NetApp Metrocluster

In 2007, the Forrester consulting agency conducted a survey of 250 IT specialists to assess the risks of accidents for IT, both inside and outside the data center, for example, the risks of natural accidents and disasters.
After processing and publishing the results, it became clear that the usual means of ensuring fault tolerance in the form of, for example, the traditional “redundant, redundant controller and RAID” can protect only 31% of all possible failures.
')
On the graph, you also see such IT disasters as power failures (" - what happened to your electricity? - It blinked . "), Software problems (" ... and will be closed "), human errors (" as you said the name of the volume, which needed to be unmounted and banged? "), network settings errors (" - and which interface should I use? - try eth0. "), as well as various natural ( and not so ) cataclysms, such as fires , floods, and so on.
Thus, it becomes clear that traditional data health protection tools protect it, alas, not enough, no matter how many “nines” you are promised in advertising. And when the cost of data loss or downtime becomes quite substantial, the question arises of finding a solution that provides greater reliability than traditional solutions.
Typically, to protect data from local disasters, whether it is a power failure, fire, " conducting investigative measures ", and other similar force majeure events, the method of data replication to remote storage is used. These tools today offer almost all manufacturers of storage systems.
However, for beginners, familiarity with fault-tolerant solutions often comes as a surprise that the presence of replication and a remote copy of your production data does not mean true fault tolerance.
The data you have saved, but in order to use this data often need quite extensive reconfiguration. It is necessary to break replication from a source that is no longer working, transfer the copy to online, explain to the servers that the data no longer lies on this system (with such IP and WWPN), but on the one with completely different addresses and properties.
You need to double-check all the settings, rewrite them (do not forget and do not mix), make sure that everything starts, and only after that your servers will be ready to start from the saved replica.
All this is often complicated by the fact that not one application stores data on the system, but usually many different ones, each with its own rules and ways of organizing fault tolerance, these replicas are often managed in different ways, created in different programs, and so on.
In addition, the switching process itself often happens inappropriately.
This is done somewhere entirely by hand, somewhere semi-automatically, but, as a rule, there is no general solution, not for each application separately, but not for the entire infrastructure as a whole.
But the storage system in the enterprise often use many dozens of different applications. And this whole "move" must be done for each of them!
No, not in vain, oh, not in vain, the Russian people equate two moves to one fire.
So why not assign all these tasks directly to the storage controller itself? Why not make a storage system that switches to its “replica” simply and “transparently” for applications?
It is from this simple idea that NetApp Metrocluster was born - a software and hardware solution for distributed cluster storage systems.
The idea behind Metrocluster was, as often with NetApp, simple and ingenious.
Each controller of the pair that makes up the cluster (so far, unfortunately, there can be only two controllers), two sets of disks are connected at the current site. One set is his own, and the second one is an exact synchronous copy of the data of the neighbor disk set. In addition, since modern FCs have two equal access ports, each disk is connected by one port to the local and the second to the remote controller, crosswise, each controller thus has access as the main set of disks so to the copy, however, at a particular point in time, until the cluster takeover happened, it can only work with “its own set”. Each record arriving at the controller is synchronously mirrored to the “second set” of disks at the neighbor.
In the event of a crash or any “abnormal event,” the controller, in addition to accessing “its” data, gets access to the cluster partner's data, and also takes over all its resources, such as the IP addresses of its Ethernet interfaces, WWPN interfaces FC, LUNs and “network ball” names, DNS names, and so on, so after switching applications continue to work “as before”, the other controller simply serves their data.
It’s just amazing why none of the main vendors of storage systems implemented such a simple but effective model (something very similar in theory, however, it is now trying to start selling EMC in its VPLEX product).
NetApp Metrocluster exists in two versions. This is the so-called Stretched Metrocluster, in which the maximum separation distance of its components is determined by the permissible length of a special cable of a cluster interconnect, not more than 500 meters; and Switched Metrocluster, in which the length is limited only by the maximum length of the Longhaul LW Fiber Channel, currently 100 km.
