The use of metamodel in the design of databases with several abstract layers (Part 2)
Recently, relational database management systems have been slightly pressed by systems with alternative data models. This is partly due to performance improvement tasks by simplifying storage structures. On the other hand, there is a search for ways to expand expressive means, including through the transition to richer information models. After all, many realized that raising the level of abstraction of the domain by one order gives the expansion of the application of the product tenfold and the opportunity to occupy many adjacent niches, sometimes increasing the number of customers hundreds and thousands of times.
The first part: http://habrahabr.ru/blogs/sql/119317/
Relational, hierarchical, network, key-value, and others. The DBMS defines only the data model, but in the choice of the information model (not to be confused with the data model) we are freer. In any case, the decomposition and mapping of the elements of the information model into the data model will be required.
For example, the classic IDEF1X information model consists of the following elements: essence, attribute, one-to-one relationship, one-to-many relationship, many-to-many relationship, categorization (one-to-one relationship). And the relational data model of RDBMS has only: a table, a field, a one-to-many relationship. The entity is displayed in one or several tables, all types of links are presented as one-to-many (there is simply no other type in the vast majority of RDBMS), categorization is introduced in the manner I described in the first part of the article .
')
What prevents to raise the level of abstraction? First of all, the fact that developers are forced to make part of the information model in the application . And that means - to fix this part of the model, losing the flexibility of the settings for the subject area. I see a solution to this problem in the introduction of dynamically interpreted metamodels used in parallel with a relational or other repository. Metamodels reduce uncertainty in the description of the subject area and allow you to remove “attachment points” from applications and get rid of rigid fixation on the specifics of the tasks.
I tried to put together most of the information modeling components needed to develop an application. At the end of the first part there was a scheme:
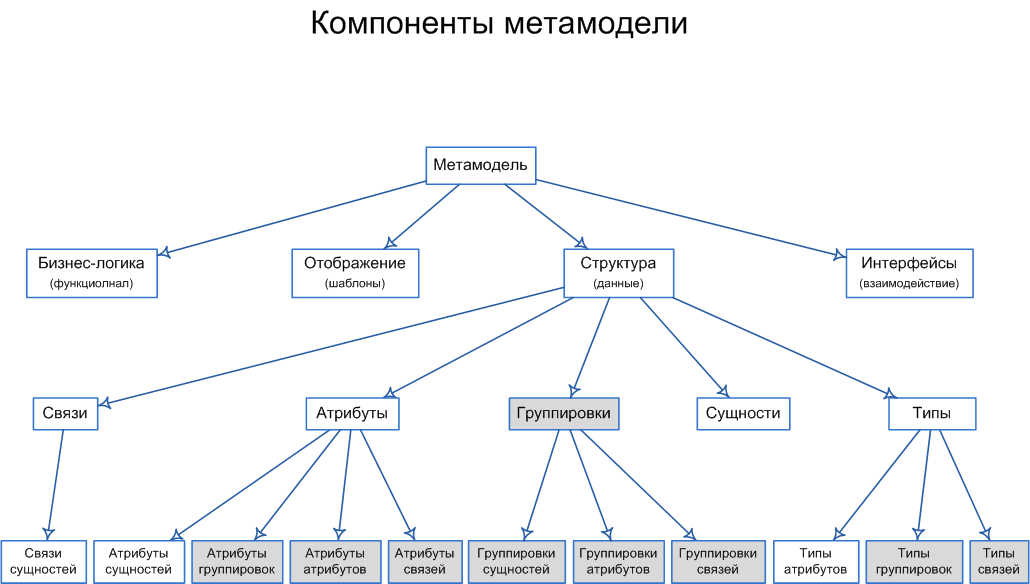
Now I will explain it in more detail. The bottom line of the diagram shows white components that are present in the relational data directory, and gray ones - components that require decomposition or meta descriptions to be placed in the RDBMS. Consider them in more detail:
Entity groupings
The first thing that is often lacking is the ability to combine the entities of the subject area into groups.
Application : entities may not be homogeneous in nature, they belong to different levels of abstraction of the same subject area, or to different subject areas served by the same database or we want to select several clusters / zones in the subject area.
Solution options: the use of prefixes in table names, coloring database structures with different colors, but more often the software that works with the database “knows” about the groups, the groups are “protected” in the code, and the model without the code is not complete .
Attribute groupings
It seems natural to group attributes of entities into semantic blocks that are related functionally, semantically, or related to different aspects of entity modeling.
Application : for example, it is convenient to group the fields related to the address (country, city, street, house, index, etc.) or two fields describe one attribute (how latitude and longitude describe the attribute "Coordinate").
