Frequency analysis of the Ukrainian language
 It took me for a good cause a table of frequencies of pairs of letters (so-called bigrams or digrams) for the Ukrainian language. And not just the Ukrainian language, but a modern, lively Internet language, the name of the one on which modern communication takes place in the Ukrainian-speaking environment. The only results I knew were built on a rather small sample, different from what I needed, and a serious transformation of the text in them could affect the result (and probably did, but more on that later).
It took me for a good cause a table of frequencies of pairs of letters (so-called bigrams or digrams) for the Ukrainian language. And not just the Ukrainian language, but a modern, lively Internet language, the name of the one on which modern communication takes place in the Ukrainian-speaking environment. The only results I knew were built on a rather small sample, different from what I needed, and a serious transformation of the text in them could affect the result (and probably did, but more on that later).The task in general is not difficult, the only serious problem is the source of the material for processing - the largest piece of text that can be shoveled.
The first idea was to dump a piece of some IRC channel. Unfortunately, I did not find a single active live flame with a cut-off on the tongue.
')
The next idea: a forum.
As a victim, several large Ukrainian-language forums were chosen. All admins reacted negatively to the request for a dump of the text part of the database, and some even quite sharply ...
... Themselves to blame, I said, and launched wget.
Actually there were no special problems. Make sure that wget only pulls what it needs (only forum pages, not pages of individual messages - there was such an option on the victim forum), a bit to pull up knowledge of powershell, but to overload a ton of received pages from html in xhtml somewhere found by the utility of the same name, again, a little tighten up xslt in order to scoop up the necessary text elements, and at the same time cut quotes, as well as repeated elements. The result of this case could already be analyzed, for which a small C # program was created. In general, it all took two weeks a few minutes-hours a day.
A little about the results.
With the help of wget, about two gigabytes of pure html were downloaded, which took about one and a half days (or rather I will not say, there are no files anymore :))
After the cut-off of all auxiliary pages, indexes, contents and forums, the distillation in xhtml and the cut-off of files containing errors, 49492 files were obtained with a total size of 2.2GB.
After the xslt run, the number of files did not change, but the volume decreased significantly - up to 160MB, while the remaining part of the xslt is still a large part of this volume. The net size after removing double whitespace characters, the actual base of the processed text is 65,525,151 characters, more than 10 times more than in the previous study.
Actually the result can be viewed here . There are four files in the archive: processed and raw digram and monogram results, respectively. From the processed results, all non-relevant Ukrainian alphabet characters were thrown out + the digram result was turned into a table. If we compare with previous results, we see differences in the top ten. The only assumption of such a difference is that in the mentioned study the forms were canonized.
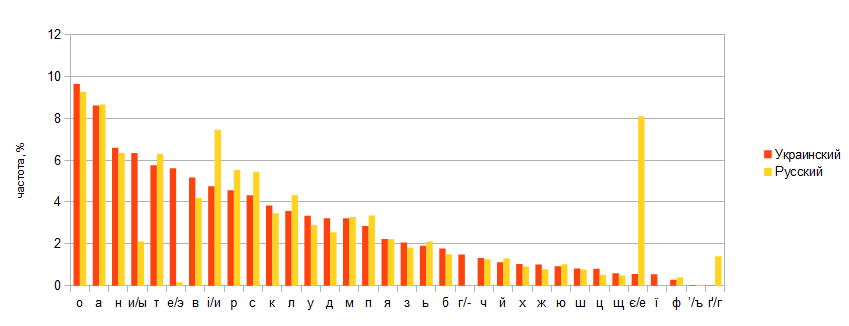
The figure below shows a comparative graph of the frequencies of letters in Russian and Ukrainian languages according to the phonetic criterion:
Open questions.
1. Cut-off of inclusions in third-party languages. Basically - Russian, English. They are few, but still noticeable. Even assuming that you can cut a fast by the presence of letters from other alphabets in it, you still cannot guarantee the accuracy of the result. You can write a rather long string in Russian, which will not contain a single character missing in the Ukrainian alphabet. And the previous four sentences are in confirmation.
2. Rare symbols "ґ" and "'" (apostrophe). The first one is almost universally replaced by “g”, since “ґ” is absent on most keyboards as a class, and the method of dialing through AltGr is practically unknown. Moreover, the letter is very rare in itself, and many people are not used to it (it was returned to the alphabet in 1990).
As an apostrophe (an analogue of the Russian hard sign), the single quotation mark '' 'is mainly used (which is typographically wrong), but since it is not in the layouts on older versions of Windows, and in new ones it is very obvious to be escaped, either on any other suitable (or not) symbol, for example an asterisk. In the analysis, I took a single quote as an apostrophe, but the results in the tables clearly show that it is used not only as an apostrophe (according to the rules, the apostrophe should follow b, n, v, m, f, p and before i, y, , ї. The table also shows many other occurrences).
Conclusion
I hope the results posted in the topic will be needed or interesting to someone.
... Well, at the same time I will be happy with the ideas of solving two open problems.
Source: https://habr.com/ru/post/124553/
All Articles