Asterisk + UniMRCP + VoiceNavigator. Synthesis and speech recognition in Asterisk. Part 1
Part 2
Part 3
Part 4
Considering the increased community interest in Asterisk, I decided to make my own contribution and talk about building voice menus using speech synthesis and recognition.
The article is designed for professionals who have experience with the construction of IVR in Asterisk and have an understanding of voice self-service systems.
')
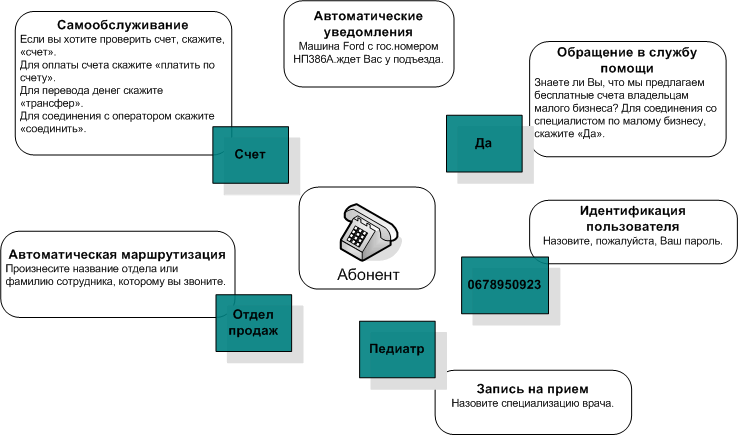
The GHS (voice self-service systems) significantly expands the possibilities for creating voice applications and allows the user to receive information and order services independently, without the participation of the operator. It can be call routing, inquiry and delivery of information on the flight schedule, bank account status, taxi order, appointment to the doctor, etc.
Recognition allows you to opt out of linear menus created using DTMF, talk to the human language system and easily create multiple-choice menus.
Synthesis greatly simplifies working with dynamically changing information and large amounts of textual data.
Below I will describe the integration of Asterisk with VoiceNavigator , since I am an employee of the company developing it and I am engaged in, among other things, support and integration with small platforms (Asterisk, FreeSWITCH). I must say that the decision is paid. There are no really working OpenSource applications for the synthesis and recognition of Russian speech.
The industry accepted standard for implementing the synthesis and recognition functionality is the use of the MRCP protocol.
Asterisk uses the UniMRCP library for this.
UniMRCP is an open source, cross-platform software that includes the necessary tools to implement the functions of the MRCP client and the MRCP server.
The project is slowly developing and, as far as I know, this is the only OpenSource solution for working with the MRCP protocol today. Supports Asterisk (all versions starting from 1.4) and FreeSWITCH.
VoiceNavigator is a software package that is installed on a separate Windows machine and provides access to the synthesis and recognition engines via the MRCP protocol.
Includes STC MRCP Server, STC TTS speech synthesis complex and STC ASR speech recognition complex.
The MRCP server manages the interaction between the voice platform used and the ASR and TTS modules. STC MRCP Server supports the following voice platforms: Asterisk, FreeSWITCH, Avaya Voice Portal, Genesys Voice Platform, Cisco Unified CCX, Siemens OpenScape.
MRCP requests are transmitted by RTSP protocol commands.
RTP is used to transfer audio data.
The voice platform through the MRCP server requests access to speech recognition and synthesis modules, depending on which different interaction schemes are used.
The ASR module is engaged in speech recognition. The key concept for ASR is SRGS grammar .
SRGS (speech recognition grammar specification) is a standard that describes the structure of the grammar used in speech recognition. SRGS allows you to specify words or phrases that can be recognized by the speech engine.
Creating grammars is a separate science and, if there is interest, I am ready to write a separate article.
The TTS module uses Speech Synthesis Markup Language ( SSML ) based on XML for use in speech synthesis applications.
Control of synthesis occurs with the help of tags. With their help, you can determine the pronunciation, control intonation, speed, volume, pause length, reading rules, etc.