Solution options: the introduction of prefixes in the field names, enumeration of fields in order, but basically, this aspect of the information model is “sewn up” in the user interface and we see that the model is not complete without an interface .
Linking groups
Relationships between tables are not always named, so the grouping of relationships by name is almost not found, but there are tasks for which it is extremely necessary.
Application : Example # 1 - many-to-many people link through the cross-table and we need to select some of the links as “related”, and some as “friendly” or “workers”. There is another common case (example # 2) of groupings when there are several many-to-many cross tables, and we need to group vehicle owners, property owners, and pet owners into several groups: former owners, current owners, and persons disputing .
Solution options: for the case of # 1 - simply enter the flag in the cross table or add the directory of groups of links. For case # 2, of course, you can enter the same flags and directories for different tables, but then I would like to select all “current owners” with a single query. To do this, we can apply an abstract "convolution", as described in the first part .
Attributes and grouping types
Each of the above groups can have its own attributes and types, it seems quite natural. And for different groups there are many examples and means of implementation.
Relationship Attributes
The links between entities are far from uniform, and certainly not binary. We may need to attach the establishment date, communication strength or confidence factor to the information, the source of information or the user (owner of the communication) and other attributes to the relations.
Application : for example, the relationship between the specialist and the position may contain the date of entry into the position and the appointed salary.
Solution options: To describe the attributes of relationships, we usually use the fields of tables that describe the entities themselves or the fields of tables-connections. That is, the application will already "know" and "distinguish" by the name of the field, where the attribute is an entity, and where the attribute is a link.
Attribute Attributes
Such a tautology, but not such a nonsense, if you think about it, then in many subject areas an entity attribute may have a number of its own attributes.
Application : for example, the sensor reading can be supplemented with an error estimate, units of change, time taken to read, a reference to the employee who made the change or entered the data into the system.
Solution options: usually they simply make two, three or more fields in one table, and at the level of the user interface or application it is already assumed that one field is an attribute of another.
Types of links
The most important, in my opinion, component of the information model is the type of connection between entities. It is this characteristic that is most often “sewn up” into the application and the user interface, and sometimes it is generally not where it is explicitly defined and is processed directly by the user, taking his attention away.
Application : select several types (not a complete list): one-to-one, many-to-many, link with the directory, link of the type “Master-Detail”, link of the type “container”, etc.
Solution options: a link to the directory can be realized in the user interface in the form of a combo box or an auto-incremental input field; Master-Detail can be implemented by pop-up windows, several grids, a tree or combo box and grid and many more ways. Depending on “what” it is this “Master-Detail”, for example, you can display a log grouped by date, purchased goods or weak links — for example, data on the occupancy of people in hotel rooms. If we compare the connection between the “hotel” and the “rooms” with the connection of the “rooms” with the “guests”, we note that the rooms are an integral part of the hotel, but with the guests the connection is more “soft”, although you can call it “ Master-Detail. In general, it is possible to write a separate article on the classification of connections, with examples of database structures and application screens.
Thus, we have a number of elements of the information model, which are placed in applications, interfaces, templates, in fact being part of the model. Here, to separate them from purely software and system solutions, a layer of metamodel is necessary. The DBMS is used as a physical storage of two levels of abstraction, both data and metamodel. Dynamic interpretation of the metamodel during the execution of the application allows you to link several levels of abstraction into one.
In the third part, I plan to consider examples of the use of a metamodel in applied problems.
Thanks for attention.
The first part: http://habrahabr.ru/blogs/sql/119317/
Relational, hierarchical, network, key-value, and others. The DBMS defines only the data model, but in the choice of the information model (not to be confused with the data model) we are freer. In any case, the decomposition and mapping of the elements of the information model into the data model will be required.
For example, the classic IDEF1X information model consists of the following elements: essence, attribute, one-to-one relationship, one-to-many relationship, many-to-many relationship, categorization (one-to-one relationship). And the relational data model of RDBMS has only: a table, a field, a one-to-many relationship. The entity is displayed in one or several tables, all types of links are presented as one-to-many (there is simply no other type in the vast majority of RDBMS), categorization is introduced in the manner I described in the first part of the article .
')
What prevents to raise the level of abstraction? First of all, the fact that developers are forced to make part of the information model in the application . And that means - to fix this part of the model, losing the flexibility of the settings for the subject area. I see a solution to this problem in the introduction of dynamically interpreted metamodels used in parallel with a relational or other repository. Metamodels reduce uncertainty in the description of the subject area and allow you to remove “attachment points” from applications and get rid of rigid fixation on the specifics of the tasks.
