How MySQL Optimizes ORDER BY, LIMIT, and DISTINCT
There are tasks that, within the framework of relational DBMS, do not have universal solutions and in order to get at least some acceptable result, you have to invent a whole set of crutches, which you then proudly call “Architecture”. Not so long ago, I just met just that.

Suppose there are some entities A and B, interconnected according to the One-to-Many principle. The number of instances of entity data is large enough. When displaying entities for a user, it is necessary to apply a number of independent criteria, both for entity A and for entity B. Moreover, the criteria are the result of sets of sufficiently large power — on the order of several million entries. Filtering criteria and sorting principle is set by the user. How (I would also ask: Why do they need millions of records on one screen? - but they say it is necessary) to show all this to the user in the time of 0 seconds?
It is always interesting to solve such problems, but their solution is highly dependent on the DBMS that controls your database. If you have a trump ace up your sleeve in the form of an Oracle, then there is a chance that he will use these crutches himself. But let's go down to earth - we only have MySQL, so we’ll have to read the theory.
Using sql task can be formulated as follows:
The query plan in the forehead does not console.
Before making a bunch of unnecessary indexes, let's analyze if it is possible to solve such a problem on the basis of 2 tables. Let the first table store the characteristics of the entity, and the second the components themselves. Normally, to ensure referential integrity, you have to use constraints, but if you have two tables of this kind with large amounts of data and constant DML'ing, I would not advise doing this because of Not a BUG # 15136 . And putting the database into read committed mode with an explicit setting of the dangerous innodb_locks_unsafe_for_binlog parameter to true will not save you. Well this is so, by the way, back to our sheep. First, let's take a look at the documentation - what opportunities do we have to speed up order by .
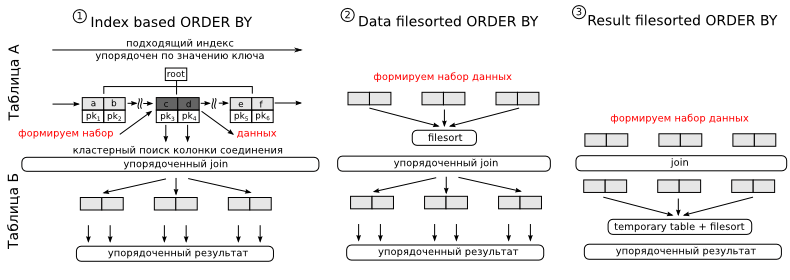
Option 1. Suppose we have an index, the first fields in which are the columns listed in where, and the last column on which the sorting is done. Since the data in the index is stored in sorted form, MySQL can use it to optimize sorting. The algorithm will be as follows. Applying access predicates, we find the parts of the index we need. In the plan, you will see either range , or ref , or index in the type column. Receiving the next portion of data, in runtime mode, we read the remaining columns we need to complete the join (for the index may not have all the necessary columns, which sounds logical) and produce connections with the following table. Since we read the data from the index in an orderly manner, then at the output of such a join, the data will be obtained in an ordered form. When you get the right amount of data, you can stop reading the index. For us, the main disadvantage of this approach is that the columns by which the search is performed and the column by which the sorting is performed are in different tables. So you have to do denormalization.
Options 2 and 3 are only suitable for the case when the data volume for the connection is small, i.e. they are suitable only for highly selective speakers. In option two, we sort the results at the beginning, and then produce join, in option three, the sorting is done after the join. Since the sorting performed by MySQL can be performed only on one table - in the third case a temporary table is required. It's not scary, but it can be very long. However, the third case is the only possible option when MySQL can apply various optimizations to speed up the join. In the first two cases it will be nested loops. In terms of execution, these sortings will differ as follows:
In the second and third methods, the sorting limit can be applied only after the end of the sorting process, for this reason, options 2 and 3 are not used in all cases.
Mysterious filesort is nothing more than a quick sort merge.

Sorting can be done in two ways. The first is that sorting is done at the beginning, and then the rest of the data from the table necessary for the end of the query is read. The second option is considered optimized, because the table is read once, together with all the necessary columns, and then sorted. According to the plan, you cannot distinguish them from each other, but through a quick experiment, it is possible to do it. But whether or not an optimized sorting is applied, the max_length_for_sort_data parameter answers . If the data contained in the tuples is less than specified in this parameter, the sorting will be optimized.
