Dataflow architecture. Part 2

In the first part of the article, we looked at the main differences between the data flow architecture (dataflow) and the control flow architecture (controlflow), made a tour in the 1970s, when the first hardware dataflow machines appeared and compared the static and dynamic flow calculation models. Today I will continue to introduce you to dataflow architectures. Welcome under the cut!
In addition to the above: the implementation of cycles in dynamic flow systems
Consider in more detail the work of the context on the example of the organization of cycles. I recall that the context is a field in the token structure that uniquely identifies an instance of the dataflow node. In the case of loops, the context will be the iteration number.
Example 1. Fibonacci numbers
Calculating Fibonacci numbers is a classic example of a loop with data iteration dependency. Nth number is equal to the sum of (N-1) -th and (N-2) -th:
int fib [MAX_I]; fib [0] = 1; fib [1] = 1; for (i = 2; i < MAX_I; i++) { fib [i] = fib [i-1] + fib [i-2]; } ')
Construct a flow calculation graph:
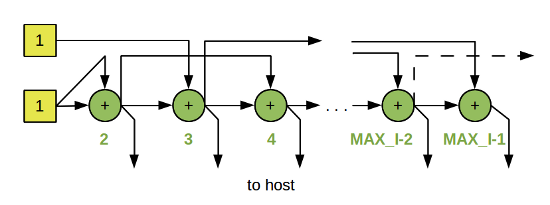
It is easy to see that a graph consists of (MAX_I-2) identical nodes that differ only in the context values (the numbers below the node image). The logic of the node (in pseudocode) will look like this:
fib (: A, B) i = _(A); result = _(A) + _(B); _ (: result, : host, : i); (i < MAX_I-1) _ (: result, : fib, : i+1); _ (: result, : fib, : i+2); fib To start the program, you need to send three tokens:
_ (: 1, : fib, : 2); _ (: 1, : fib, : 2); _ (: 1, : fib, : 3); As a result of the execution of a streaming program, a set of tokens will be sent to the host, each of which will carry the number of the Fibonacci number in the context field, and the number itself in the data field. Please note that another token (marked with a dotted line in the column) is sent “to nowhere”, more precisely, it never starts the execution of the node due to the absence of a token paired with it. You can get rid of it either by adding one more condition check (i <MAX_I-2) in the node code, or by organizing a software or hardware “garbage collector”.
Example 2. Addition of matrices
We now consider an example where there is no dependence between iterations on data: the addition of matrices
int A [MAX_I][MAX_J]; int B [MAX_I][MAX_J]; int C [MAX_I][MAX_J]; GetSomeData (A, B); for (i = 0; i < MAX_I; i++) for (j = 0; j < MAX_J; j++) { C[i,j] = A[i,j] + B[i,j]; } All (MAX_I * MAX_J) iterations can be performed simultaneously. Here is the graph of matrix additions:
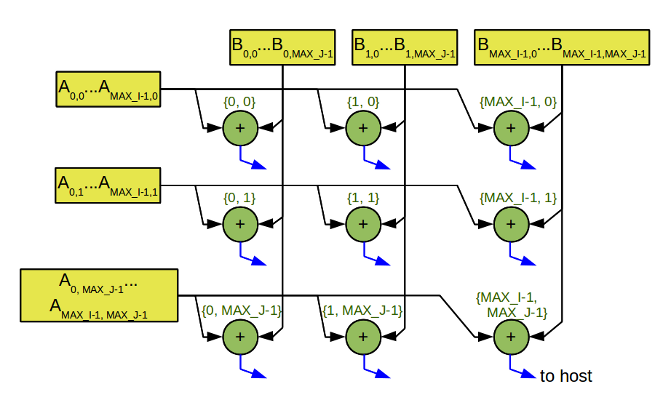
The context in this case is a structure of two coordinates {i; j}. Given this, the graph node will look like this:
add (: A, B) {i, j} = _(A); result = _(A) + _(B); _ (: result, : host, : {i, j}); add Please note that there are no border checks here! The number of iterations is automatically selected based on the dimension of the input data. Input data, by the way, should come in this form:
_ (: A[0, 0], : add, : {0, 0}); _ (: B[0, 0], : add, : {0, 0}); _ (: A[0, 1], : add, : {0, 1}); _ (: B[0, 1], : add, : {0, 1}); ... _ (: A[MAX_I-1, MAX_J-1], : add, : {MAX_I-1, MAX_J-1}); _ (: B[MAX_I-1, MAX_J-1], : add, : {MAX_I-1, MAX_J-1}); Dataflow systems are very efficient for processing sparse data, since only significant elements are actually sent and processed.
