DoS vulnerability in Open vSwitch
Spoiler: Open vSwitch versions less than 1.11 are vulnerable to a flow flow attack, which allows an attacker to interrupt the network by sending a relatively small packet flow to any virtual machine. Versions 1.11 and older are not affected. Most servers with OVS still use OVS 1.4 or 1.9 (LTS versions). Administrators of such systems are urged to upgrade the system to a newer version of OVS.
Lyrics: More than a year and a half has passed since the moment when I first managed to reproduce this problem. In the OVS mailing list to the complaint, they said that “they will fix it in the next versions” - and have corrected it, half a year later. However, this fix did not affect the LTS version, which means that most systems using OVS are still vulnerable. I tried to contact Citrix several times (because it uses the most vulnerable version of OVS as part of Xen Server - at that moment it was my main product for operation), but there was no clear reaction. Now administrators have the opportunity to eliminate the problem with a little blood, so I decided to publish a description of a very simple to reproduce and extremely confusing and diagnosing problem - the problem of “flow congestion”, it’s also “flow flow attack”, it’s also “a strange unknown garbage “for which everything works strangely.” I have written several times before in the comments and mailings about this problem, but I never had enough powder to fully describe the problem in Russian so that the essence of the problem was understandable to an ordinary IT person. Correct.
The next line
')
A more severe version of the same call, this time in violation of the rules for using the network:
Symptoms from the virtualization host side: unexpected delays when opening connections, increase in CPU consumption by the ovs-vswitchd process up to 100%, packet loss for new or low-activity sessions. If OVS 1.4 is used, the ovs-vswitchd process not only eats its 100% CPU, but also starts eating up memory and does it at a speed of up to 20 megabytes per minute, until a good OOM grandfather comes to him and does not conduct an educational conversation.
In contrast to the usual problems with the network, launched pings are likely to “break through”, and as soon as the flow with them gets into the kernel, ping will work without the slightest criticism, but the new connections will not be established. This makes it very difficult to diagnose the problem, because the psychological “ping is - the network is working” is very difficult to get rid of. If we add to this that the “broken through” ssh session per host will continue to work just as well, then it will be extremely and extremely difficult to convince the administrator that the problem with the network on the part of the host is. If the flood on the interface exceeds a certain threshold (~ 50-80 Mb / s), then any adequate network activity is terminated. But the insidiousness of the described problem is that a significant degradation of the service occurs at much lower loads, under which the canonical network diagnostic tools report “everything is in order”.
Taking this opportunity, I want to apologize to si14 , who spoke about the strangeness with the network of laboratory virtual women, but could not prove their presence to me, but I “saw” that I was fine and it took more than a year until I finally not only I suspected something was wrong, but I was able to find an unambiguous crash test.
In the case of XenServer, the situation with OVS is complicated by the fact that local management traffic also goes through the Open vSwitch bridge, and all bridges are served by one ovs-vswitchd process, that is, a happy administrator will not even be able to look at these symptoms - they simply will not allow ssh . And if they let them in, then see above, about “no problems”. Since NAS / SAN traffic also goes through the bridge, even after the causes disappear, the virtual machines are likely to remain inoperable. In this case, the symptoms of the problem are “an unexpected hangup that began with lags and packet loss.”
Description of the vulnerability from the point of view of a “production manager” - any schoolchild with a 10-50 megabit channel on ADSL can put an entire farm of virtualization servers with ten-gigabit ports if at least one virtual user is “watching” the interface on the Internet. And the rules / ACL inside virtuals will hardly help. Any user of any virtual machine, even without access to the Internet, can arrange the same.