I tried to put together most of the information modeling components needed to develop an application. At the end of the first part there was a scheme:
Now I will explain it in more detail. The bottom line of the diagram shows white components that are present in the relational data directory, and gray ones - components that require decomposition or meta descriptions to be placed in the RDBMS. Consider them in more detail:
Entity groupings
The first thing that is often lacking is the ability to combine the entities of the subject area into groups.
Application : entities may not be homogeneous in nature, they belong to different levels of abstraction of the same subject area, or to different subject areas served by the same database or we want to select several clusters / zones in the subject area.
Solution options: the use of prefixes in table names, coloring database structures with different colors, but more often the software that works with the database “knows” about the groups, the groups are “protected” in the code, and the model without the code is not complete .
Attribute groupings
It seems natural to group attributes of entities into semantic blocks that are related functionally, semantically, or related to different aspects of entity modeling.
Application : for example, it is convenient to group the fields related to the address (country, city, street, house, index, etc.) or two fields describe one attribute (how latitude and longitude describe the attribute "Coordinate").
Solution options: the introduction of prefixes in the field names, enumeration of fields in order, but basically, this aspect of the information model is “sewn up” in the user interface and we see that the model is not complete without an interface .
Linking groups
Relationships between tables are not always named, so the grouping of relationships by name is almost not found, but there are tasks for which it is extremely necessary.
Application : Example # 1 - many-to-many people link through the cross-table and we need to select some of the links as “related”, and some as “friendly” or “workers”. There is another common case (example # 2) of groupings when there are several many-to-many cross tables, and we need to group vehicle owners, property owners, and pet owners into several groups: former owners, current owners, and persons disputing .
Solution options: for the case of # 1 - simply enter the flag in the cross table or add the directory of groups of links. For case # 2, of course, you can enter the same flags and directories for different tables, but then I would like to select all “current owners” with a single query. To do this, we can apply an abstract "convolution", as described in the first part .
Attributes and grouping types
Each of the above groups can have its own attributes and types, it seems quite natural. And for different groups there are many examples and means of implementation.
Relationship Attributes
The links between entities are far from uniform, and certainly not binary. We may need to attach the establishment date, communication strength or confidence factor to the information, the source of information or the user (owner of the communication) and other attributes to the relations.
Application : for example, the relationship between the specialist and the position may contain the date of entry into the position and the appointed salary.
Solution options: To describe the attributes of relationships, we usually use the fields of tables that describe the entities themselves or the fields of tables-connections. That is, the application will already "know" and "distinguish" by the name of the field, where the attribute is an entity, and where the attribute is a link.
Attribute Attributes
Such a tautology, but not such a nonsense, if you think about it, then in many subject areas an entity attribute may have a number of its own attributes.
Application : for example, the sensor reading can be supplemented with an error estimate, units of change, time taken to read, a reference to the employee who made the change or entered the data into the system.
Solution options: usually they simply make two, three or more fields in one table, and at the level of the user interface or application it is already assumed that one field is an attribute of another.
Types of links
The most important, in my opinion, component of the information model is the type of connection between entities. It is this characteristic that is most often “sewn up” into the application and the user interface, and sometimes it is generally not where it is explicitly defined and is processed directly by the user, taking his attention away.
Application : select several types (not a complete list): one-to-one, many-to-many, link with the directory, link of the type “Master-Detail”, link of the type “container”, etc.
Solution options: a link to the directory can be realized in the user interface in the form of a combo box or an auto-incremental input field; Master-Detail can be implemented by pop-up windows, several grids, a tree or combo box and grid and many more ways. Depending on “what” it is this “Master-Detail”, for example, you can display a log grouped by date, purchased goods or weak links — for example, data on the occupancy of people in hotel rooms. If we compare the connection between the “hotel” and the “rooms” with the connection of the “rooms” with the “guests”, we note that the rooms are an integral part of the hotel, but with the guests the connection is more “soft”, although you can call it “ Master-Detail. In general, it is possible to write a separate article on the classification of connections, with examples of database structures and application screens.
Thus, we have a number of elements of the information model, which are placed in applications, interfaces, templates, in fact being part of the model. Here, to separate them from purely software and system solutions, a layer of metamodel is necessary. The DBMS is used as a physical storage of two levels of abstraction, both data and metamodel. Dynamic interpretation of the metamodel during the execution of the application allows you to link several levels of abstraction into one.
In the third part, I plan to consider examples of the use of a metamodel in applied problems.
Thanks for attention.
Source: https://habr.com/ru/post/119885/
All Articles