LogLog - find the number of unique elements
Hello, Habr! You and I have already indulged in Bloom and MinHash filters . Today, the talk will be about another probabilistic-randomized algorithm that allows determining the approximate number of unique elements in large amounts of data with minimal memory costs.
To begin with, we will set ourselves a task: suppose that we have a large amount of textual data - say, the fruits of the literary works of the notorious Shakespeare, and we need to count the number of different words found in this volume. A typical solution is a counter with a truncated hash table, where the keys are words without associated values.
The method is good for everyone, but it requires a relatively large amount of memory for its work, and, as you know, we are restless efficiency geniuses. Why a lot, if you can little - the approximate size of the vocabulary of the above-mentioned Shakespeare, you can calculate using only 128 bytes of memory.
')
As usual, we will need some kind of hash function, so the algorithm itself will not receive the data itself, but their hashes. The task of the hash function, as is usually the case in randomized algorithms, is to turn the ordered data into “random”, that is, in a more or less uniform spreading of the domain over the range of values. For the test implementation, I chose FNV-1a as a good and simple hash function:
Well, let's turn on the brain and look at the hashes that it gives out in binary representation:
Pay attention to the index of the first non-zero least significant bit for each hash, add a unit to this index and call it rank (rank (1) = 1, rank (10) = 2, ...):
The probability that we will encounter a hash with rank 1 is 0.5, with rank 2 - 0.25, with rank r - 2 - r . In other words, among 2 r hashes, one hash of rank r must be met. In a completely different way, if you memorize the highest detected rank R , then 2 R will fit as a rough estimate of the number of unique elements among those already viewed.
Well, the theory of probability is such that we can find a large rank R in a small sample, or a small one in an enormous sample, and generally 2 31 and 2 32 are two big differences, say you are right, that is why such a single estimate very rude. What to do?
Instead of a single hash function, you can use a bundle of them, and then somehow “average” the estimates obtained for each of them. This approach is bad because we will need a lot of functions and we will have to consider them all. Therefore, we will do the following trick: we will bite off the k high-order bits of each of the hashes, and using the value of these bits as an index, we will calculate not one estimate, but an array of 2 k estimates, and then we will get an integral one based on them.
In fact, there are several variations of the LogLog algorithm, we will look at a relatively recent version - HyperLogLog. This version allows to reach the magnitude of the standard error:
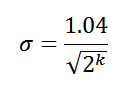
Therefore, when using 8 high bits as an index, we get a standard error of 6.5% ( σ = 0.065) of the true number of unique elements. And most importantly, if you arm yourself with the skill of the theory of probability, you can come to the following final assessment:
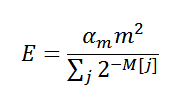
, where α m is the correction coefficient, m is the total number of estimates (2 k ), M is an array of the estimates themselves. Now we know almost everything, it's time to implement :
Let us estimate how many bytes of memory we use, k is equal to 8, therefore, the array M consists of 256 elements, each of them, conditionally, takes 4 bytes, which totals 1 KB. Not bad, but I would like less. If you think about it, you can reduce the size of a unit estimate from the array M - you need only ceil (log2 (32 + 1 - k )) bits, which, for k = 8, is 5 bits. In total, we have 160 bytes, which is much better, but I promised even less.
To be less, you need to know in advance the maximum possible number of unique elements in our data - N. Indeed, if we know it, there is no need to use all possible bits from the hash to determine the rank, ceil (log2 ( N / m )) bits are sufficient. Do not forget that from this number we once again need to take the logarithm to get the size of one element of the array M.
Suppose that in the case of our small set of words, their maximum number is 3,000, then we need only 64 bytes. In the case of Shakespeare, we set N equal to 100,000, and we will have the promised 128 bytes with an error of 6.5%, 192 bytes at 4.6%, 768 at 3.3%. By the way, the actual size of Shakespeare’s vocabulary is about 30,000 words.
Of course, using small “bytes”, for example, 3 bits each is not very efficient in terms of performance. In practice, it is better not to go crazy by building rather long chains of bit operations, but to use the usual native bytes for the architecture. If you do decide to "shallow", do not forget to correct the corrective assessment code.
