Image recovery using neural networks

Once a friend asked for help with his thesis and gave a link to an article that talked about image restoration using Kohonen self-organizing maps. After reading the article, I first decided that it was some kind of nonsense, and that the neural network did not fit in with the recovery. But, I was a bit mistaken, it turned out that this method was quite fascinating, and when I did it, I could not get enough of it.
How does this work?
The Kohonen map is a two-dimensional NXxNY grid consisting of neurons. Each neuron in the grid is represented by a square SxS - this square is called the weight vector, the values of which are equal to the color of the corresponding pixel.
For training, SxS image fragments are sent to the network, after which the network searches for the neuron most similar to this fragment, the so-called BMU (best matching unit), and adjusts its weights so that it looks even more like the submitted fragment. And then he trains his neighbors, but with less intensity. The further the neuron is from the BMU, the smaller the contribution to it is made by the submitted fragment. So the network is trained until the deviations of the BMU for each filed fragment reach a certain minimum value.
Here are a couple of examples, the first picture shows a network 120x120 with 3x3 neurons, and the second picture shows a 24x24 network with 15x15 neurons. Beauty!
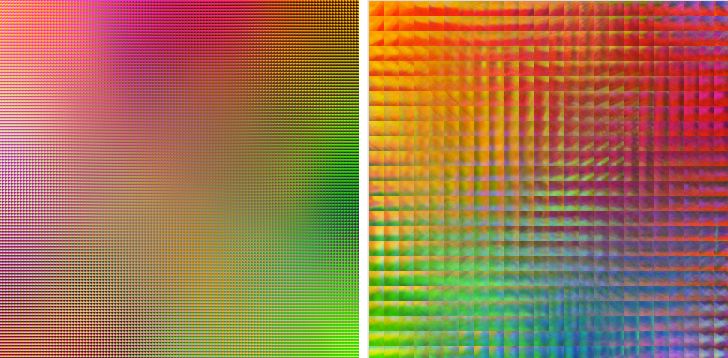
Restoration occurs in a similar way, the SxS fragment of the damaged image is taken, and the BMU is searched for non-damaged pixels, after which the damaged pixels are replaced with the corresponding values from the neuron weight vector.
How does a neural network "see" a picture?
To see how a neural network "sees" a picture, I came up with the following method. We take a trained neural network, and for each pixel in the picture we create a fragment of SxS, feed it into the neural network, extract the color of the central pixel from it and write this color along the same coordinates, but into a new picture. The resulting picture reflects the potential recovery image of the neural network. For experiments, I used this picture

')
Thanks to this method, I have identified several interesting properties.
- The larger the size of S - the less clear the image is.
The picture shows images created with 3x3 and 15x15 neurons. As you can see, 3x3 is not much different from the original. In 15x15 it turns out to be blurred.

- The more neurons in the network, the greater the palette of colors.
In the first picture, a 4x4 grid was used, and 120x120 in the second. As you can see, the 4x4 network has sharp transitions between colors.
- The more iterations of training, the more accurately the restored colors correspond to the colors of the real picture and the better the details are visible. In the first picture, a 10x10 neural network was used, trained in 10 fragments, and in the second, 10,000 fragments.


By the way, pay attention, the restoration of a well-trained network of 10x10 and 120x120 visually differs very little, only if you look closely at the details you can find small differences.
I designed the generator in the form of a small application , so you can play around yourself (checked on webkit and FF).
Repair minor accidental damage
Small random damage is easily eliminated by networks with small neurons, for example, 3x3 or 5x5 is enough. They work quickly and efficiently. Here is an example of image restoration in which 25% of pixels are damaged, by a 10x10 network and 5x5 neurons.


To restore accidental damage, also made a separate application .
Recovery of large areas
To restore large damaged areas, it is necessary that the size of the neuron S exceeds the size of the damaged area. Accordingly, the larger the damage size, the more smeared the reconstructed area will be.
The figure shows the recovery of a 10x10 fragment by a network with a 15x15 neuron.


Recovery at <20% of known pixels
Unfortunately, it is impossible to build a map using such images, so alas, it’s impossible to restore them directly, but you can restore them if you take an already trained network. The figure shows an example of image recovery by 12% of known pixels. The network was trained on the original image.


In my opinion it turned out quite well, for such a volume of damage.
UPD: about practical applications developed by me, applications:
The purpose of my research is to test the concept, and not provide a working application for all occasions, so all the talk about any serious practical application of the version that exists today does not make any sense.
Source: https://habr.com/ru/post/120473/
All Articles