Naive Bayes classifier in 25 lines of code
A naive Bayes classifier is one of the simplest of the classification algorithms. However, very often it works as good as, if not better, for more complex algorithms. Here I want to share the code and description of how it all works.
And so, for example, take the task of determining gender by name. Of course, to determine the gender you can create a large list of names with gender labels. But this list will in any case be incomplete. In order to solve this problem, you can “train” the model by tagged names.
If interested, please .
Suppose we have a string of text O. In addition, there are classes C, to one of which we must assign a string. We need to find a class c, in which its probability for a given line would be maximum. Mathematically, this is written like this:
')

Calculate P (C | O) is difficult. But you can use the Bayes theorem and go to the indirect probabilities:
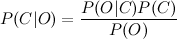
Since we are looking for the maximum of the function, the denominator does not interest us (it is a constant in this case). In addition, you need to look at the O line. Usually, there is no point in working with the entire line. It is much more effective to select certain features from it. Thus, the formula will take the form:

The denominator does not interest us. The numerator can be rewritten as follows.

But it is again difficult. Here we include the “naive” assumption that the variables O depend only on the class C, and do not depend on each other. This is greatly simplified, but it often works. The numerator will look like:

The final formula will look like:
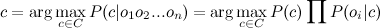 (one)
(one)
Those. all you need to do is calculate the probabilities P (C) and P (O | C). The calculation of these parameters is called classifier training.
Below is the code on python. It contains only two functions: one for training (calculating the parameters of the formula), the other for classification (direct calculation of the formula).
In the train function, the first five lines count the number of classes C, as well as the frequency of O and C features in one sample. The second part of the method simply normalizes these frequencies. In this way, the probabilities P P and P (O | C) are obtained at the output.
The classify function searches for the most likely class. The only difference from formula (1) is that I replace the product of probabilities by the sum of logarithms taken with a negative sign, and I calculate not argmax, but argmin. The transition to logarithms is a common technique to avoid too small numbers, which could be obtained by multiplying probabilities.
The number 10 (^ - 7), which is substituted into the logarithm, is a way to avoid zero in the argument of the logarithm (because it will be otherwise it will be undefined).
To train the classifier, take the marked list of male and female names and use this code:
The file 'names.txt' can be downloaded here .
As a feature, I chose the last letter of the name (see the get_features function). It works well, but for the working version it is better to use the scheme more complicated. For example, select the first letter of the name and the last two. For example, like this:
The algorithm can be used for an arbitrary number of classes. For example, you can try to build a classifier of texts on emotional coloring.
I tested the classifier on the part of the original case with the names. Accuracy was 96%. This is not a brilliant result, but for many tasks it is enough.
And so, for example, take the task of determining gender by name. Of course, to determine the gender you can create a large list of names with gender labels. But this list will in any case be incomplete. In order to solve this problem, you can “train” the model by tagged names.
If interested, please .
A bit of theory
Suppose we have a string of text O. In addition, there are classes C, to one of which we must assign a string. We need to find a class c, in which its probability for a given line would be maximum. Mathematically, this is written like this:
')
Calculate P (C | O) is difficult. But you can use the Bayes theorem and go to the indirect probabilities:
Since we are looking for the maximum of the function, the denominator does not interest us (it is a constant in this case). In addition, you need to look at the O line. Usually, there is no point in working with the entire line. It is much more effective to select certain features from it. Thus, the formula will take the form:
The denominator does not interest us. The numerator can be rewritten as follows.
But it is again difficult. Here we include the “naive” assumption that the variables O depend only on the class C, and do not depend on each other. This is greatly simplified, but it often works. The numerator will look like:
The final formula will look like:
(one)Those. all you need to do is calculate the probabilities P (C) and P (O | C). The calculation of these parameters is called classifier training.
Code
Below is the code on python. It contains only two functions: one for training (calculating the parameters of the formula), the other for classification (direct calculation of the formula).
from __future__ import division from collections import defaultdict from math import log def train(samples): classes, freq = defaultdict(lambda:0), defaultdict(lambda:0) for feats, label in samples: classes[label] += 1 # count classes frequencies for feat in feats: freq[label, feat] += 1 # count features frequencies for label, feat in freq: # normalize features frequencies freq[label, feat] /= classes[label] for c in classes: # normalize classes frequencies classes[c] /= len(samples) return classes, freq # return P(C) and P(O|C) def classify(classifier, feats): classes, prob = classifier return min(classes.keys(), # calculate argmin(-log(C|O)) key = lambda cl: -log(classes[cl]) + \ sum(-log(prob.get((cl,feat), 10**(-7))) for feat in feats)) In the train function, the first five lines count the number of classes C, as well as the frequency of O and C features in one sample. The second part of the method simply normalizes these frequencies. In this way, the probabilities P P and P (O | C) are obtained at the output.
The classify function searches for the most likely class. The only difference from formula (1) is that I replace the product of probabilities by the sum of logarithms taken with a negative sign, and I calculate not argmax, but argmin. The transition to logarithms is a common technique to avoid too small numbers, which could be obtained by multiplying probabilities.
The number 10 (^ - 7), which is substituted into the logarithm, is a way to avoid zero in the argument of the logarithm (because it will be otherwise it will be undefined).
To train the classifier, take the marked list of male and female names and use this code:
def get_features(sample): return (sample[-1],) # get last letter samples = (line.decode('utf-8').split() for line in open('names.txt')) features = [(get_features(feat), label) for feat, label in samples] classifier = train(features) print 'gender: ', classify(classifier, get_features(u'')) The file 'names.txt' can be downloaded here .
As a feature, I chose the last letter of the name (see the get_features function). It works well, but for the working version it is better to use the scheme more complicated. For example, select the first letter of the name and the last two. For example, like this:
def get_features(sample): return ( 'll: %s' % sample[-1], # get last letter 'fl: %s' % sample[0], # get first letter 'sl: %s' % sample[1], # get second letter ) The algorithm can be used for an arbitrary number of classes. For example, you can try to build a classifier of texts on emotional coloring.
Tests
I tested the classifier on the part of the original case with the names. Accuracy was 96%. This is not a brilliant result, but for many tasks it is enough.
Source: https://habr.com/ru/post/120194/
All Articles