An example of speech synthesis from the MDGs can be heard here at vitalvoice.ru/demo
The call arrives on the voice platform.
The voice platform activates the voice menu script, by which further interaction with the subscriber takes place.
The scenario of the voice menu determines when the system should read the instruction to the subscriber, ask a question and how to process his answer.
VoiceNavigator accepts speech recognition and speech synthesis requests from the voice platform, performs them and returns the result of the execution using the MRCP protocol.
In speech recognition, the voice platform transmits SRGS grammar and digitized speech and receives the answer in the form of NLSML .
During speech synthesis, the voice platform transmits plain-text or SSML and receives synthesized speech in response.
Let's move on to the practical part.
The following describes the installation of UniMRCP on the native Asterisk CentOS. When installing on other operating systems may be minor differences.
We download the latest version of uni-ast-package-0.3.2 from the official site.
Package contains:
• Asterisk version 1.6.2.9 - the operation with this version has been verified by the UniMRCP developer;
• Asterisk-UniMRCP-Bridge 0.1.0 - a bridge for interfacing an Asterisk and a UniMRCP module;
• UniMRCP - Module UniMRCP 1.0.0;
• APR - Apache Portable Runtime 1.4.2;
• APR-Util - Apache Portable Runtime Utility Library 1.3.9;
• Sofia-SIP - SIP User-Agent library 1.12.10.
Requires autoconf, libtool, gcc, pkg-config for installation.
After unpacking, we see three scripts in the root of the folder:
ast-install.sh - installs the supplied Asterisk if it is not installed on the system.
uni-install.sh - installs UniMRCP
connector-install.sh - installs a bridge between Asterisk and UniMRCP.
We run them in that order (if Asterisk is installed - ast-install.sh is not needed) and answer all questions in the affirmative.
We are looking for everything to be established without errors.
In my experience, errors only happen when dependencies are not satisfied. If Asterisk was previously collected from source, then all dependencies should already be satisfied and the installation will be easy and fast.
After installation, Asterisk has 2 new modules res_speech_unimrcp.so and app_unimrcp.so, and the dialplan has got the commands MRCPSynth and MRCPRecog. You can verify the installation by typing Asterisk in the console:
Before you can work with the resources of synthesis and recognition, you must connect them. To connect to the MRCP server, the file /etc/asterisk/mrcp.conf is used. You can edit its content or replace it with the following (comments added to clarify the most important parameters):
After restarting Asterisk, the profile will be activated and the system is ready to work and create the first voice application.
As described earlier, Asterisk uses the functions MRCPSynth and MRCPRecog of the app_unimrcp.so library to work:

The MRCPSynth function has the following format:
MRCPSynth (text, options), where
text - text for synthesis (text \ SSML),
options - synthesis options.
Synthesis parameters:
p - The connection profile to the synthesis resource contained in the mrcp.conf file
i - Numbers, by pressing which on the phone, the synthesis will be interrupted
f - File name for recording synthesized speech (recording is made in raw, recording is not made if a parameter or file name is not specified)
v - Voice that needs to be synthesized, for example, “Maria8000”.
plain-text:
SSML:
The advantage of using SSML compared to plain-text is the ability to use different tags (voice, speed and expressiveness of speech, pauses, text interpretation, etc.).
The MRCPRecog function has the following format:
MRCPRecog (grammar, options), where
grammar - grammar (URL \ SRGS), is specified by a link to a file located on the http-server or directly in the function body.
options - recognition options.
Recognition parameters:
p - Recognition Resource Connection Profile contained in the mrcp.conf file
i - Digits of the DTMF code, upon receipt of which the recognition will be interrupted.