As you can see from the example, the sorting according to algorithm number 2 is really twice as fast, because it reads 2 times less lines. However, it should be borne in mind that optimized sorting requires a significant amount of memory, and if you set the value of the max_length_for_sort_data variable to a too high value, you will get a lot of input and full processor idle time.
So, we will use all the power of the available solutions. We are doing denormalization (how will you support it, is another question). And we build composite indices for non-selective columns and ordinary ones for highly selective ones. Thus, sorting by index and limit limit will be used for queries that only include low-selective columns, and for highly selective ones, more compact and fast indices will be used followed by single-pass filesort without merging.
Unfortunately, after denormalization, we got one drawback. Page layout can scatter the details of one entity across different pages. We cannot allow this, so I propose to set up churches further. Instead of selecting all the necessary data at once - we select only the identifiers of the entity A, with the condition of all the criteria, add to the limit design for paging, and then pick up the details of the entity.
I admit honestly, in my mind, the construction of the form of distinct + order by + limit according to the table of such volumes cannot work quickly, however, the MySQL developers think differently. When working on this issue, I came across a bug Not Not BUG # 33087 , which, as usual, turned out to be not a bug, but a feature. After that, I decided to understand how MySQL optimizes distinct . The first phrase in the documentation was: to optimize distinct , all the same optimizations that are used for group by can be used. Total grouping can be performed by two algorithms.

The first case can be applied only if there is an index that sets the grouping automatically. The second scheme is used in all other cases. The index grouping is performed sequentially and can be limited - and this is very good for us, since this is exactly what we need to display the results on low selective indices. Temporary tables with this approach are not used (to be honest, this is not entirely true, since in general you need to store the results of the partial join, as well as the values themselves resulting from the grouping for the current group, but these are trifles). The second scheme works terribly slowly and eats a bunch of RAM, since all the results of the grouping should be stored in a temporary table, the primary key in which is the group identifier. For very large values, this table is converted to MyISAM and flushed to disk. All new groups are first searched in this large table, and then they change the values in it, if necessary, or add a new line if the group is not found. Final sorting finishes the performance of this algorithm. It is for this reason that if you do not need an ordered set, it is often recommended to add order by null .
Thus, the first approach, as well as the fact that MySQL stops further data retrieval if the limit construction is used together with distinct , and allows us to get the result of grouping very quickly.
So, we got an algorithm that quickly finds the first records, but this algorithm cannot calculate the total number of records. As a workaround, you can return one more entry so that the Next button appears on the screen.
MySQL cannot use more than one index in a query for a single table. What does it threaten us with? Let's try to execute the query type:
Believe you will not wait for it to end, because if you look at the data, you will see a specially formed failure there. The set satisfying the criterion det_low_selective_column = 0 has no intersections with the set satisfying the criterion low_selective_column = 1 . We know this, but unfortunately, MySQL knows nothing about it. Therefore, he chooses an index, which in his opinion is most suitable for scanning and makes a full scan of 2 indexes, selected and PK. This is deadly for a long time since scanning the primary key is actually a full table scan due to its cluster organization. All such gaps must be routed to multiple indices.
And finally, the most embarrassing moment. InnoDB uses only one mutex for each index. Therefore, when you alternately run queries that write and read data at the same time, the InnoDB engine locks the index, suspending read operations, since a write operation can cause B-Tree splitting and the records you are looking for may end up on another page. Smart databases do not block the entire tree, but only its split part. In MySQL, this algorithm is not yet implemented (although you can see the InnoDB plugin on this topic, in 5.5 it seems to have become a standard, maybe things are not so bad there). In order to get around this problem, you need to separate the data, that is, use partitions. All indexes in partition tables are locally partitioned, in fact, each partition in this regard is a separate table, but partitioning is another story and I will not touch on it in this article.
')
The solution of a number of problems that the harsh reality gives us is impossible to describe in two words. The problem of multi-criteria search in several sets is one of them. You can use the Sphinx and download a number of templates provided by this community, but sooner or later you will still encounter a problem to which no one has come up with a solution. And so, then you have to go into the documentation, study the data and persuade users not to do it. I hope this review article will allow you to avoid some of the pitfalls that await you on this thorny path.
ZY a number of optimizations for group by had to be omitted, since the article was already very large. You can read about them in the official documentation , as well as a number of practical tips , to fully understand the issues.
* All code sources were highlighted with Source Code Highlighter .
