Dataflow architecture. Part 1
The second part of the article.
Most modern computers, be it a Fujitsu K supercomputer, a regular person, or even a calculator, combine a common operating principle, namely, a computing model based on Controlflow. However, this model is not the only possible one. In some ways, its opposite is the data flow -driven computing model, or simply Dataflow. About her I want to tell you now.
The control flow architecture is often called von Neumann (in honor of John von Neumann). This is not entirely correct, since the von Neumann architecture is only a subset of control flow architectures. There are non-Neumann control flow architectures, such as Harvard , which can now be found only in microcontrollers.
Within the framework of the control flow architecture, a computer consists of two main nodes: a processor and a memory. A program is a set of instructions stored in memory in order of execution. The data with which the program works is also stored in memory as a set of variables. The address of the instruction that is currently being executed is stored in a special register, in x86 it is called Instruction Pointer (IP). The moment of the beginning of the instruction execution is determined by the moment of completion of the previous one (we are now considering a simplified model without any Out-of-Order ). The system is very simple, clear and familiar to most readers. So why invent something else?
Congenital controlflow problems
The fact is that the control flow architecture has a number of inherent flaws, which cannot be completely eliminated, since they stem from the organization of the computational process itself; you can only reduce the negative effect with the help of various
- Before executing the instruction, its operands must be loaded from memory into the registers of the processor, and after execution, the result must be unloaded back into memory. Bus processor-memory becomes a bottleneck: the processor is idle for some time, waiting for data to load. The problem with varying success is solved with the help of prefetching and several levels of cache memory.
- The construction of multiprocessor systems is associated with a number of difficulties. There are two basic concepts of such systems: with shared and distributed memory. In the first case, it is difficult to physically ensure that multiple processors share access to a single RAM. In the second case, there are problems of data coherence and synchronization. As the number of processors in the system grows, more and more resources are spent on providing synchronization and less and less on actual computations [03] .
- No one guarantees that at the time of the execution of any instruction, its operands will be in memory at the specified addresses. The instruction that should record this data may not yet have been executed. In multithreaded applications, a substantial share of the
programmer’sresourcesand nervesis spent on ensuring the synchronization of threads.
Meet - Dataflow
There is no well-established Russian translation for the term Dataflow architecture. You can find options "streaming architecture", "architecture of data flow", "architecture with data flow control" and the like.
In architectures with data flow control (Dataflow) [01], the concept of a “sequence of instructions” is missing, there is no Instruction Pointer, there is even no addressable memory in the usual sense. A program in a streaming system is not a set of commands, but a computational graph. Each node of the graph represents an operator or a set of operators, and branches reflect the dependencies of nodes by data. The next node starts running as soon as all its input data is available. This is one of the basic principles of dataflow: the execution of data readiness instructions.
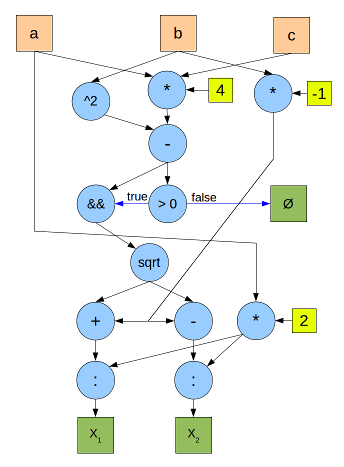
For example, here is a graph calculating the roots of a quadratic equation. Blue circles are operators, orange squares are input data, green ones are output, yellow ones are constants. Black arrows indicate the transfer of numerical data, blue - Boolean.
')
Hardware implementation
In streaming machines, data is transmitted and stored as a so-called. tokens (token). A token is a structure containing the actual value transmitted and a label — the pointer of the destination node. The simplest streaming computing system consists of two devices: the execution unit and the matching unit [11] .
