from pivot where row_number <= 100) p1, pivot p2, pivot p3, (select @row_number := 0) counter; create index idx_big_range_table_from_to on big_range_table(value_from, value_to); create index idx_big_range_table_from on big_range_table(value_from); Get a table of the form
| rtbl_id | value_from | value_to | range_value |
| one | one | 2 | 3 |
| 2 | 2 | 3 | four |
| 3 | 3 | four | five |
And on the move we will try to execute a query that is successfully optimized by all DBMSs except for MySQL:
select range_value from big_range_table where 10000000.5 >= value_from and 10000000.5 < value_to; Execution time: 0: 00: 22.412 . Generally not an option given the fact that we know that such a request should return one unique string. And the higher the value of the variable you select - the more records will be scanned, the query runtime grows exponentially.
MySQL itself to solve this problem offers the following workaround:
select range_value from big_range_table where value_from <= 25000000 order by value_from desc limit 1; Execution time: 0: 00: 00.350 . Not bad. But this solution has several drawbacks, in particular, you will not be able to join with other tables. Those. This query can only exist atomically. To enable joins, use the standard RTree index solution (unless, of course, your directory does not need transactions or you ensure its integrity with triggers, since this type of indexes still works only for MyISAM). For those who do not know what geometric objects in MySQL will give an illustration of what they usually do in such cases:
Imagine a plane. On the x-axis will be our search values. The ordinate of your point is equal to zero, since in this particular case, for simplicity, we will search between only for one criterion. If more criteria are needed, use multidimensional objects. As the boundaries of the rectangle a and b usually use 1 and -1, respectively. Thus, the values from our directory will cover the beam going out from 0. They will also be limited by the set of shaded rectangles. If the point belongs to the given rectangle, then the identifier of this rectangle gives us the required identifier of the entry in the table. Run the transformation:
alter table big_range_table engine = myisam, add column polygon_value polygon not null; update big_range_table set polygon_value = geomfromwkb(polygon(linestring( /* , */ point(value_from, -1), /* */ point(value_to, -1), /* */ point(value_to, 1), /* */ point(value_from, 1), /* */ point(value_from, -1) /* */ ))); For those who ventured to do this operation with me - monitor the end time update .
select (select @first_value := variable_value from information_schema.global_status where variable_name = 'HANDLER_UPDATE') updated, sleep(10) lets_sleep, (select @second_value := variable_value from information_schema.global_status where variable_name = 'HANDLER_UPDATE') updated_in_a_ten_second, @second_value - @first_value myisam_updated_records, 25000000 / (@second_value - @first_value) / 6 estimate_for_update_in_minutes, (select 25000000 / (@second_value - @first_value) / 6 - time / 60 from information_schema.processlist where info like 'update big_range_table%') estimate_time_left_in_minutes; If you have reached this step - I advise you not to do it, because if the database settings are incorrect, the creation of this index can be delayed for a week.
create spatial index idx_big_range_table_polygon_value on big_range_table(polygon_value); Well now you can compare the speed of work. For a start, let's look at the speed of the initial version of the query and the "geometric" gradually increasing the value of the limit from 10 to 100.
select * from (select row_number * 5000 row_number from pivot order by row_number limit 10) p, big_range_table where mbrcontains(polygon_value, pointfromwkb(point(row_number, 0))) and row_number < value_to; select * from (select row_number * 5000 row_number from pivot order by row_number limit 10) p, big_range_table where value_from <= row_number and row_number < value_to; On the left - time, below - the limit value. As can be seen from the figure, the time between (blue) grows exponentially depending on whether we are at the beginning or closer to the end, since for each succeeding value of the variable band we need to scan more and more lines. The “geometric” solution (pink) on such small values is just a constant.
Let's try to compare order by limit 1 and geometry for larger values. To do this, we use the procedures to create equal conditions and conduct a random sample.
drop procedure if exists pbenchmark_mbrcontains;
delimiter $$
create procedure pbenchmark_mbrcontains(i_repeat_count int (10))
main_sql:
begin
declare v_random int (10);
declare v_range_value int (10);
declare v_loop_counter int (10) unsigned default 0;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter < i_repeat_count then
set v_random = round(2500000 * rand());
select range_value
into v_range_value
from big_range_table
where mbrcontains(polygon_value, pointfromwkb(point(v_random, 0))) and v_random < value_to;
iterate begin_loop;
end if ;
leave begin_loop;
end loop begin_loop;
select v_loop_counter;
end
$$
delimiter ;
drop procedure if exists pbenchmark_limit;
delimiter $$
create procedure pbenchmark_limit(i_repeat_count int (10))
main_sql:
begin
declare v_random int (10);
declare v_range_value int (10);
declare v_loop_counter int (10) unsigned default 0;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter < i_repeat_count then
set v_random = round(2500000 * rand());
select range_value
into v_range_value
from big_range_table
where value_from <= v_random order by value_from desc limit 1;
iterate begin_loop;
end if ;
leave begin_loop;
end loop begin_loop;
select v_loop_counter;
end
$$
delimiter ;
* This source code was highlighted with Source Code Highlighter .On the graph, we see the result of a consistent increase in the number of runs of procedures from 10,000 to 90,000 and the number of seconds spent on the corresponding operations. As you can see, the “geometric” solution (pink) is 2 times faster than the solution using order by limit 1 (yellow) and in addition, this solution can be applied in standard SQL.
I covered the topic, solely because these shoals are not visible on small amounts of data, but when the database grows and more than 10 users live on it, the performance degradation becomes monstrous, and these types of queries can be found in almost every industrial database.
Successful to you optimizations. If this article will be interesting next time I will tell about the bugs that not only do not interfere with life, but even vice versa - increase the performance of requests, if used correctly.
ZY
MySQL version 5.5.11
All queries were performed after restarting MySQL to exclude getting into the cache results.
MySQL settings are far from standard, but the size of innodb buffers does not exceed 300 Mb, the size of MyISAM buffers (with the exception of the moment the index is created) does not exceed 100Mb.
sizes of files used:
big_range_table.ibd 1740M
big_table.ibd 5520M - without indexes
big_table.ibd 8268M - with indexes
those. hit of objects in a cache of a DB before the beginning of request is completely excluded.
Source: https://habr.com/ru/post/125467/
All Articles