IBM Watson supercomputer mastered the knowledge of the 2nd year of medical school
Last week, IBM confirmed serious intentions to develop data mining by announcing the release of a system on Hadoop for storing and analyzing data, as well as large investments in this area. By developing software based on open source technology, IBM officially guarantees Hadoop its protection and patronage.
On another data mining front, IBM is showing even more significant success. The developers of the IBM Watson supercomputer (which is able to answer questions, sorting out an array of unstructured data) continue to pump its database with medical information. According to them, the computer has already learned all the information that a medical college student should know. And this is just the beginning of learning.
It is quite possible that the developers of IBM Watson are inspired by the Dr. House series. From this film, the masses for the first time were able to find out how the diagnostician works. We see that his work is extremely formal and resembles an intellectual puzzle, and after all, IBM Watson is the champion in the intellectual show Jeopardy - a game where you need to quickly answer questions (the Russian clone is “Your game”). A computer is much better suited to solving such puzzles, because it requires a wide erudition and very deep knowledge. At the same time, ordinary doctors perfectly diagnose frequently occurring diseases (a list of the 100 most common diagnoses ), but if something unusual is found, then the doctor usually lacks neither experience nor knowledge.
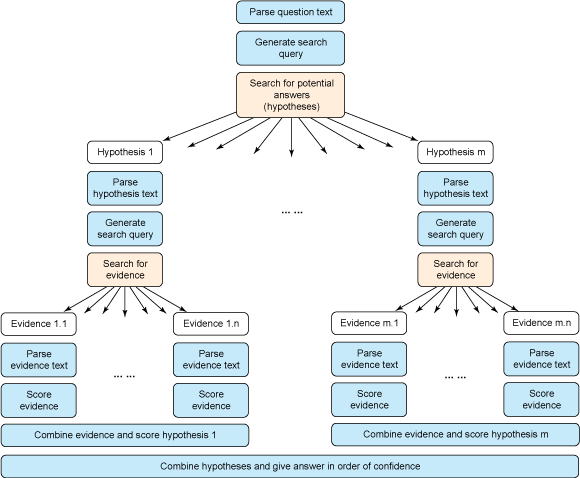
Now IBM Watson is adapted to answer questions like “What is a patient with a given set of symptoms and a given medical history?”, Providing him with all the necessary information for this. When diagnosing, IBM Watson uses the same algorithm for answering questions as in the Jeopardy game.
')
The consultant for IBM in this project is Dr. Eliot Siegal from the University of Maryland. He had already witnessed the creation of similar programs for the diagnosis of diseases in the 70s and 80s, but all of them were unsuccessful, Forbes magazine writes .
A year and a half ago, Dr. Seagal helped programmers from IBM to determine the range of medical journals and textbooks that a computer needs to learn for the first time, and what questions it needs to learn to answer to begin with. Watson began reading publications from the national medical database PubMed and dozens of textbooks. Soon he was able to answer questions on texts and exams that students of the medical college take. Of course, no student could grasp the same amount of information, so IBM Watson was out of competition here.
Watson then began trying to solve well-known clinicopathological puzzles that are published in every issue of the New England Journal of Medicine . Training takes place in the same way as in the first stage, when the computer responded better and better to the questions of Jeopardy, until it reached the world champion level. So here, the accuracy of the IBM Watson diagnoses is gradually increasing.
The next stage of training will be more difficult. The computer will load records with patient histories, so that Watson will receive information about the methods of treatment that were actually used in practice and their effectiveness. Then you need to replenish its database with detailed data sets on individual diseases, for example, on leukemia - such records are kept in medical institutes that specialize in studying a particular disease.
Although computers are now widely used as reference tools for diagnosis , but IBM Watson is a completely different system. In the future, IBM Watson should be the ideal diagnostician who, by analyzing the patient's symptoms and medical history, is able to diagnose and prescribe the most likely treatment.
According to the developers, in three to five years, Watson will be ready for the first pilot tests for treating real patients, and in 8-10 years these computers can be widely used in hospitals as a diagnostic tool.
Additional information about IBM Watson in medicine and additional literature can be found here .
On another data mining front, IBM is showing even more significant success. The developers of the IBM Watson supercomputer (which is able to answer questions, sorting out an array of unstructured data) continue to pump its database with medical information. According to them, the computer has already learned all the information that a medical college student should know. And this is just the beginning of learning.
It is quite possible that the developers of IBM Watson are inspired by the Dr. House series. From this film, the masses for the first time were able to find out how the diagnostician works. We see that his work is extremely formal and resembles an intellectual puzzle, and after all, IBM Watson is the champion in the intellectual show Jeopardy - a game where you need to quickly answer questions (the Russian clone is “Your game”). A computer is much better suited to solving such puzzles, because it requires a wide erudition and very deep knowledge. At the same time, ordinary doctors perfectly diagnose frequently occurring diseases (a list of the 100 most common diagnoses ), but if something unusual is found, then the doctor usually lacks neither experience nor knowledge.
Now IBM Watson is adapted to answer questions like “What is a patient with a given set of symptoms and a given medical history?”, Providing him with all the necessary information for this. When diagnosing, IBM Watson uses the same algorithm for answering questions as in the Jeopardy game.
')
The consultant for IBM in this project is Dr. Eliot Siegal from the University of Maryland. He had already witnessed the creation of similar programs for the diagnosis of diseases in the 70s and 80s, but all of them were unsuccessful, Forbes magazine writes .
A year and a half ago, Dr. Seagal helped programmers from IBM to determine the range of medical journals and textbooks that a computer needs to learn for the first time, and what questions it needs to learn to answer to begin with. Watson began reading publications from the national medical database PubMed and dozens of textbooks. Soon he was able to answer questions on texts and exams that students of the medical college take. Of course, no student could grasp the same amount of information, so IBM Watson was out of competition here.
Watson then began trying to solve well-known clinicopathological puzzles that are published in every issue of the New England Journal of Medicine . Training takes place in the same way as in the first stage, when the computer responded better and better to the questions of Jeopardy, until it reached the world champion level. So here, the accuracy of the IBM Watson diagnoses is gradually increasing.
The next stage of training will be more difficult. The computer will load records with patient histories, so that Watson will receive information about the methods of treatment that were actually used in practice and their effectiveness. Then you need to replenish its database with detailed data sets on individual diseases, for example, on leukemia - such records are kept in medical institutes that specialize in studying a particular disease.
Although computers are now widely used as reference tools for diagnosis , but IBM Watson is a completely different system. In the future, IBM Watson should be the ideal diagnostician who, by analyzing the patient's symptoms and medical history, is able to diagnose and prescribe the most likely treatment.
According to the developers, in three to five years, Watson will be ready for the first pilot tests for treating real patients, and in 8-10 years these computers can be widely used in hospitals as a diagnostic tool.
Additional information about IBM Watson in medicine and additional literature can be found here .
Source: https://habr.com/ru/post/120103/
All Articles