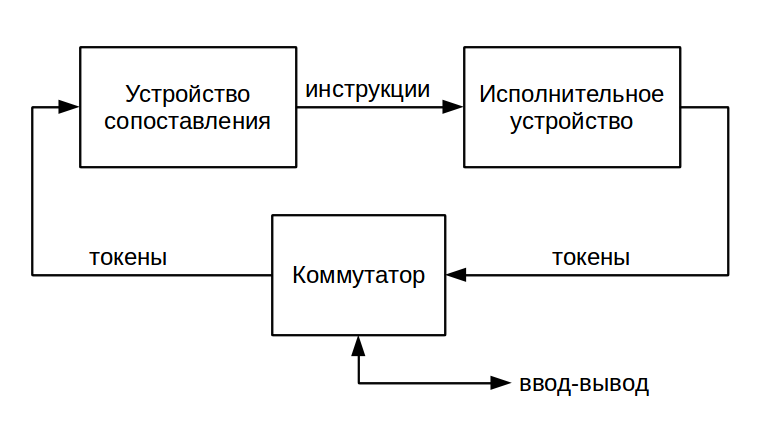
The actuator serves to execute instructions and form tokens with the results of operations. As a rule, it includes a read-only instruction memory. Readiness of input data of a node is determined by the presence of a set of tokens with the same labels. To search for such sets and serves as a mapping device. It is usually implemented on the basis of associative memory. Either “real”, hardware associative memory ( CAM - content-addressable memory), or structures operating similarly, for example, hash tables, are used .
One of the main advantages of the dataflow architecture is its scalability: it is not difficult to assemble a system containing many matching devices and executive devices. The devices are united by the simplest switch, and their labels serve to address the tokens. The entire range of node numbers is simply distributed evenly between devices. No additional measures are required to synchronize the computational process, unlike the multiprocessor controlflow-architecture.
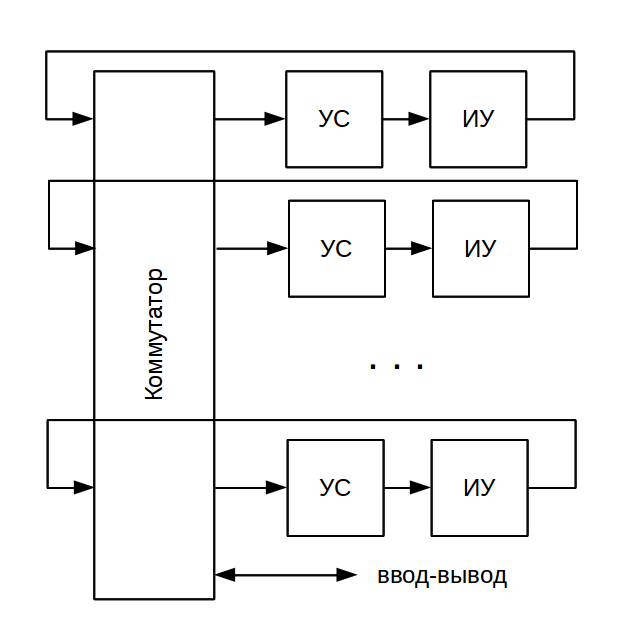
Static dataflow architecture
The above scheme is called static (static dataflow). Each computational node is represented in it in a single copy, the number of nodes is known in advance, the number of tokens circulating in the system is also known in advance. As an example of a static architecture implementation, MIT Static Dataflow Machine [12] , a streaming computer created at the Massachusetts Institute of Technology in 1974, can be cited. The machine consisted of a variety of processing elements (Processing Element) connected by a communication network. The scheme of one element is shown in the figure:
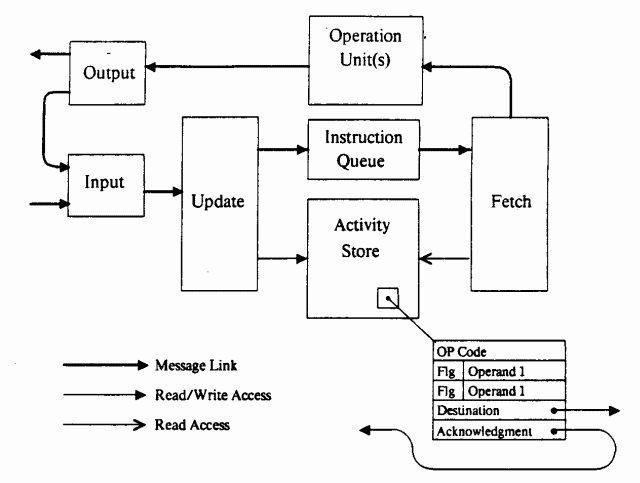
The role of the mapping device here was performed by an interaction memory (activity store). It contained pairs of tokens along with the address of the destination node, readiness flags, and an operation code. Any computational node in this architecture had only two inputs and consisted of one operator. Upon detection of the readiness of both operands , the fetch unit read the operation code, and the data was sent for processing to the operation unit.