Hybrid Dataflow Architecture
“Clean” streaming architectures like those described by the MIT Static Dataflow Machine and the Manchester Dataflow Machine unfortunately had many weak points:
- Dataflow machines offered tremendous opportunities for concurrency execution. The flip side of this advantage was that in successive areas of the computation graph, they showed a sharp drop in performance.
- Download actuators was far from the maximum possible. Most of the machine time was spent searching for matching operands, fetching instructions, and the actuator was idle all that time, executing only one instruction for each pair of tokens.
- The design of matching devices was difficult. Associative memory is more complicated, more expensive, slower, takes up more space and consumes more energy, compared with conventional RAM of the same amount.
- The principle of data flow control did not allow organizing an efficient pipeline. Almost all devices worked asynchronously, buffers and queues in communication lines were required.
- Compared with the classical multiprocessor architecture, the dataflow machines have a much higher load on the switching network. After all, in fact, each operation required the transfer of two tokens.
In an attempt to solve these problems, hybrid architectures began to appear, combining elements of both data flow architectures and control flow.
Threaded dataflow
This term has no adequate translation into Russian at all. The essence of this approach is to replace successive sections of the computational graph, which cannot be parallelized, to be replaced with threads (threads) - sets of sequentially executed instructions. “Extra” intermediate tokens disappear immediately, and the load on the actuators increases. The principles of threaded dataflow were implemented “in hardware” in the Epsilon processor [21] in 1989.
Coarse Data Flow Architecture
The further development of threaded dataflow is the so-called coarse-grained streaming architecture (large-grain dataflow). When it became clear that the parallelism of "pure" dataflow in many cases is redundant, the decision arose to build a flow graph not from individual operators, but from blocks. Thus, in a coarse-grained architecture, each node is not a single instruction, but a classic sequential program. The interaction between nodes is still based on the data flow principle. One of the advantages of this approach was the ability to use conventional background Neumann processors as executive devices. It should be noted that despite the name “coarse-grained”, the blocks into which the task is broken are still much smaller than, say, in cluster systems. A typical block size is 10-100 instructions and 16-1K bytes of data.
Vector dataflow architecture
In vector streaming systems, a token contains not one value, but a set at once. Accordingly, operations are performed not on pairs of operands, but on pairs of vectors. An example of such a system is the SIGMA-1 (1988) [22] . Sometimes vector mode is supported only by a part of the system executive devices. Often, hybrid architectures are also used that combine several approaches at once, for example, a coarse-grained architecture with the ability to perform vector operations.
Reconfigurable systems
The development of FPGA technologies has made possible a fundamentally new approach to the dataflow architecture. What if you assemble a machine that is focused on solving one specific problem? If you implement the necessary computational graph directly at the circuit level, you can achieve amazing results. Instead of complex and slow mapping devices, you can use unconditional data redirection from one function module to another. The actuators themselves can also be “sharpened” for the desired task: choose the type of arithmetic, bit depth, the necessary set of supported operations.
Of course, such a machine will be very highly specialized, but after all the advantage of the FPGA is precisely in the possibility of repeated reprogramming. Thus, for each individual task is going to the desired architecture. Some systems even allow you to reconfigure right in the process. Reconfigurable systems based on FPGA chips are currently commercially available in a variety of formats - from the “accelerator” block for a PC to a system with a capacity of the order of several teraflops [31] .
Among the disadvantages of reconfigurable architectures are the following:
- Principal mono-task. To start a new task, you need to stop the system and reprogram the FPGAs that are part of it.
- The complexity of programming. The programming of each task includes the synthesis of the entire computational architecture for this task.
- Excessive hardware complexity. The downside of FPGA flexibility is the presence of a large percentage of elements on the chip, which are not directly involved in the calculations, but serve only for reconfiguration. However, these elements consume energy and generate heat during operation, which impairs the system’s energy performance indicators (Gflops / W).