Suppose there are some entities A and B, interconnected according to the One-to-Many principle. The number of instances of entity data is large enough. When displaying entities for a user, it is necessary to apply a number of independent criteria, both for entity A and for entity B. Moreover, the criteria are the result of sets of sufficiently large power — on the order of several million entries. Filtering criteria and sorting principle is set by the user. How (I would also ask: Why do they need millions of records on one screen? - but they say it is necessary) to show all this to the user in the time of 0 seconds?
It is always interesting to solve such problems, but their solution is highly dependent on the DBMS that controls your database. If you have a trump ace up your sleeve in the form of an Oracle, then there is a chance that he will use these crutches himself. But let's go down to earth - we only have MySQL, so we’ll have to read the theory.
Using sql task can be formulated as follows:
drop table if exists pivot;
drop table if exists entity_details;
drop table if exists entity;
create table pivot
(
row_number int (4) unsigned auto_increment,
primary key pk_pivot (row_number)
)
engine = innodb;
insert into pivot(row_number)
select null
from information_schema.global_status g1, information_schema.global_status g2
limit 500;
create table entity(entt_id int (10) unsigned auto_increment,
order_column datetime,
high_selective_column int (10) unsigned not null ,
low_selective_column int (10) unsigned not null ,
data_column varchar (32),
constraint pk_entity primary key (entt_id)
)
engine = innodb;
create table entity_details(edet_id int (10) unsigned auto_increment,
det_high_selective_column int (10) unsigned not null ,
det_low_selective_column int (10) unsigned not null ,
det_data_column varchar (32),
entt_entt_id int (10) unsigned,
constraint pk_entity_details primary key (edet_id)
)
engine = innodb;
insert into entity(order_column,
high_selective_column,
low_selective_column,
data_column
)
select date_add(str_to_date("20000101", "%Y%m%d"),
interval (p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300) second
)
order_column,
round((p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300) / 3, 0)
high_selective_column,
(p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300) mod 10 low_selective_column,
p1.row_number + (p2.row_number - 1) * 300 + (p3.row_number - 1) * 300 * 300 data_column
from ( select * from pivot limit 300) p1,
( select * from pivot limit 300) p2,
( select * from pivot limit 300) p3;
insert into entity_details(det_high_selective_column,
det_low_selective_column,
det_data_column,
entt_entt_id
)
select e.high_selective_column + p.row_number det_high_selective_column,
case when e.low_selective_column = 0 then 0 else p.row_number end det_low_selective_column,
concat(e.data_column, ' det' ) det_data_column,
e.entt_id
from entity e,
( select * from pivot limit 2) p;
create index idx_entity_details_entt
on entity_details(entt_entt_id);
select *
from entity_details ed, entity e
where ed.entt_entt_id = e.entt_id
order by order_column desc
limit 0, 10;
The query plan in the forehead does not console.
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| one | SIMPLE | e | ALL | PRIMARY | 26982790 | Using filesort | |||
| one | SIMPLE | ed | ref | idx_entity_details_entt | idx_entity_details_entt | five | test.e.entt_id | one | Using where |
Before making a bunch of unnecessary indexes, let's analyze if it is possible to solve such a problem on the basis of 2 tables. Let the first table store the characteristics of the entity, and the second the components themselves. Normally, to ensure referential integrity, you have to use constraints, but if you have two tables of this kind with large amounts of data and constant DML'ing, I would not advise doing this because of Not a BUG # 15136 . And putting the database into read committed mode with an explicit setting of the dangerous innodb_locks_unsafe_for_binlog parameter to true will not save you. Well this is so, by the way, back to our sheep. First, let's take a look at the documentation - what opportunities do we have to speed up order by .
Option 1. Suppose we have an index, the first fields in which are the columns listed in where, and the last column on which the sorting is done. Since the data in the index is stored in sorted form, MySQL can use it to optimize sorting. The algorithm will be as follows. Applying access predicates, we find the parts of the index we need. In the plan, you will see either range , or ref , or index in the type column. Receiving the next portion of data, in runtime mode, we read the remaining columns we need to complete the join (for the index may not have all the necessary columns, which sounds logical) and produce connections with the following table. Since we read the data from the index in an orderly manner, then at the output of such a join, the data will be obtained in an ordered form. When you get the right amount of data, you can stop reading the index. For us, the main disadvantage of this approach is that the columns by which the search is performed and the column by which the sorting is performed are in different tables. So you have to do denormalization.
