Creating a semantic web application


As part of my graduation project, I was offered to create a system for the formation of project teams based on semantic web technologies . Since I already had naked PHP, SQL, ZF, and had experience programming in Ruby on Rails, having familiarized myself with existing gems and solutions for working with RDF, I decided to write on it, because I don’t really like Java (may Java developers forgive me), although it is the most advanced language in the field of semantic web, intelligent agents, data mining.
The first step was the study of RDF, OWL, SPARQL, arc2, rdf.rb, Spira and other technologies, standards, modules.
Compressed excursion into the Semantic web
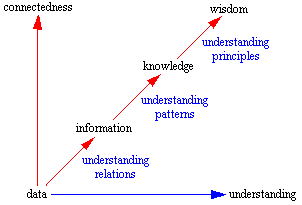 DIKW - So, we have the basic concepts - data, information, knowledge, wisdom, each of which is described with the help of the previous one and adds something that is not at the previous level. Data - the basic element of the building blocks. Information adds an answer to the question “what?”, Knowledge - “how?”, Wisdom - “why?” (Know-nothing, know-what, know-how, and know-why).
DIKW - So, we have the basic concepts - data, information, knowledge, wisdom, each of which is described with the help of the previous one and adds something that is not at the previous level. Data - the basic element of the building blocks. Information adds an answer to the question “what?”, Knowledge - “how?”, Wisdom - “why?” (Know-nothing, know-what, know-how, and know-why).It is difficult to understand, so we reformulate: Information is data + metadata (data description, data about data). Knowledge is information and rules of inference. That is, when we have knowledge, rules of inference, we can receive new information from one information.
')
If the RDF standard operates primarily with information, then OWL adds new facts to the RDF. And OWL is described on RDF, that's right.
Further, by standards - SPARQL - language queries to the repository, is very similar to SQL, but operates with triplets. There are a lot of variations on the theme of SPARQL from various manufacturers of RDF storages, just like in SQL.
nt3, turtle and others - variations on RDF / XML. That is, we represent triplets in a more convenient form for reading / writing / storage / processing.
In these standards, knowledge is described by triplets - subject, predicate, object. The subject is what we are describing, for example an apple. A predicate is a certain property of the subject, for example, “to have a color”. An object is the value of this property for a given subject, for example, "green." Thus, we can describe knowledge within the framework of RDF / OWL.
- Apple, this, class
- Yabloko1, belongs to the class, Apple
- Apple1, has color, Green
- Worm1, eating, Apple1
- Green, in RGB, 00FF00 (literal)
etc.
In this case, the subject and the predicate are always entities, and the object can be both an entity and a literal (string, number). Each entity is represented by a URI. For example, our apple is represented as
http://example.com/apples_repo.xml.rdf#our_apple1
In addition to the data itself ( ABox ), we must have metadata ( TBox ) that describe the classes, the relationships between the classes, the properties of the classes, and also, in the case of OWL, the relationships between the classes. ABox is usually stored in a repository and is a description of specific entities of this world, and TBox is usually stored in so-called ontologies . An ontology is usually an OWL or RDF file (which, in turn, can be unloaded by some repository).
Thus, in sum, we get an ontological knowledge base that describes the subject area (classes, properties, relationships) and specific essences of this subject area (people, projects, tasks, houses, goods).
And now the main question - why is all this necessary , because we can store all the same in relational / document / graph / object databases?
This area is developing and currently interesting, primarily from a scientific point of view. However, now there are means that can do what the database cannot do. Knowledge is living data. Data from which you can get new data.
If we know that Petya is the son of Masha, and Masha is Kolya’s sister, and we also know that her sister and brother are symmetrical relations, and her mother’s brother is an uncle, then we can conclude that Kolya is Uncle Petit.
In this simple example, it is clear that ontological BRs, in combination with the reasoning system ( reasoner ), can find new facts. There is also the direction of data mining ( data mining ) - adjacent to the logical conclusion of the extraction of previously unknown data. And many AI systems, expert systems work with the use of ontological BRs, since They are great for this.