If the value is “any” or other characters, recognition will be interrupted when they are received, and the character will be returned to the dial plan.
f - The name of the file to play as an invitation.
b - Ability to interrupt the playing file (barge-in mode) and start recognition (you cannot kill = 0, you can kill and speech detection is performed by ASR engine = 1, you can kill and speech detection is performed by Asterisk = 2)
t - The time after which the recognition system can interrupt the recognition procedure with the recognition-timeout (003) code, in case the recognition has started, and there is not a single recognition option. The value is specified in milliseconds in the range [0..MAXTIMEOUT].
ct - Confident Recognition Threshold (0.0 - 1.0).
If the confidence-level returned during recognition is less than the confidence-threshold, then the recognition result is no match.
sl - Sensitivity to non-vocabulary commands. (0.0 - 1.0). The larger the value, the higher the sensitivity to noise.
nb - Specifies the number of recognition results returned. Returns N recognition results, with a confidence level greater than confidence-threshold. The default value is 1.
nit - The time after which the recognition system may interrupt the recognition procedure, with the code no-input-timeout (002), in case recognition has started and no speech has been found. The value is specified in milliseconds, in the range [0..MAXTIMEOUT].
The grammar assignment in the function body:
Reference to grammar:
The parameters f = hello & b = 1 provide sounding of the sound file, for example, “Speak a number from 1 to 100”, which can be interrupted using the barge-in, i.e. start talking, without having heard the message to the end and thereby start the recognition process.
The recognition result is returned to Asterisk as NLSML in the $ {RECOG_RESULT} variable.
Sample answer:
The most important parameters in this output are:
Recognition result = "eight"
Confidence Level = 90
Semantic tag: 8
At the initial stage, the application logic can be built using REGEX, for example
More correct is the use of the NLSML parser.
The parser that comes with VoiceNavigator is an Perl AGI script. You can pass it the value of the variable exten => s, n, AGI (NLSML.agi, $ {QUOTE ($ {RECOG_RESULT})}) and as a result get the variables $ {RECOG_UTR0} = eight, $ {RECOG_INT0} = 8, $ { RECOG_CNF0} = 90.
In the next series, we will discuss in more detail the synthesis tags used and the construction of recognition grammars.
Waiting for your questions and comments.
Part 3
Part 4
Considering the increased community interest in Asterisk, I decided to make my own contribution and talk about building voice menus using speech synthesis and recognition.
The article is designed for professionals who have experience with the construction of IVR in Asterisk and have an understanding of voice self-service systems.
')
The GHS (voice self-service systems) significantly expands the possibilities for creating voice applications and allows the user to receive information and order services independently, without the participation of the operator. It can be call routing, inquiry and delivery of information on the flight schedule, bank account status, taxi order, appointment to the doctor, etc.
Recognition allows you to opt out of linear menus created using DTMF, talk to the human language system and easily create multiple-choice menus.
Synthesis greatly simplifies working with dynamically changing information and large amounts of textual data.
Below I will describe the integration of Asterisk with VoiceNavigator , since I am an employee of the company developing it and I am engaged in, among other things, support and integration with small platforms (Asterisk, FreeSWITCH). I must say that the decision is paid. There are no really working OpenSource applications for the synthesis and recognition of Russian speech.
Synthesis and recognition of Russian speech in Asterisk
The industry accepted standard for implementing the synthesis and recognition functionality is the use of the MRCP protocol.
Asterisk uses the UniMRCP library for this.
UniMRCP is an open source, cross-platform software that includes the necessary tools to implement the functions of the MRCP client and the MRCP server.
The project is slowly developing and, as far as I know, this is the only OpenSource solution for working with the MRCP protocol today. Supports Asterisk (all versions starting from 1.4) and FreeSWITCH.
VoiceNavigator
VoiceNavigator is a software package that is installed on a separate Windows machine and provides access to the synthesis and recognition engines via the MRCP protocol.
Includes STC MRCP Server, STC TTS speech synthesis complex and STC ASR speech recognition complex.
MRCP server
The MRCP server manages the interaction between the voice platform used and the ASR and TTS modules. STC MRCP Server supports the following voice platforms: Asterisk, FreeSWITCH, Avaya Voice Portal, Genesys Voice Platform, Cisco Unified CCX, Siemens OpenScape.