Options 2 and 3 are only suitable for the case when the data volume for the connection is small, i.e. they are suitable only for highly selective speakers. In option two, we sort the results at the beginning, and then produce join, in option three, the sorting is done after the join. Since the sorting performed by MySQL can be performed only on one table - in the third case a temporary table is required. It's not scary, but it can be very long. However, the third case is the only possible option when MySQL can apply various optimizations to speed up the join. In the first two cases it will be nested loops. In terms of execution, these sortings will differ as follows:
| Using index to sort | Is empty |
| Using filesort for table A | “Using filesort” |
| Saving JOIN results to a temporary table and using filesort | “Using temporary; Using filesort ” |
In the second and third methods, the sorting limit can be applied only after the end of the sorting process, for this reason, options 2 and 3 are not used in all cases.
Mysterious filesort is nothing more than a quick sort merge.
Sorting can be done in two ways. The first is that sorting is done at the beginning, and then the rest of the data from the table necessary for the end of the query is read. The second option is considered optimized, because the table is read once, together with all the necessary columns, and then sorted. According to the plan, you cannot distinguish them from each other, but through a quick experiment, it is possible to do it. But whether or not an optimized sorting is applied, the max_length_for_sort_data parameter answers . If the data contained in the tuples is less than specified in this parameter, the sorting will be optimized.
drop procedure if exists pbenchmark_filesort;
delimiter $$
create procedure pbenchmark_filesort(i_repeat_count int (10))
main_sql:
begin
declare v_variable_value int (10);
declare v_loop_counter int (10) unsigned default 0;
declare continue handler for sqlstate '42S01' begin
end ;
create temporary table if not exists temp_sort_results(
row_number int (10) unsigned
)
engine = memory;
truncate table temp_sort_results;
select variable_value
into v_variable_value
from information_schema.session_status
where variable_name = 'INNODB_ROWS_READ' ;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter <= i_repeat_count then
insert into temp_sort_results(row_number)
select sql_no_cache row_number from pivot order by concat(row_number, '0' ) asc ;
truncate table temp_sort_results;
iterate begin_loop;
end if ;
leave begin_loop;
end loop begin_loop;
select variable_value - v_variable_value records_read
from information_schema.session_status
where variable_name = 'INNODB_ROWS_READ' ;
end
$$
delimiter ;
set session max_length_for_sort_data = 0;
call pbenchmark_filesort(10000);
-- records_read
-- 10 000 000
-- 0:00:12.317 Query OK
set session max_length_for_sort_data = 1024;
call pbenchmark_filesort(10000);
-- records_read
-- 5 000 000
-- 0:00:06.228 Query OK
As you can see from the example, the sorting according to algorithm number 2 is really twice as fast, because it reads 2 times less lines. However, it should be borne in mind that optimized sorting requires a significant amount of memory, and if you set the value of the max_length_for_sort_data variable to a too high value, you will get a lot of input and full processor idle time.
So, we will use all the power of the available solutions. We are doing denormalization (how will you support it, is another question). And we build composite indices for non-selective columns and ordinary ones for highly selective ones. Thus, sorting by index and limit limit will be used for queries that only include low-selective columns, and for highly selective ones, more compact and fast indices will be used followed by single-pass filesort without merging.
create table entity_and_details(entt_entt_id int (10) unsigned not null ,
edet_edet_id int (10) unsigned not null ,
order_column datetime,
high_selective_column int (10) unsigned not null ,
low_selective_column int (10) unsigned not null ,
det_high_selective_column int (10) unsigned not null ,
det_low_selective_column int (10) unsigned not null ,
constraint pk_entity_and_details primary key (entt_entt_id, edet_edet_id)
)
engine = innodb;
insert into entity_and_details(entt_entt_id,
edet_edet_id,
order_column,
high_selective_column,
low_selective_column,
det_high_selective_column,
det_low_selective_column
)
select entt_id,
edet_id,
order_column,
high_selective_column,
low_selective_column,
det_high_selective_column,
det_low_selective_column
from entity_details ed, entity e
where ed.entt_entt_id = e.entt_id;
create index idx_entity_and_details_low_date
on entity_and_details(low_selective_column, order_column);
create index idx_entity_and_details_det_low_date
on entity_and_details(det_low_selective_column, order_column);
create index idx_entity_and_details_date
on entity_and_details(order_column);
create index idx_entity_and_details_high
on entity_and_details(high_selective_column);
create index idx_entity_and_details_det_high
on entity_and_details(det_high_selective_column);
Unfortunately, after denormalization, we got one drawback. Page layout can scatter the details of one entity across different pages. We cannot allow this, so I propose to set up churches further. Instead of selecting all the necessary data at once - we select only the identifiers of the entity A, with the condition of all the criteria, add to the limit design for paging, and then pick up the details of the entity.
