How does reCAPTCHA work?
 In a discussion of my recent translation of the most remarkable article about CAPTCHA, several questions have arisen about reCAPTCHA, namely how this system works. Under the cut, I will explain in general terms the essence of reCAPTCHA, I will clearly show how it works and how it figures the books.
In a discussion of my recent translation of the most remarkable article about CAPTCHA, several questions have arisen about reCAPTCHA, namely how this system works. Under the cut, I will explain in general terms the essence of reCAPTCHA, I will clearly show how it works and how it figures the books.I will tell everything rather briefly, but it’s understandable. The above illustrations were taken from the official website of reCAPTCHA
Stop spam
In essence, reCAPTCHA performs the same function that other captcha perform. The essence is simple, we introduce the proposed text and thereby prove that we are not a robot. The main difference from other systems is that reCAPTCHA not only protects the site from spammers, but also performs another, quite interesting function.
')
Read books
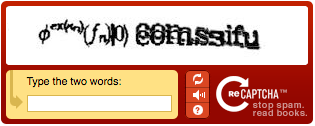
As you probably noticed, reCAPTCHA offers to enter two words, which is practically not found in other captchas. The bottom line is that the user, when entering these words, not only proves that he is human, but also helps to recognize old books and newspapers.
The principle of operation is simple:
Suppose there is an inn book, which is preserved in a small number of copies, while all of them are in poor condition. A single copy in the scanned form fell into the hands of Google (the owner of reCAPTCHA). What to do with him? That's right, to digitize (and the point here is not only in preserving the heritage, but more on that later). How to digitize? Digitize using character recognition systems (OCR). But, as many know, these systems very often sin with numerous errors in the output result. Manually going through all the text for errors is too expensive. And so, reCAPTCHA comes to the rescue. One word in the image was recognized by the OCR system correctly, but there is no second word. The second word is for the user, exactly what he will introduce will be used as a replacement for the erroneous variant proposed by OCR. Surely now some will grin, yes, I know about the fact that in fact, instead of the second word, you can type anything. But each incomprehensible word for OCR reCAPTCHA shows users hundreds or even thousands of times (with a figure of 200 million generations per day, this is very little), and ultimately the option that users entered most often is considered correct.
From boring text, let's move on to the illustrations:



Of course, this is something like an ideal situation where everything is as it was intended by the creators of reCAPTCHA. But surely many of you have come across absolutely unreadable words suggested for input. The problem is that some books / newspapers are so poorly preserved that sometimes they are recognized disgustingly by hand. Here is an example:



This is how users help digitize books with reCAPTCHA. In my opinion, this is wonderful.
I do not understand anything!
In short: the image generated by reCAPTCHA consists of two scanned words. One thing is already known to the system, there are doubts about the second one. This second word is the object for recognition by users. Roughly speaking, the reCAPTCHA interface might look like this:

Recognition Scripts
There is an erroneous opinion that reCAPTCHA is impossible to crack (we are talking about automatic recognition of the text given, without human intervention). However, judging by the trends, it is not. Over time, reCAPTCHA has developed various pitfalls for recognition systems. Among them, the curvature of the text, the intersection of its stripes, has also recently introduced a feature, due to which the test (known to the system) word looks double. All of this indicates that reCAPTCHA still has some protection issues.
No one suspected
There are people who criticize reCAPTCHA, and from an ethical point of view, they criticize not for nothing. The fact is that for the recognized text of Google one way or another gets money. And the texts themselves are extracted quite a free, by the users. That is, there is a free labor. Personally, I do not care, besides, no one forces users to enter reCAPTCHA, and moreover, no one forces webmasters to install it on their sites :)
Irony
Surely some of you, having read the previous paragraph, realized that there is something wrong. Everyone knows about the services for manual recognition of captcha, where millions of Asians introduce captcha for pennies. So, if you take into account the previous paragraph, it turns out that these Asians work not only on the service for recognition, they work on Google. Is free.
Source: https://habr.com/ru/post/121010/
All Articles