MRCP requests are transmitted by RTSP protocol commands.
RTP is used to transfer audio data.
The voice platform through the MRCP server requests access to speech recognition and synthesis modules, depending on which different interaction schemes are used.
ASR
The ASR module is engaged in speech recognition. The key concept for ASR is SRGS grammar .
SRGS (speech recognition grammar specification) is a standard that describes the structure of the grammar used in speech recognition. SRGS allows you to specify words or phrases that can be recognized by the speech engine.
Creating grammars is a separate science and, if there is interest, I am ready to write a separate article.
Tts
The TTS module uses Speech Synthesis Markup Language ( SSML ) based on XML for use in speech synthesis applications.
Control of synthesis occurs with the help of tags. With their help, you can determine the pronunciation, control intonation, speed, volume, pause length, reading rules, etc.
An example of speech synthesis from the MDGs can be heard here at vitalvoice.ru/demo
Scheme of work
The call arrives on the voice platform.
The voice platform activates the voice menu script, by which further interaction with the subscriber takes place.
The scenario of the voice menu determines when the system should read the instruction to the subscriber, ask a question and how to process his answer.
VoiceNavigator accepts speech recognition and speech synthesis requests from the voice platform, performs them and returns the result of the execution using the MRCP protocol.
In speech recognition, the voice platform transmits SRGS grammar and digitized speech and receives the answer in the form of NLSML .
During speech synthesis, the voice platform transmits plain-text or SSML and receives synthesized speech in response.
Installing and Configuring UniMRCP
Let's move on to the practical part.
The following describes the installation of UniMRCP on the native Asterisk CentOS. When installing on other operating systems may be minor differences.
We download the latest version of uni-ast-package-0.3.2 from the official site.
Package contains:
• Asterisk version 1.6.2.9 - the operation with this version has been verified by the UniMRCP developer;
• Asterisk-UniMRCP-Bridge 0.1.0 - a bridge for interfacing an Asterisk and a UniMRCP module;
• UniMRCP - Module UniMRCP 1.0.0;
• APR - Apache Portable Runtime 1.4.2;
• APR-Util - Apache Portable Runtime Utility Library 1.3.9;
• Sofia-SIP - SIP User-Agent library 1.12.10.
Requires autoconf, libtool, gcc, pkg-config for installation.
After unpacking, we see three scripts in the root of the folder:
ast-install.sh - installs the supplied Asterisk if it is not installed on the system.
uni-install.sh - installs UniMRCP
connector-install.sh - installs a bridge between Asterisk and UniMRCP.
We run them in that order (if Asterisk is installed - ast-install.sh is not needed) and answer all questions in the affirmative.
We are looking for everything to be established without errors.
In my experience, errors only happen when dependencies are not satisfied. If Asterisk was previously collected from source, then all dependencies should already be satisfied and the installation will be easy and fast.
After installation, Asterisk has 2 new modules res_speech_unimrcp.so and app_unimrcp.so, and the dialplan has got the commands MRCPSynth and MRCPRecog. You can verify the installation by typing Asterisk in the console:
*CLI> module show like mrcp
Module Description Use Count
res_speech_unimrcp.so UniMRCP Speech Engine 0
app_unimrcp.so MRCP suite of applications 0
2 modules loadedBefore you can work with the resources of synthesis and recognition, you must connect them. To connect to the MRCP server, the file /etc/asterisk/mrcp.conf is used. You can edit its content or replace it with the following (comments added to clarify the most important parameters):
[general]
; ASR TTS, .