A small spoon of tar, the error σ is not the maximum error, but the so-called standard error. For us, this means that 65% of the results will have an error of no more than σ , 95% - no more than 2 σ and 99% - no more than 3 σ . It is quite acceptable, but there is always the likelihood of receiving a response with an error greater than expected.
Judging by my experiments, one should not get too carried away with its decrease, especially if there is little data. In this case, the correction procedure begins to work, which does not always cope with its duties. It seems that the algorithm requires testing and tuning for a specific task, unless, of course, this is not some kind of stupid mistake in my implementation. This is not quite true .
When using a 32-bit hash function, the algorithm allows to calculate up to 10 9 unique elements with a minimum achievable standard error of about 0.5%. In memory, with such an error, you need about 32-64 KB. In general, LogLog is ideal for on-line work with live data streams.
That's all. Until!
To begin with, we will set ourselves a task: suppose that we have a large amount of textual data - say, the fruits of the literary works of the notorious Shakespeare, and we need to count the number of different words found in this volume. A typical solution is a counter with a truncated hash table, where the keys are words without associated values.
The method is good for everyone, but it requires a relatively large amount of memory for its work, and, as you know, we are restless efficiency geniuses. Why a lot, if you can little - the approximate size of the vocabulary of the above-mentioned Shakespeare, you can calculate using only 128 bytes of memory.
')
Idea
As usual, we will need some kind of hash function, so the algorithm itself will not receive the data itself, but their hashes. The task of the hash function, as is usually the case in randomized algorithms, is to turn the ordered data into “random”, that is, in a more or less uniform spreading of the domain over the range of values. For the test implementation, I chose FNV-1a as a good and simple hash function:
function fnv1a(text) { var hash = 2166136261; for (var i = 0; i < text.length; ++i) { hash ^= text.charCodeAt(i); hash += (hash << 1) + (hash << 4) + (hash << 7) + (hash << 8) + (hash << 24); } return hash >>> 0; } Well, let's turn on the brain and look at the hashes that it gives out in binary representation:
fnv1a('aardvark') = 1001100000000001110100100011001 1
fnv1a('abyssinian') = 00101111000100001010001000111 100
fnv1a('accelerator') = 10111011100010100010110001010 100
fnv1a('accordion') = 0111010111000100111010000001100 1
fnv1a('account') = 00101001010011111100011101011 100
fnv1a('accountant') = 0010101001101111110011110010110 1
fnv1a('acknowledgment') = 0000101000010011100000111110 1000
fnv1a('acoustic') = 111100111010111111100101011000 10
fnv1a('acrylic') = 1101001001110011011101011101 1000
fnv1a('act') = 0010110101001010010001011000101 1Pay attention to the index of the first non-zero least significant bit for each hash, add a unit to this index and call it rank (rank (1) = 1, rank (10) = 2, ...):
function rank(hash) { var r = 1; while ((hash & 1) == 0 && r <= 32) { ++r; hash >>>= 1; } return r; } The probability that we will encounter a hash with rank 1 is 0.5, with rank 2 - 0.25, with rank r - 2 - r . In other words, among 2 r hashes, one hash of rank r must be met. In a completely different way, if you memorize the highest detected rank R , then 2 R will fit as a rough estimate of the number of unique elements among those already viewed.
Well, the theory of probability is such that we can find a large rank R in a small sample, or a small one in an enormous sample, and generally 2 31 and 2 32 are two big differences, say you are right, that is why such a single estimate very rude. What to do?
Instead of a single hash function, you can use a bundle of them, and then somehow “average” the estimates obtained for each of them. This approach is bad because we will need a lot of functions and we will have to consider them all. Therefore, we will do the following trick: we will bite off the k high-order bits of each of the hashes, and using the value of these bits as an index, we will calculate not one estimate, but an array of 2 k estimates, and then we will get an integral one based on them.