Dynamic dataflow architecture
In a dynamic streaming architecture (dynamic dataflow), each node can have multiple instances. In order to distinguish tokens addressed to different instances of the same node, an additional field is introduced into the token structure - context . The comparison of tokens is now conducted not only by tags, but also by context values. Compared with the static architecture, a number of new features appear.
- Recursion A node can send data to its copy, which will differ in context (but still have the same label).
- Support procedures. The procedure within the framework of this model of calculations will be a sequence of nodes interconnected and having inputs and outputs. You can simultaneously call multiple instances of the same procedure, which will differ in context.
- Loop parallelization. If there is no data dependency between iterations of a loop, you can process all iterations simultaneously at the same time. The iteration number, as you may have guessed, will be contained in the context field.
One of the first implementations of the dynamic flow architecture was the Manchester Dataflow Machine system (1980) [13] . The machine contained hardware for organizing recursion, calling procedures, opening cycles, copying, and merging branches of the computational graph. Also in a separate module was the instruction memory (instruction store unit). The figure shows a diagram of a single machine element:
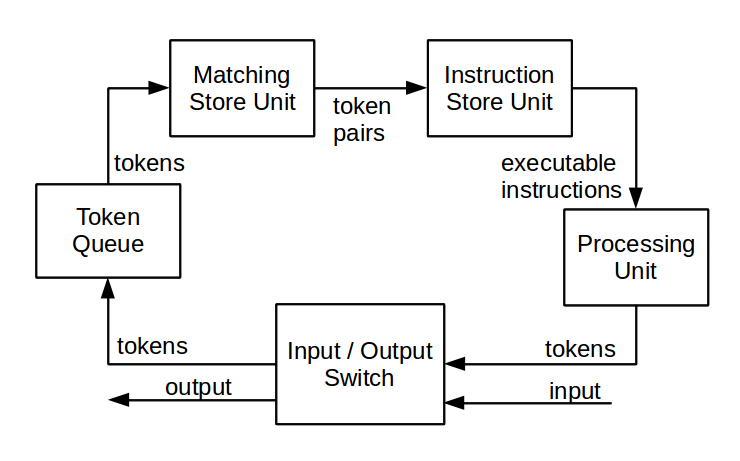
Dynamic dataflow-architecture, compared with static, demonstrates better performance due to better parallelism of calculations. In addition, it provides more opportunities for the programmer. On the other hand, a dynamic system is more complex in terms of hardware implementation, especially with regard to matching devices and token context forming units.
To be continued
In the next part of the article: why dataflow architecture is not as good as described here? How to cross a
Stay tuned ...
Literature
General dataflow issues
[01] - Dataflow architectures, Jurij Silc
[02] - Bakanov V.M. Dataflow calculators: data processing intensity control
[03] - Parallelization of data processing on computer flow (Dataflow) architecture. Magazine "Supercomputers top50".
Hardware implementations
[11] - Dataflow architectures, Arvind David E. Culler
[12] - Preliminary Architecture for a Basic Data-Flow Processor, Jack B. Dennis and David P. Misunas
[13] - A Multilayered Data Flow Computer Architecture, JR Gurd, I. Watson.
Source: https://habr.com/ru/post/122479/
All Articles