We also get a distributed semantic web , knowledge from which can extract various web services and interpret them in accordance with ontologies. Imagine a bunch of social networks where information about each person can be uploaded in RDF format. This makes it possible to download and process data from all these networks. If earlier search engines and aggregators extracted text completely devoid of semantics, now they will be able to extract and process the knowledge defined by ontology.
So, let's go to practice.
With the help of Protege we model the subject area.
Ready ontologies on OWL links:
mera-max.ru/ontologies/competenceModel.rdf-xml.owl
mera-max.ru/ontologies/professionsModel.rdf-xml.owl
mera-max.ru/ontologies/staffModel.rdf-xml.owl
xmlns.com/foaf/spec
semanticweb.org/wiki/DOAP
www.semanticdesktop.org/ontologies/2008/05/20/tmo
Briefly and simplified for our application - we have people ( FOAF ), each person has an account and a set of competencies that he owns, there are projects ( DOAP ), within the project there are tasks, each of which requires a set of competencies turn have a level that has a numerical representation.
Implementation
Using Ruby 1.9.2
Using Rails 3.0.7
So, we will all store in Sesame rdf storage except accounts (because it would be indecent to store password hashes in open SPARQL access)
For storage of accounts we use MongoDB
For authentication, we use Devise.
To work with Sesame we use Spira , which is built on rdf.rb
To work with SPARQL access point (which in this case coincides with Sesame storage) we use sparql-client
To work with MongoDB we use Mongoid
For layout we use haml
Let's go through the source code on github .
- Monkey patches were written for correct work with Sesame and for more convenient work with Spira as a mapper.
- Apache Tomcat and Sesame (openrdf-sesame + openrdf-workbench) installed and configured on it
- MongoDB installed and configured
- Models , views and controllers are written .
- Installed and configured Devise, Mongoid standard tools from the console
- With the help of the banal SPARQL query, we got all candidates that fit the requirements (a more complex model is given in the documentation for the diploma):
def find_candidates sel=Person._where competences_with_level.each do |cwl| cwl_id=:"cwl#{i}" # lev_id=:"lev#{i}" val=:"val#{i}" sel._where(:competences_with_level=>cwl_id) # sel.where([cwl_id,CompetenceWithLevel.properties[:competence][:predicate],cwl.competence.subject]) # sel.where([cwl_id,CompetenceWithLevel.properties[:level][:predicate],lev_id]) # sel.where([lev_id,CompetenceLevel.properties[:value][:predicate],val]) # sel.filter("?val#{i} >= #{cwl.level.value}") # , end sel.instances end Consider the structure of the Spira document model, since it is different from ActiveRecord and Mongoid.
class Task include Spira::Resource #-, type Vocabularies::Project.Task # owl type base_uri "http://example.org/tasks/" #, default_vocabulary Vocabularies::Project # (), property :name, :predicate=>Vocabularies::Project.hasName, :type=>String #, – property :project, :predicate=>Vocabularies::Project.belongsToProject, :type=>:Project # . . has_many :competences_with_level, :predicate=>Vocabularies::Project.requires, :type=>:CompetenceWithLevel # --. ruby . end And let's note the availability of the ability to extract data from the system through not only SPARQL, but also the display of each entity in nt form:
def show @competence = Competence.find(params[:id]) respond_to do |format| format.html # show.html.erb format.nt { render :inline => @competence.to_nt } # end end So, we got a search system for candidates for the implementation of projects based on the required and existing competencies.
This application is far from ideal, not very clean code, no modular and integration tests, no authorization, this is just an interesting experiment, which was a step for me in understanding and using semantic technologies in the field of project management, project team formation. And I hope that it will help those interested in creating semantic applications on Ruby on Rails in the future and develop so far not so popular semantic technologies.
All diploma documents (explanatory note, presentations, reports in Russian and English) can be found here (who knows a more detailed formal description, by the way, there are many things in them that are not in the annex).
I will be glad if this material is useful to someone to create software for your educational projects, however, you still have your head on your shoulders;).
ps Thanks to my graduate leaders, Associate Professor D.V. Popov and A.F. Galyamov, Department of VMK, FIRT, USATU.
Source: https://habr.com/ru/post/123612/
All Articles