; MRCP-
default-asr-profile = vn-internal
default-tts-profile = vn-internal
; UniMRCP logging level to appear in Asterisk logs. Options are:
; EMERGENCY|ALERT|CRITICAL|ERROR|WARNING|NOTICE|INFO|DEBUG -->
log-level = DEBUG
max-connection-count = 100
offer-new-connection = 1
; rx-buffer-size = 1024
; tx-buffer-size = 1024
; request-timeout = 60
;
[vn-internal]
; +++ MRCP settings +++
; MRCP-
version = 1
;
; +++ RTSP +++
; === RSTP settings ===
; MRCP-
server-ip = 192.168.2.106
;, VoiceNavigator
server-port = 8000
; force-destination = 1
; MRCP-
;( VoiceNavigator – )
resource-location =
; VoiceNavigator
speechsynth = tts
speechrecog = asr
;
; +++ RTP +++
; === RTP factory ===
;IP- , Asterisk RTP-.
rtp-ip = 192.168.2.104
; rtp-ext-ip = auto
; RTP-
rtp-port-min = 32768
rtp-port-max = 32888
; === RTP settings ===
; --- Jitter buffer settings ---
playout-delay = 50
; min-playout-delay = 20
max-playout-delay = 200
; --- RTP settings ---
ptime = 20
codecs = PCMU PCMA L16/96/8000
; --- RTCP settings ---
rtcp = 1
rtcp-bye = 2
rtcp-tx-interval = 5000
rtcp-rx-resolution = 1000After restarting Asterisk, the profile will be activated and the system is ready to work and create the first voice application.
As described earlier, Asterisk uses the functions MRCPSynth and MRCPRecog of the app_unimrcp.so library to work:
MRCPSynth
The MRCPSynth function has the following format:
MRCPSynth (text, options), where
text - text for synthesis (text \ SSML),
options - synthesis options.
Synthesis parameters:
p - The connection profile to the synthesis resource contained in the mrcp.conf file
i - Numbers, by pressing which on the phone, the synthesis will be interrupted
f - File name for recording synthesized speech (recording is made in raw, recording is not made if a parameter or file name is not specified)
v - Voice that needs to be synthesized, for example, “Maria8000”.
An example of using the function in dialplan
plain-text:
exten => 7577,n,MRCPSynth( ) SSML:
exten => 7577,MRCPSynth(<?xml version=\"1.0\"?><speak version=\"1.0\" xml:lang=\"ru-ru\" xmlns=\"http://www.w3.org/2001/10/synthesis\"><voice name=\"8000\"> .</voice></speak>) The advantage of using SSML compared to plain-text is the ability to use different tags (voice, speed and expressiveness of speech, pauses, text interpretation, etc.).
MRCPRecog
The MRCPRecog function has the following format:
MRCPRecog (grammar, options), where
grammar - grammar (URL \ SRGS), is specified by a link to a file located on the http-server or directly in the function body.
options - recognition options.
Recognition parameters:
p - Recognition Resource Connection Profile contained in the mrcp.conf file
i - Digits of the DTMF code, upon receipt of which the recognition will be interrupted.
If the value is “any” or other characters, recognition will be interrupted when they are received, and the character will be returned to the dial plan.
f - The name of the file to play as an invitation.
b - Ability to interrupt the playing file (barge-in mode) and start recognition (you cannot kill = 0, you can kill and speech detection is performed by ASR engine = 1, you can kill and speech detection is performed by Asterisk = 2)
t - The time after which the recognition system can interrupt the recognition procedure with the recognition-timeout (003) code, in case the recognition has started, and there is not a single recognition option. The value is specified in milliseconds in the range [0..MAXTIMEOUT].
ct - Confident Recognition Threshold (0.0 - 1.0).
If the confidence-level returned during recognition is less than the confidence-threshold, then the recognition result is no match.
sl - Sensitivity to non-vocabulary commands. (0.0 - 1.0). The larger the value, the higher the sensitivity to noise.
nb - Specifies the number of recognition results returned. Returns N recognition results, with a confidence level greater than confidence-threshold. The default value is 1.
nit - The time after which the recognition system may interrupt the recognition procedure, with the code no-input-timeout (002), in case recognition has started and no speech has been found. The value is specified in milliseconds, in the range [0..MAXTIMEOUT].