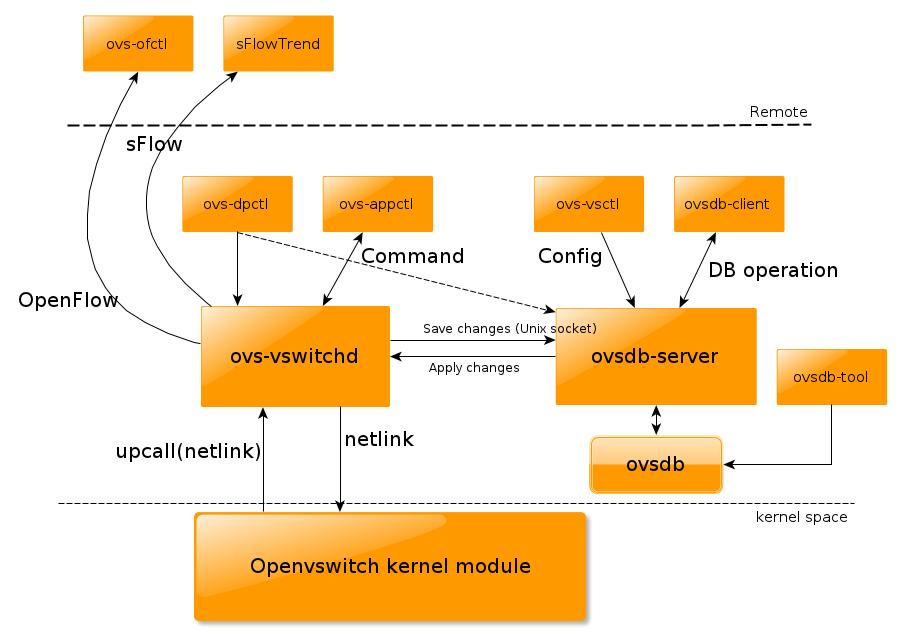
(illustration from post An overview of Openvswitch implementation )
Reason: Older versions of Open vSwitch cannot merge similar flow and when detecting an ethernet frame that looks like a new flow, they always send a frame for inspection via the netlink socket to the ovs-vswitchd process. Since the inspection process is extremely slow (due to the overwhelming speed of hash tables in the core), and ovs-vswitchd itself is single-threaded and the only one in the system, then network performance under the conditions of the emergence of many new flows is limited by the speed of the userspace application (and its circulation to the core / back via netlink). After a short time, the existing kernel flows are replaced by new entries and displace existing ones (unless they are very active), and the chances of restoring a new flow are inversely proportional to the number of competitors — that is, to flood. Moreover, the number of packets in a bona fide session does not play any role - the whole session turns out to be a single flow. For a long time this was the “blind spot” - any burst test with a single TCP session happily reported gigabits of traffic with almost zero processor utilization.
The key is to understand the difference between kernel flow and openflow flow. Openflow flow implies that flow is accompanied by a bitmask, more precisely, the openflow format implies an indication of the fields of interest. At the same time for the rest of the fields implicitly implied "not important", that is, "*".
The kernel module in older versions of Open vSwitch uses a fairly sophisticated rule-handling mechanism, which has only one drawback: it does not support masks and asterisks.
The mechanism is as follows: the incoming ethernet frame selects all its headers, starting with L2 and ending with L4 (that is, for example, TCP port number), minus completely useless, like "window size" for TCP, or "segment number ". All of them are packed into a binary structure, after which a hash is considered from this structure. Then this hash is searched for in the rules hash table, and if there is a match for the rule, it is used. If none matches, the package is sent for inspection to a more intelligent userpace program (ovs-vswitchd), which sends back a new rule for what to do with such packages. The rules for openflow, as well as manually imposed rules via ovs-ofctl, are processed by ovs-vswitchd, and the kernel module does not know anything about them. This is especially true of the “normal” rule, which means “act like a switch”. But even a normal drop still requires user-space inspection, because drop most often does not include all possible combinations of the incoming / outgoing port, and, therefore, from the point of view of OVS, it contains "asterisks".
The hash table gives fantastic performance that does not depend on the number of rules (that is, 10,000 rules will be processed at about the same speed as one).
Unfortunately, if the headers of each new package are different, then each new such package will go to the inspection in userspace. Which is slow and sad.
The original idea of OVS was that within the TCP session all packets would be the same and there would be one rule for the entire session. Unfortunately, the evil “hakkir Vasya”, by copying the line above, will be able to break this wait.
In new versions, this problem was solved with the help of megaflow.
