Character distribution in passwords
The other day I came across interesting conclusions from the analysis of recently leaked accounts from Sony servers. I think these findings will be interesting and relevant.
As you know, in recent years, Sony has emerged as a whipping boy among hackers. Thanks to Sony, many user accounts and passwords circulate on the Internet. Recently, Troy Hunt conducted a small analysis of these passwords. Here is an excerpt from his post:
In this post, we explore the remaining 24,000 passwords that have withstood the attack with a dictionary.
')
As Troy notes, the absolute majority of passwords contained only one type of character — either all in lower case or all in upper case. However, everything is even worse if we consider the frequency of characters.
There are 78 unique characters in the password database. If these passwords were truly random, each character should occur with a probability of 1/78 = 0.013. But when we calculate the real frequency of the symbols, we will clearly see that the distribution is not random. The following graph shows the top 20 password characters, and the red line shows the expected 1/78 distribution.
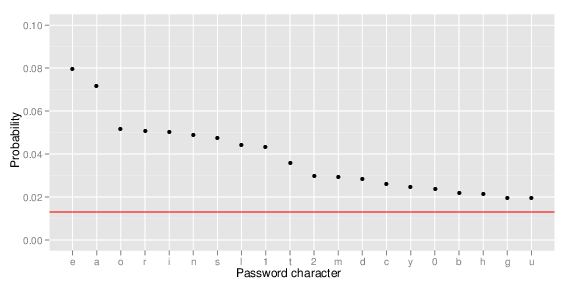
Not surprisingly, the vowels “e”, “a” and “o” are very popular, as well as the numbers “1”, “2” and “0” (in that order). Capital letters are not in the top twenty. We can also plot the total probability for characters. In this graph, the red dots show the expected pattern when using real random passwords ( link to the graph more).

It is clear that passwords are not as random as we would like.
Let's look at the order of the characters in the password. For simplicity, we take only 8-character passwords. The most popular number in the password is “1.” If its location were random, we would expect a uniform distribution. But instead we get:
From this it follows that out of 84 percent of passwords that contain the digit “1”, this digit only happens in the second half of the password. It is clear that people like to put a unit at the end of a password.
The same picture with the number "2":
And with "!"
We observe similar patterns with other alphanumeric characters.
Suppose we collect all possible passwords using the first N most popular characters. How many passwords will we cover in our sample? The following graph shows the proportion of passwords covered in our list using the first N characters:
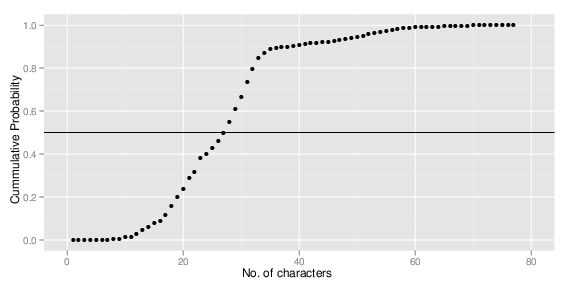
To cover 50% of passwords in the list, we needed 27 first characters. Actually, using only 20 characters covers about 25% of passwords, and using 31 characters covers 80% of passwords. Remember that these passwords do not succumb to a dictionary attack.
Usually, when we calculate the probability of guessing a password, we assume that each character is chosen with the same probability, that is, the probability of choosing “e” is equal to the choice of “Z”. This is clearly wrong. Also, recently, many systems have forced users to choose different types of characters in passwords. And it is so easy to add tsiferku at the end. I do not want to consider effective techniques for selecting passwords, but it is clear that brute force is not the right method.
Personally, I gave up trying to remember passwords a long time ago and just use the password manager. For example, my Wordpress password is longer than 12 characters and consists of completely random numbers, letters and specials. characters. Of course, you only need to keep your password manager protected ...
From the translator: Yes, I did fall into the category of people attributing edinichki and exclamation marks to bypass annoying sites. Sad but true .
As you know, in recent years, Sony has emerged as a whipping boy among hackers. Thanks to Sony, many user accounts and passwords circulate on the Internet. Recently, Troy Hunt conducted a small analysis of these passwords. Here is an excerpt from his post:
- Of the roughly forty thousand passwords, a third is subject to a simple dictionary attack.
- Only one percent of passwords contained non-numeric characters.
- 93 percent of passwords contained from 6 to 10 characters.
In this post, we explore the remaining 24,000 passwords that have withstood the attack with a dictionary.
')
Character distribution
As Troy notes, the absolute majority of passwords contained only one type of character — either all in lower case or all in upper case. However, everything is even worse if we consider the frequency of characters.
There are 78 unique characters in the password database. If these passwords were truly random, each character should occur with a probability of 1/78 = 0.013. But when we calculate the real frequency of the symbols, we will clearly see that the distribution is not random. The following graph shows the top 20 password characters, and the red line shows the expected 1/78 distribution.
Not surprisingly, the vowels “e”, “a” and “o” are very popular, as well as the numbers “1”, “2” and “0” (in that order). Capital letters are not in the top twenty. We can also plot the total probability for characters. In this graph, the red dots show the expected pattern when using real random passwords ( link to the graph more).
It is clear that passwords are not as random as we would like.
Character order
Let's look at the order of the characters in the password. For simplicity, we take only 8-character passwords. The most popular number in the password is “1.” If its location were random, we would expect a uniform distribution. But instead we get:
##Distribution of "1" over eight character passwords
0.06 0.03 0.04 0.04 0.13 0.13 0.22 0.34From this it follows that out of 84 percent of passwords that contain the digit “1”, this digit only happens in the second half of the password. It is clear that people like to put a unit at the end of a password.
The same picture with the number "2":
0.05 0.05 0.04 0.05 0.13 0.11 0.30 0.27And with "!"
#Small sample size here
0.00 0.00 0.00 0.00 0.00 0.11 0.16 0.74We observe similar patterns with other alphanumeric characters.
Number of characters required to guess a password
Suppose we collect all possible passwords using the first N most popular characters. How many passwords will we cover in our sample? The following graph shows the proportion of passwords covered in our list using the first N characters:
To cover 50% of passwords in the list, we needed 27 first characters. Actually, using only 20 characters covers about 25% of passwords, and using 31 characters covers 80% of passwords. Remember that these passwords do not succumb to a dictionary attack.
Total
Usually, when we calculate the probability of guessing a password, we assume that each character is chosen with the same probability, that is, the probability of choosing “e” is equal to the choice of “Z”. This is clearly wrong. Also, recently, many systems have forced users to choose different types of characters in passwords. And it is so easy to add tsiferku at the end. I do not want to consider effective techniques for selecting passwords, but it is clear that brute force is not the right method.
Personally, I gave up trying to remember passwords a long time ago and just use the password manager. For example, my Wordpress password is longer than 12 characters and consists of completely random numbers, letters and specials. characters. Of course, you only need to keep your password manager protected ...
From the translator: Yes, I did fall into the category of people attributing edinichki and exclamation marks to bypass annoying sites. Sad but true .
Source: https://habr.com/ru/post/122129/
All Articles