select distinct entt_entt_id
from entity_and_details
where det_low_selective_column = 0
order by order_column
limit 0, 3;
select *
from entity_and_details
where entt_entt_id in (10, 20, 30);
I admit honestly, in my mind, the construction of the form of distinct + order by + limit according to the table of such volumes cannot work quickly, however, the MySQL developers think differently. When working on this issue, I came across a bug Not Not BUG # 33087 , which, as usual, turned out to be not a bug, but a feature. After that, I decided to understand how MySQL optimizes distinct . The first phrase in the documentation was: to optimize distinct , all the same optimizations that are used for group by can be used. Total grouping can be performed by two algorithms.
The first case can be applied only if there is an index that sets the grouping automatically. The second scheme is used in all other cases. The index grouping is performed sequentially and can be limited - and this is very good for us, since this is exactly what we need to display the results on low selective indices. Temporary tables with this approach are not used (to be honest, this is not entirely true, since in general you need to store the results of the partial join, as well as the values themselves resulting from the grouping for the current group, but these are trifles). The second scheme works terribly slowly and eats a bunch of RAM, since all the results of the grouping should be stored in a temporary table, the primary key in which is the group identifier. For very large values, this table is converted to MyISAM and flushed to disk. All new groups are first searched in this large table, and then they change the values in it, if necessary, or add a new line if the group is not found. Final sorting finishes the performance of this algorithm. It is for this reason that if you do not need an ordered set, it is often recommended to add order by null .
Thus, the first approach, as well as the fact that MySQL stops further data retrieval if the limit construction is used together with distinct , and allows us to get the result of grouping very quickly.
Now about the unpleasant
So, we got an algorithm that quickly finds the first records, but this algorithm cannot calculate the total number of records. As a workaround, you can return one more entry so that the Next button appears on the screen.
MySQL cannot use more than one index in a query for a single table. What does it threaten us with? Let's try to execute the query type:
select distinct entt_entt_id
from entity_and_details
where det_low_selective_column = 0 and low_selective_column = 1
order by order_column
limit 0, 3;Believe you will not wait for it to end, because if you look at the data, you will see a specially formed failure there. The set satisfying the criterion det_low_selective_column = 0 has no intersections with the set satisfying the criterion low_selective_column = 1 . We know this, but unfortunately, MySQL knows nothing about it. Therefore, he chooses an index, which in his opinion is most suitable for scanning and makes a full scan of 2 indexes, selected and PK. This is deadly for a long time since scanning the primary key is actually a full table scan due to its cluster organization. All such gaps must be routed to multiple indices.
And finally, the most embarrassing moment. InnoDB uses only one mutex for each index. Therefore, when you alternately run queries that write and read data at the same time, the InnoDB engine locks the index, suspending read operations, since a write operation can cause B-Tree splitting and the records you are looking for may end up on another page. Smart databases do not block the entire tree, but only its split part. In MySQL, this algorithm is not yet implemented (although you can see the InnoDB plugin on this topic, in 5.5 it seems to have become a standard, maybe things are not so bad there). In order to get around this problem, you need to separate the data, that is, use partitions. All indexes in partition tables are locally partitioned, in fact, each partition in this regard is a separate table, but partitioning is another story and I will not touch on it in this article.
')
Conclusion
The solution of a number of problems that the harsh reality gives us is impossible to describe in two words. The problem of multi-criteria search in several sets is one of them. You can use the Sphinx and download a number of templates provided by this community, but sooner or later you will still encounter a problem to which no one has come up with a solution. And so, then you have to go into the documentation, study the data and persuade users not to do it. I hope this review article will allow you to avoid some of the pitfalls that await you on this thorny path.
ZY a number of optimizations for group by had to be omitted, since the article was already very large. You can read about them in the official documentation , as well as a number of practical tips , to fully understand the issues.
* All code sources were highlighted with Source Code Highlighter .
Source: https://habr.com/ru/post/125428/
All Articles