They appeared in the Open vSwitch since version 1.11. Megaflow does not apply to openflow, but concerns the interaction of ovs-vswitchd and the nuclear module. Unfortunately, the price for megaflow is quite tangible - in some cases, productivity drops by 5-20%. Fortunately, in return, ovs-vswitchd will under almost no circumstances eat away a disproportionately large amount of resources.
What is megaflow? In very detail on C, it is presented here . From what I understand, the concept of “mask” appears, the masks themselves are unique to the whole kernel datapath, and when searching you have to take them all into account, that is, the complexity of the search becomes not o (1), but o (masks). From here it turns out some performance drop. But against the background of unspeakable brakes and denial of service in case of a flow flood, this is good news. And, perhaps, the only way out.
In addition, in many installations the masks will be very small, and the drop in performance will be imperceptible. For example, the unmanaged “simple switch” mode, that is, the normal, most likely, will contain a single mask.
With the fact that at the beginning of the article it was about “attack on denial of service with hping / nping”, the real problem is much wider. If for some reason there are many calls to the virtual machine from many different addresses, or simply many sessions are established, then there is no difference in terms of OVS behavior with “attack” and “high load”. I watched this in reality when a virtual machine was used to distribute statics for some terribly popular browser game containing a bunch of small pictures. There were a lot of players, there were many pictures, they were small. Total - several thousand new TCP sessions per second, 300-500 bytes in size. At the same time, a very moderate flow of 15–20 megabits was obtained. And the worst case for old versions of OVS, since each session is a walk-in user space.
An additional problem is the fact that netlink has a buffer, and network interfaces have a buffer, and OVS has a buffer. Incoming packets are not just dropping, they queue up, loading the processor at 100% (yes, 100 of the 800 available). This leads to an increase in latency in the processing of new flow. Moreover, this latency is extremely difficult to diagnose: the lag is only on the first packet, all subsequent ones (within the created flow) are processed quickly.
The rise of latency leads to the second part of the problem: if a packet from an existing TCP session is in the queue long enough, then the record of such a session is wiped from the kernel flow table. And the package again goes to the inspection, to create a new kernel flow, and this even more finishes OVS to the state “it does not breathe and does not move”.
Note that the problem is symmetrical with respect to input / output. It can be not only “hakkir Vasya” outside, but also “hakkir Vasya” inside. A virtual machine sending out thousands of new sessions outside causes the same problems - and these problems affect everyone who is close to the hakkir. If packets are sent to neighbors over the network, then a single virtual machine can become paralyzed or severely degrade the quality of service for a whole host of virtualization servers.
It is clear that for a public provider such death is like. In a previous job, I had to write a rather ugly patch that cut most of the OVS functionality (since megaflow was not there yet), leaving only the minimum possible set of parameters in binary fingerprints of the frame (from which they make the hash). Upstream is not taken, but I solved the problem. And before the release of OVS 1.11, about half a year remained with the megaflow ...
(information about the version of OVS in your favorite distribution is welcome and will be added, it is desirable to indicate the version with a link to the distribution site)
Since OVS is a recommended and standard bridge for openstack, with both opensource versions and many proprietary (they still use OVS for traffic to the virtual machine), we can say that most of the default OpenStack installations are subject to a problem. A similar problem awaits the regular installation of libvirt based on OVS - as in distributions, mainly problem versions.
Update, update, update. To the great happiness of CentOS 5 users and other connoisseurs of mammoth achievements, the OVS 1.11 nuclear module supports 2.6.18 (but not more than 3.8), so it will work on most systems. For newer kernels, it is worth using newer versions of OVS - 2.0, or even 2.1 (just released in early May 2014). The key potential problem is that if you don’t update the kernel module when updating OVS, it will not work (although the command line utilities will try to portray the functionality).
The second problem: all versions in which the vulnerability is fixed are not LTS. This means that they should be updated almost immediately, as the newer one comes out, since there is almost no support for non-LTS (and bugfixes only go to the next version).