HyperLogLog
In fact, there are several variations of the LogLog algorithm, we will look at a relatively recent version - HyperLogLog. This version allows to reach the magnitude of the standard error:
Therefore, when using 8 high bits as an index, we get a standard error of 6.5% ( σ = 0.065) of the true number of unique elements. And most importantly, if you arm yourself with the skill of the theory of probability, you can come to the following final assessment:
, where α m is the correction coefficient, m is the total number of estimates (2 k ), M is an array of the estimates themselves. Now we know almost everything, it's time to implement :
var pow_2_32 = 0xFFFFFFFF + 1; function HyperLogLog(std_error) { function log2(x) { return Math.log(x) / Math.LN2; } function rank(hash, max) { var r = 1; while ((hash & 1) == 0 && r <= max) { ++r; hash >>>= 1; } return r; } var m = 1.04 / std_error; var k = Math.ceil(log2(m * m)), k_comp = 32 - k; m = Math.pow(2, k); var alpha_m = m == 16 ? 0.673 : m == 32 ? 0.697 : m == 64 ? 0.709 : 0.7213 / (1 + 1.079 / m); var M = []; for (var i = 0; i < m; ++i) M[i] = 0; function count(hash) { if (hash !== undefined) { var j = hash >>> k_comp; M[j] = Math.max(M[j], rank(hash, k_comp)); } else { var c = 0.0; for (var i = 0; i < m; ++i) c += 1 / Math.pow(2, M[i]); var E = alpha_m * m * m / c; // -- make corrections if (E <= 5/2 * m) { var V = 0; for (var i = 0; i < m; ++i) if (M[i] == 0) ++V; if (V > 0) E = m * Math.log(m / V); } else if (E > 1/30 * pow_2_32) E = -pow_2_32 * Math.log(1 - E / pow_2_32); // -- return E; } } return {count: count}; } function fnv1a(text) { var hash = 2166136261; for (var i = 0; i < text.length; ++i) { hash ^= text.charCodeAt(i); hash += (hash << 1) + (hash << 4) + (hash << 7) + (hash << 8) + (hash << 24); } return hash >>> 0; } var words = ['aardvark', 'abyssinian', ..., 'zoology']; // 2 336 words var seed = Math.floor(Math.random() * pow_2_32); // make more fun var log_log = HyperLogLog(0.065); for (var i = 0; i < words.length; ++i) log_log.count(fnv1a(words[i]) ^ seed); var count = log_log.count(); alert(count + ', error ' + (count - words.length) / (words.length / 100.0) + '%'); Let us estimate how many bytes of memory we use, k is equal to 8, therefore, the array M consists of 256 elements, each of them, conditionally, takes 4 bytes, which totals 1 KB. Not bad, but I would like less. If you think about it, you can reduce the size of a unit estimate from the array M - you need only ceil (log2 (32 + 1 - k )) bits, which, for k = 8, is 5 bits. In total, we have 160 bytes, which is much better, but I promised even less.
To be less, you need to know in advance the maximum possible number of unique elements in our data - N. Indeed, if we know it, there is no need to use all possible bits from the hash to determine the rank, ceil (log2 ( N / m )) bits are sufficient. Do not forget that from this number we once again need to take the logarithm to get the size of one element of the array M.
Suppose that in the case of our small set of words, their maximum number is 3,000, then we need only 64 bytes. In the case of Shakespeare, we set N equal to 100,000, and we will have the promised 128 bytes with an error of 6.5%, 192 bytes at 4.6%, 768 at 3.3%. By the way, the actual size of Shakespeare’s vocabulary is about 30,000 words.
Other thoughts
Of course, using small “bytes”, for example, 3 bits each is not very efficient in terms of performance. In practice, it is better not to go crazy by building rather long chains of bit operations, but to use the usual native bytes for the architecture. If you do decide to "shallow", do not forget to correct the corrective assessment code.
A small spoon of tar, the error σ is not the maximum error, but the so-called standard error. For us, this means that 65% of the results will have an error of no more than σ , 95% - no more than 2 σ and 99% - no more than 3 σ . It is quite acceptable, but there is always the likelihood of receiving a response with an error greater than expected.
When using a 32-bit hash function, the algorithm allows to calculate up to 10 9 unique elements with a minimum achievable standard error of about 0.5%. In memory, with such an error, you need about 32-64 KB. In general, LogLog is ideal for on-line work with live data streams.
That's all. Until!
Source: https://habr.com/ru/post/119852/
All Articles