Programming for dataflow architecture
Programming in the dataflow paradigm is significantly different from the usual structural, and closer rather to functional. There are no variables, arrays and other named memory areas, no called procedures and functions in the usual sense of the word. Stream programming uses the principle of one-time assignment . Each data unit (as a rule, it is a token) is given a value only once, when created, and can only be read later. This principle reflects the unidirectionality of the branches of the computational graph.
In dataflow, unfortunately, no programming standard was developed. Usually for each architecture developed its own language. I'll tell you about some of the most famous.
Val
VAL (Value-oriented Algorithmic Language) [41] was developed at the Massachusetts Institute of Technology (MIT) in 1979 specifically for the MIT Dataflow Machine. Here’s how, for example, factorial calculation on VAL looks like:
for Y:integer := 1; P:integer := N; do if P ~= 1 then iter Y := Y*P; P := P-1; enditer; else Y endif endfor Sisal
SISAL (Streams and Iteration in a Single Assignment Language) [42] , which appeared in 1983, is a further development of VAL. Unlike VAL, SISAL allows recursion.
Calculation of factorial:
function factorial( n : integer returns integer ) if n <=1 then 1 else n * factorial( n - 1 ) end if end function Option without recursion from middle habrauzer:
function factorial (n : integer returns integer) for i in 1, n returns value of prod i end for end function Id
Id [43] is a parallel general purpose language, created in the late 1970s - early 1980s at MIT. Further work on the Id led to the development of the pH language - a parallel Haskell dialect.
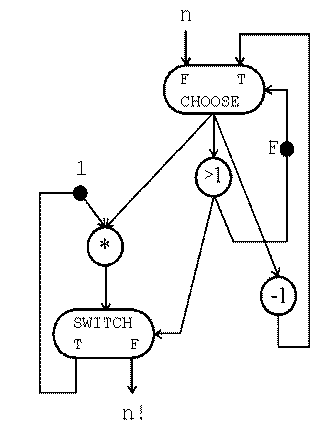
Factorial on Id:
( initial j <- n; k <- 1 while j > 1 do new j <- j - 1; new k <- k * j; return k ) A graph of calculations for this program will look like this:
Lucid
The Lucid language [44] [45] was developed in 1976 by Bill Wadge and Ed Ashcroft. Operates with the concepts of value streams (analogue of variables) and filters, or converters (analogue of functions).
Factorial on Lucid:
fac where n = 0 fby (n + 1); fac = 1 fby ( fac * (n + 1) ); end Quil
Quil (2010) [46] is a language based on Lucid, currently working on it. There is an online interpreter on the language site, so I leave the factorial calculation on Quil as an independent task for the readers.
Conclusion
The “boom” of streaming architectures fell on the 1970s – 1980s, then the interest in dataflow gradually subsided. Nowadays, elements of streaming computers can be found in the architecture of DSP (signal processors), network routers and graphics processors. But gradually, an increasing number of specialists are again turning to the dataflow paradigm within high-performance computing. This can probably be attributed to the fact that today the Von Neumann architecture is approaching its limit of scalability, and new approaches are required to further improve performance.
Somewhat apart are reconfigurable architectures, in which the line between software and hardware is gradually erased. What technology is the future behind? The question remains open.
Bonus Game. To the most inquisitive readers, I suggest trying to determine which graphs of the algorithms are depicted in “pictures to attract attention” in the title of each part of the article. Good luck!
Literature
The numbering of the sources continues from the first part.
Hybrid dataflow systems
[21] - The Epsilon dataflow processor, VG Grafe, GS Davidson and others.
[22] - Efficient vector processing of the supercomputer SIGMA-1, K. Hiraki, S. Sekiguchi, T. Shimada.
Reconfigurable systems
[31] - Family of multiprocessor computing systems with dynamically tunable architecture, N.N. Dmitrienko, I.A. Kalyaev and others.
[32] - Dynamically Reconfigurable Multi-FPGA Platforms, Voigt, S.-O., Teufel, T.
Dataflow programming languages
[41] - VAL - A Value-oriented Algorithmic Language
[42] - Sisal Language Tutorial
[43] - ID Language Reference Manual, Rishiyur S. Nikhil, 1991
[44] - LUCID, the dataflow programming language, Academic Press Professional, Inc. San Diego, CA, USA 1985 ISBN: 0-12-729650-6
[45] - Fluid Programming in Lucid
[46] - The Quil Language
Source: https://habr.com/ru/post/122530/
All Articles