Related Links :
PS If someone decides to check “how it works” from the virtual machine - note that after launching it is likely that you will not press Ctrl-C. More precisely, click, but the server will not hear you and will continue to send flooding to the interface, and even rebooting such a virtual machine will be difficult - if the control goes through the same bridge, then the command to shut down or reboot just does not reach the utilities on the host.
Lyrics: More than a year and a half has passed since the moment when I first managed to reproduce this problem. In the OVS mailing list to the complaint, they said that “they will fix it in the next versions” - and have corrected it, half a year later. However, this fix did not affect the LTS version, which means that most systems using OVS are still vulnerable. I tried to contact Citrix several times (because it uses the most vulnerable version of OVS as part of Xen Server - at that moment it was my main product for operation), but there was no clear reaction. Now administrators have the opportunity to eliminate the problem with a little blood, so I decided to publish a description of a very simple to reproduce and extremely confusing and diagnosing problem - the problem of “flow congestion”, it’s also “flow flow attack”, it’s also “a strange unknown garbage “for which everything works strangely.” I have written several times before in the comments and mailings about this problem, but I never had enough powder to fully describe the problem in Russian so that the essence of the problem was understandable to an ordinary IT person. Correct.
The next line
hping3 -i u10 virtual.machine.ip violates the performance of the virtualization host running the virtual machine. And not only the virtualization host - any system running on Open vSwitch versions less than 1.11. I place particular emphasis on versions 1.4.3 and 1.9, because they are LTS versions and are used most often.')
A more severe version of the same call, this time in violation of the rules for using the network:
hping3 --flood --rand-source virtual.machine.ip . The ratio of outgoing traffic (~ 10-60 Mbit / s) and the (potential) interface bandwidth of the victim (2x10G, the ratio of the attacking / attacking band in the available band is of the order of 1: 300-1: 1000) allows us to speak about the vulnerability, and not about the traditional DoS attack flood, clogging uplink channels to non-working state.Symptoms from the virtualization host side: unexpected delays when opening connections, increase in CPU consumption by the ovs-vswitchd process up to 100%, packet loss for new or low-activity sessions. If OVS 1.4 is used, the ovs-vswitchd process not only eats its 100% CPU, but also starts eating up memory and does it at a speed of up to 20 megabytes per minute, until a good OOM grandfather comes to him and does not conduct an educational conversation.
In contrast to the usual problems with the network, launched pings are likely to “break through”, and as soon as the flow with them gets into the kernel, ping will work without the slightest criticism, but the new connections will not be established. This makes it very difficult to diagnose the problem, because the psychological “ping is - the network is working” is very difficult to get rid of. If we add to this that the “broken through” ssh session per host will continue to work just as well, then it will be extremely and extremely difficult to convince the administrator that the problem with the network on the part of the host is. If the flood on the interface exceeds a certain threshold (~ 50-80 Mb / s), then any adequate network activity is terminated. But the insidiousness of the described problem is that a significant degradation of the service occurs at much lower loads, under which the canonical network diagnostic tools report “everything is in order”.
Taking this opportunity, I want to apologize to si14 , who spoke about the strangeness with the network of laboratory virtual women, but could not prove their presence to me, but I “saw” that I was fine and it took more than a year until I finally not only I suspected something was wrong, but I was able to find an unambiguous crash test.
In the case of XenServer, the situation with OVS is complicated by the fact that local management traffic also goes through the Open vSwitch bridge, and all bridges are served by one ovs-vswitchd process, that is, a happy administrator will not even be able to look at these symptoms - they simply will not allow ssh . And if they let them in, then see above, about “no problems”. Since NAS / SAN traffic also goes through the bridge, even after the causes disappear, the virtual machines are likely to remain inoperable. In this case, the symptoms of the problem are “an unexpected hangup that began with lags and packet loss.”
Description of the vulnerability from the point of view of a “production manager” - any schoolchild with a 10-50 megabit channel on ADSL can put an entire farm of virtualization servers with ten-gigabit ports if at least one virtual user is “watching” the interface on the Internet. And the rules / ACL inside virtuals will hardly help. Any user of any virtual machine, even without access to the Internet, can arrange the same.