An example of using the function in dialplan
The grammar assignment in the function body:
exten => 7577,n,MRCPRecog(<?xml version=\"1.0\"?><grammar xmlns=\"http://www.w3.org/2001/06/grammar\" xml:lang=\"ru-ru\" version=\"1.0\" mode=\"voice\" root=\"test\"><rule id=\"test\"><one-of><item></item><item></item><item></item><item></item><item></item><item></item><item></item><item></item><item></item></one-of></rule></grammar>,f=hello&b=1) Reference to grammar:
exten => 7577,n,MRCPRecog(http://192.168.1.1/digits.xml,f=hello&b=1) The parameters f = hello & b = 1 provide sounding of the sound file, for example, “Speak a number from 1 to 100”, which can be interrupted using the barge-in, i.e. start talking, without having heard the message to the end and thereby start the recognition process.
The recognition result is returned to Asterisk as NLSML in the $ {RECOG_RESULT} variable.
Sample answer:
<?xml version="1.0"?><result grammar="C:\Documents and Settings\All Users\Application Data\Speech Technology Center\Voice Digger\temp\e856d208-7794-43b0-bb89-01947e37e655.slf"><interpretation confidence="90" grammar="C:\Documents and Settings\All Users\Application Data\Speech Technology Center\Voice Digger\temp\e856d208-7794-43b0-bb89-01947e37e655.slf"><input mode="speech" confidence="90" timestamp-start="2011-07-04T0-00-00" timestamp-stop="2011-07-04T0-00-00"></input><instance confidence="90"><SWI_literal></SWI_literal><SWI_grammarName>C:\Documents and Settings\All Users\Application Data\Speech Technology Center\Voice Digger\temp\e856d208-7794-43b0-bb89-01947e37e655.slf</SWI_grammarName><SWI_meaning>8</SWI_meaning></instance></interpretation></result> The most important parameters in this output are:
Recognition result = "eight"
Confidence Level = 90
Semantic tag: 8
At the initial stage, the application logic can be built using REGEX, for example
exten => 8800,5,GotoIf(${REGEX("" ${RECOG_RESULT})}?100:10) More correct is the use of the NLSML parser.
The parser that comes with VoiceNavigator is an Perl AGI script. You can pass it the value of the variable exten => s, n, AGI (NLSML.agi, $ {QUOTE ($ {RECOG_RESULT})}) and as a result get the variables $ {RECOG_UTR0} = eight, $ {RECOG_INT0} = 8, $ { RECOG_CNF0} = 90.
An example of a simple voice number recognition application.
exten => 7577,1,Answer exten => 7577,n,MRCPSynth( . ) exten => 7577,n,MRCPRecog(<?xml version=\"1.0\"?><grammar xmlns=\"http://www.w3.org/2001/06/grammar\" xml:lang=\"ru-ru\" version=\"1.0\" mode=\"voice\" root=\"test\"><rule id=\"test\"><one-of><item></item><item></item><item></item></one-of></rule></grammar>,f=beep&b=1) exten => 7577,n,GotoIf(${REGEX("" ${RECOG_RESULT})}?one:if_2) exten => 7577,n(if_2),GotoIf(${REGEX("" ${RECOG_RESULT})}?two:if_3) exten => 7577,n(if_3),GotoIf(${REGEX("" ${RECOG_RESULT})}?three:error) exten => 7577,n(one),MRCPSynth( ) exten => 7577,n,Hangup exten => 7577,n(two),MRCPSynth( ) exten => 7577,n,Hangup exten => 7577,n(three),MRCPSynth( ) exten => 7577,n,Hangup exten => 7577,n(error),MRCPSynth( ) exten => 7577,n,Hangup In the next series, we will discuss in more detail the synthesis tags used and the construction of recognition grammars.
Waiting for your questions and comments.
Source: https://habr.com/ru/post/124946/
All Articles