Fuzzy search implementation
If your web project is somehow connected with the search and provision of some data to users, then you will probably face the task of implementing the search string. At the same time, if the project for some reason does not succeed in using technologies of smart services like Google or Yandex, then the search will be partially or fully implemented independently. One of the subtasks will probably be the implementation of a fuzzy search, because users often make mistakes and sometimes do not know the exact terms, names or names.
This article describes a possible implementation of a fuzzy search, which was used to search on the site edatuda.ru .
Task
As part of the creation of our service for finding restaurants, cafes and bars, the task arose of implementing a search string in which users could indicate the names of their places of interest.
The task was set as follows:
- Search results should be displayed in the recruitment process in the dropdown list.
- The search should take into account possible errors and typos of users (for example, mcdonalds and I want to type as macdonalds).
- For each institution should be able to set a lot of synonyms (for example mcdonalds => McDuck).
Visual presentation of items 1-3:
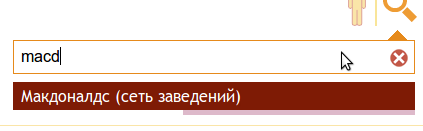

')
Thus, having received the query phrase, most likely cut off, you need to select from the pre-assembled dictionary the closest in writing to the entry. In essence, the task was to correct typos that modern search engines can perform. Some of the common methods of solving it:
- Method based on the construction of the n-gram index.
A good, simple and fast method. - Method based on distance editing.
Probably one of the most accurate methods that does not take into account the context. - Combination of claim 1 and 2.
To speed up the search on large dictionaries, it makes sense to first select a group of words based on the n-gram index and then apply clause 2 (see the work of Zobel and Darth “Finding approximate matches in large lexicons” )
On Habré there was a good article devoted to fuzzy search in the text and the dictionary. It is well described in paragraphs 1 and 2., In particular, the Levenshtein and Damerau-Levenshtein distances with pretty pictures. Therefore, this article will not provide a detailed description of these methods.
Implementation of the search
In our case, the dictionary is not as large (as for example in search engines), of the order of several thousand entries, so we decided to use the method based on the editing distance without building an n-gram index.
Conventional editing distance calculation algorithms well estimate the proximity of lines, but do not use any information about the characters (except for their equality or inequality), such as the distance between the keys corresponding to the characters on the keyboard or the proximity of the sound.
Taking into account the distance between the keys can be useful because during speed dialing a large number of errors occur due to misses, while the probability that the user accidentally pressed the next key is higher than the more remote one.
Accounting for phonetic rules is also important. For example, in the case of foreign names and names, users often do not know the exact spelling of words, but remember their sound.
In the work of Zobel and Darth “Phonetic string matching: lessons from information retrieval” describes a method for comparing strings combining the calculation of the editing distance with a set of phonetic rules (the phrase “phonetic rules” is not entirely correct). The authors identified several phonetic groups consisting of symbols, such that the “cost” of replacing the characters of one group when calculating the editing distance was lower than the “cost” of replacing characters that did not belong to the same group. We used this idea.
As a basic algorithm, we took the Wagner-Fisher algorithm adapted to find the Damerau-Levenshtein distance with several modifications:
- In the basic algorithm, the “cost” of all operations is 1. We set that the “cost” of insert and delete operations is 2, the exchange operation is 1, and the operations of replacing one character with another are calculated as follows: if the keys corresponding to the compared characters are located next to keyboard or compared characters belong to the same phonetic group, the replacement “cost” is 1, otherwise 2.
- As a result, the prefix distance is returned, i.e. the minimum distance between the query word and all prefixes of the word from the dictionary. This is necessary because Query words that we will compare with dictionary forms will usually be truncated. Those. we can compare the user-entered “mcd” with the dictionary “mcdonalds” and get a large distance (7 inserts), although “mcdonalds” in this case corresponds exactly to the query.
We took phonetic groups from the above-mentioned work, with minor changes:

In the original work of the group, they were compiled based on the sound of the original English words, so there is no guarantee that they will show a good result in the transliterated Russian text. We made small changes (for example, we removed 'p' from the original “fpv” group) based on our own observations.
The resulting implementation in c ++:
{{{ class EditDistance { public: int DamerauLevenshtein(const std::string& user_str, const std::string& dict_str) { size_t user_sz = user_str.size(); size_t dict_sz = dict_str.size(); for (size_t i = 0; i <= user_sz; ++i) { trace_[i][0] = i << 1; } for (size_t j = 1; j <= dict_sz; ++j) { trace_[0][j] = j << 1; } for (size_t j = 1; j <= dict_sz; ++j) { for (size_t i = 1; i <= user_sz; ++i) { // , int rcost = ReplaceCost(user_str[i - 1], dict_str[j - 1]); int dist0 = trace_[i - 1][j] + 2; int dist1 = trace_[i][j - 1] + 2; int dist2 = trace_[i - 1][j - 1] + rcost; trace_[i][j] = std::min(dist0, std::min(dist1, dist2)); // if (i > 1 && j > 1 && user_str[i - 1] == dict_str[j - 2] && user_str[i - 2] == dict_str[j - 1]) { trace_[i][j] = std::min(trace_[i][j], trace_[i - 2][j - 2] + 1); } } } // // int min_dist = trace_[user_sz][0]; for (size_t i = 1; i <= dict_sz; ++i) { if (trace_[user_sz][i] < min_dist) min_dist = trace_[user_sz][i]; } return min_dist; } private: const static size_t kMaxStrLength = 255; int trace_[kMaxStrLength + 1][kMaxStrLength + 1]; private: int ReplaceCost(unsigned char first, unsigned char second); } }}} We take into account that in short words, users, as a rule, do not make such blatant mistakes as in long ones. To do this, we make a threshold of the maximum allowable distance between words proportional to the length of the word query.
{{{ const double kMaxDistGrad = 1 / 3.0; ... uint32_t dist = distance_.DamerauLevenshtein(word, dict_form); if (dist <= (word.size() * kMaxDistGrad)) { // ok } }}} Index
Let the source records for institutions are:
<meta data: id, ...> <name of institution> <synonymous forms of name>
Then the index can be represented as follows:

- places - meta data for places that are search results.
- places_index - names and their synonymous forms, referring to specific institutions; in fact, it’s just an array of links to places.
- words_index - words selected from all forms; This is something like an inverted view index: <word> <places_index0, places_index1, ...>; in the case of a small dictionary, it can be organized as an array of arrays.
During the search, you will need to go through the entire array of words_index for each word of the user's request. If the dictionary is too large, then, assuming that errors in the first letter are quite rare, you can restrict yourself to forms starting with the same letter as the query word.
Strive for fullness
To increase the completeness of the found institutions, we applied a couple more ideas.- When typing, users often forget to switch the keyboard layout, (you can often see requests like: “ghfqv”, “vfrljy”, ..). Therefore, an idea arose in the event that in a normal search no institution was found, to perform the same search with a query formed from characters of the opposite layout of the basic query.
- Many establishments do not have Russian names, but users are used to typing them in Cyrillic. For institutions such as McDonalds, Starbucks and others. Cyrillic forms of names, obviously, can be entered in the dictionary as synonyms. But for some, such as GQ Bar, it is not advisable to generate synonyms of the type “GQ bar”, and it is necessary that the institution be consistent with the query “bar”. Therefore, for Cyrillic queries, in addition to the usual, an additional transliterated query is formed.
{{{ // FindPhrase(base_phrase, &suggested); // // . std::string trs_phrase = Transliterate(base_phrase); if (trs_phrase != base_phrase) FindPhrase(trs_phrase, &suggested); // // // if (suggested.empty()) { std::string invert_phrase = InvertForm(base_phrase); FindPhrase(invert_phrase, &suggested); } }}}
General implementation
All indexing and search logic was implemented in the c ++ daemon. The data about the establishments is periodically re-read from the database, the index is completely rebuilt. Communication with front-end scripts is done via HTTP via GET requests, the results are transmitted in the response body in json format. It turned out the following scheme:
As a result, with ~ 2.5 thousand unique words, the search time averaged ~ 8 ms.
Links- Project site. edatuda.ru
- Levenshtein distance. ru.wikipedia.org/wiki/Levenshteyn_Distance
- Distance Damerau-Levenshteyn. en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance
- The work of Zobel and Darth. “Finding approximate matches in large lexicons”. citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.14.3856&rep=rep1&type=pdf
- The work of Zobel and Darth. “Phonetic string matching: lessons from information retrieval” citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.18.2138&rep=rep1&type=pdf
Source: https://habr.com/ru/post/123320/
All Articles