Technical description of the problem
(illustration from post An overview of Openvswitch implementation )
Reason: Older versions of Open vSwitch cannot merge similar flow and when detecting an ethernet frame that looks like a new flow, they always send a frame for inspection via the netlink socket to the ovs-vswitchd process. Since the inspection process is extremely slow (due to the overwhelming speed of hash tables in the core), and ovs-vswitchd itself is single-threaded and the only one in the system, then network performance under the conditions of the emergence of many new flows is limited by the speed of the userspace application (and its circulation to the core / back via netlink). After a short time, the existing kernel flows are replaced by new entries and displace existing ones (unless they are very active), and the chances of restoring a new flow are inversely proportional to the number of competitors — that is, to flood. Moreover, the number of packets in a bona fide session does not play any role - the whole session turns out to be a single flow. For a long time this was the “blind spot” - any burst test with a single TCP session happily reported gigabits of traffic with almost zero processor utilization.
Kernel flow versus openflow flow
The key is to understand the difference between kernel flow and openflow flow. Openflow flow implies that flow is accompanied by a bitmask, more precisely, the openflow format implies an indication of the fields of interest. At the same time for the rest of the fields implicitly implied "not important", that is, "*".
The kernel module in older versions of Open vSwitch uses a fairly sophisticated rule-handling mechanism, which has only one drawback: it does not support masks and asterisks.
The mechanism is as follows: the incoming ethernet frame selects all its headers, starting with L2 and ending with L4 (that is, for example, TCP port number), minus completely useless, like "window size" for TCP, or "segment number ". All of them are packed into a binary structure, after which a hash is considered from this structure. Then this hash is searched for in the rules hash table, and if there is a match for the rule, it is used. If none matches, the package is sent for inspection to a more intelligent userpace program (ovs-vswitchd), which sends back a new rule for what to do with such packages. The rules for openflow, as well as manually imposed rules via ovs-ofctl, are processed by ovs-vswitchd, and the kernel module does not know anything about them. This is especially true of the “normal” rule, which means “act like a switch”. But even a normal drop still requires user-space inspection, because drop most often does not include all possible combinations of the incoming / outgoing port, and, therefore, from the point of view of OVS, it contains "asterisks".
The hash table gives fantastic performance that does not depend on the number of rules (that is, 10,000 rules will be processed at about the same speed as one).
Unfortunately, if the headers of each new package are different, then each new such package will go to the inspection in userspace. Which is slow and sad.
The original idea of OVS was that within the TCP session all packets would be the same and there would be one rule for the entire session. Unfortunately, the evil “hakkir Vasya”, by copying the line above, will be able to break this wait.
In new versions, this problem was solved with the help of megaflow.
Megaflow
They appeared in the Open vSwitch since version 1.11. Megaflow does not apply to openflow, but concerns the interaction of ovs-vswitchd and the nuclear module. Unfortunately, the price for megaflow is quite tangible - in some cases, productivity drops by 5-20%. Fortunately, in return, ovs-vswitchd will under almost no circumstances eat away a disproportionately large amount of resources.
What is megaflow? In very detail on C, it is presented here . From what I understand, the concept of “mask” appears, the masks themselves are unique to the whole kernel datapath, and when searching you have to take them all into account, that is, the complexity of the search becomes not o (1), but o (masks). From here it turns out some performance drop. But against the background of unspeakable brakes and denial of service in case of a flow flood, this is good news. And, perhaps, the only way out.
In addition, in many installations the masks will be very small, and the drop in performance will be imperceptible. For example, the unmanaged “simple switch” mode, that is, the normal, most likely, will contain a single mask.
Attack in the wild
With the fact that at the beginning of the article it was about “attack on denial of service with hping / nping”, the real problem is much wider. If for some reason there are many calls to the virtual machine from many different addresses, or simply many sessions are established, then there is no difference in terms of OVS behavior with “attack” and “high load”. I watched this in reality when a virtual machine was used to distribute statics for some terribly popular browser game containing a bunch of small pictures. There were a lot of players, there were many pictures, they were small. Total - several thousand new TCP sessions per second, 300-500 bytes in size. At the same time, a very moderate flow of 15–20 megabits was obtained. And the worst case for old versions of OVS, since each session is a walk-in user space.
An additional problem is the fact that netlink has a buffer, and network interfaces have a buffer, and OVS has a buffer. Incoming packets are not just dropping, they queue up, loading the processor at 100% (yes, 100 of the 800 available). This leads to an increase in latency in the processing of new flow. Moreover, this latency is extremely difficult to diagnose: the lag is only on the first packet, all subsequent ones (within the created flow) are processed quickly.
The rise of latency leads to the second part of the problem: if a packet from an existing TCP session is in the queue long enough, then the record of such a session is wiped from the kernel flow table. And the package again goes to the inspection, to create a new kernel flow, and this even more finishes OVS to the state “it does not breathe and does not move”.
Note that the problem is symmetrical with respect to input / output. It can be not only “hakkir Vasya” outside, but also “hakkir Vasya” inside. A virtual machine sending out thousands of new sessions outside causes the same problems - and these problems affect everyone who is close to the hakkir. If packets are sent to neighbors over the network, then a single virtual machine can become paralyzed or severely degrade the quality of service for a whole host of virtualization servers.
It is clear that for a public provider such death is like. In a previous job, I had to write a rather ugly patch that cut most of the OVS functionality (since megaflow was not there yet), leaving only the minimum possible set of parameters in binary fingerprints of the frame (from which they make the hash). Upstream is not taken, but I solved the problem. And before the release of OVS 1.11, about half a year remained with the megaflow ...
Extent of the problem
| distribution kit | OVS version | vulnerability |
| Debian sqeeze | x | no package |
| Debian wheezy | 1.4.2 | vulnerable version + memory leak |
| Debian sid | 1.9.3 | vulnerable version (here's the bleeding edge) |
| Ubuntu 12.04 | 1.4 | vulnerable version + memory leak |
| Ubuntu 14.04 | 2.0 | cheers cheers. |
| XenServer 5.5 | 1.4.2 | vulnerable version + memory leak |
| XenServer 6.2 | 1.4.3 | vulnerable version. Until now, not even 1.9! |
| RHEL / CentOS 5 | x | Package not available |
| RedHat / CentOS 6.5 | x | Only kernel module, no userspace |
| Fedora 21 | 2.1 | the freshest! |
(information about the version of OVS in your favorite distribution is welcome and will be added, it is desirable to indicate the version with a link to the distribution site)
Since OVS is a recommended and standard bridge for openstack, with both opensource versions and many proprietary (they still use OVS for traffic to the virtual machine), we can say that most of the default OpenStack installations are subject to a problem. A similar problem awaits the regular installation of libvirt based on OVS - as in distributions, mainly problem versions.
Conclusion
Update, update, update. To the great happiness of CentOS 5 users and other connoisseurs of mammoth achievements, the OVS 1.11 nuclear module supports 2.6.18 (but not more than 3.8), so it will work on most systems. For newer kernels, it is worth using newer versions of OVS - 2.0, or even 2.1 (just released in early May 2014). The key potential problem is that if you don’t update the kernel module when updating OVS, it will not work (although the command line utilities will try to portray the functionality).
The second problem: all versions in which the vulnerability is fixed are not LTS. This means that they should be updated almost immediately, as the newer one comes out, since there is almost no support for non-LTS (and bugfixes only go to the next version).
Related Links :
- Wikipedia articles: ru: Open vSwitch , en: Open vSwitch , ru: OpenFlow , en: OpenFlow
- Download Open vSwitch
- Video on the architecture of Open vSwitch
- Manual on managing flow processing in OVS
PS If someone decides to check “how it works” from the virtual machine - note that after launching it is likely that you will not press Ctrl-C. More precisely, click, but the server will not hear you and will continue to send flooding to the interface, and even rebooting such a virtual machine will be difficult - if the control goes through the same bridge, then the command to shut down or reboot just does not reach the utilities on the host.
Source: https://habr.com/ru/post/124310/
All Articles