(The picture from the VMware site shows the use of Metrocluster for VMware vSphere FT, but any applications can be in its place)
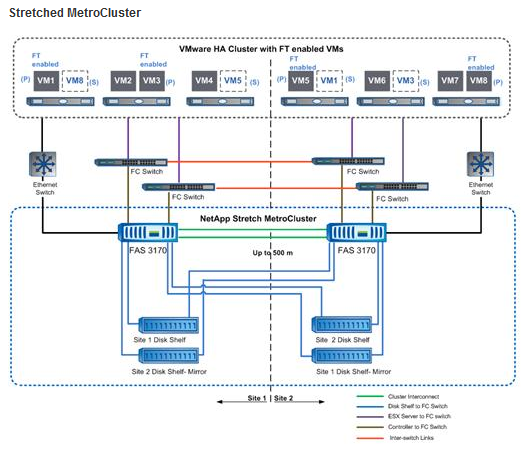
Sretched Metrocluster works just like the more expensive and complex Switched Metrocluster, but can protect mainly from “local” accidents, for example, moving the “half” of the storage to another floor, to the adjacent data center module, or to the next building within 500 meters of cable . But even such a local option will help maintain performance in the event of a fire in a data center, "recess", local power failure, and so on.
Switched Merocluster offers a fully-fledged distributed storage system that can protect against a number of natural disasters (for example, NetApp Metrocluster uses the Turkish production of Ford Motors plants, one of the main industrial enterprises of which is located in a seismically dangerous area).

Thus, you can make a storage system in which one half will be located in Moscow, and the other, for example, in Zelenograd, and both halves will work synchronously, as if logically unified structure. The servers of the Moscow data center will work with half of the storage system on their site, and the Mytishchi or Dolgoprudny servers will work with their own, but in the event of a failure (for example, a power failure in the data center, failure of any part of the storage system, failure of the disks, controller, or the data channel between the datacenters) data will remain available.
Any failure or combination of such failures does not lead to data unavailability, and the process of switching and restoring performance is performed by one simple command. The software applications that use data storage on Metrocluster themselves, outside of the fact of the controller switching, do not require reconfiguration, and the work of the cluster is completely “transparent” for them, as they say.
For complete clarity, let's look at possible failure scenarios.
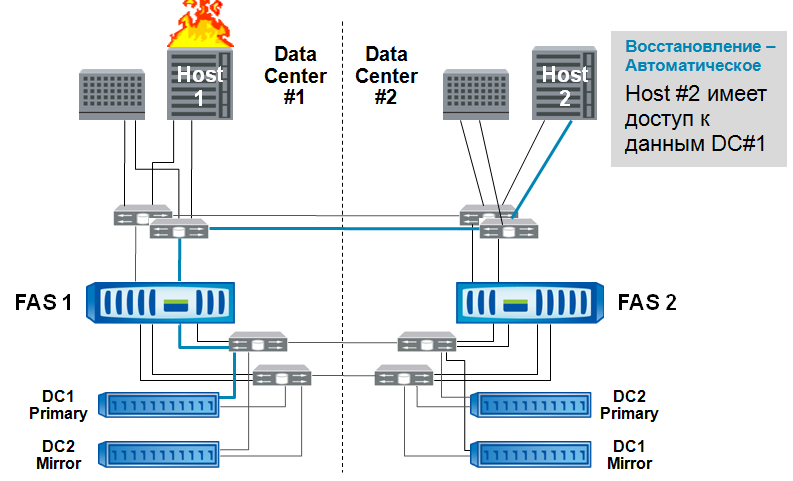
The simplest option is a host failure.
The application is lifted by means of server clustering on host 2, and continues to work, gaining access to data through the “factory” of the original data center to storage 1. (Blue lines show the data access path)
Also the usual story is the failure of the storage system controller.
As in the previously shown case, access switching is automatic.
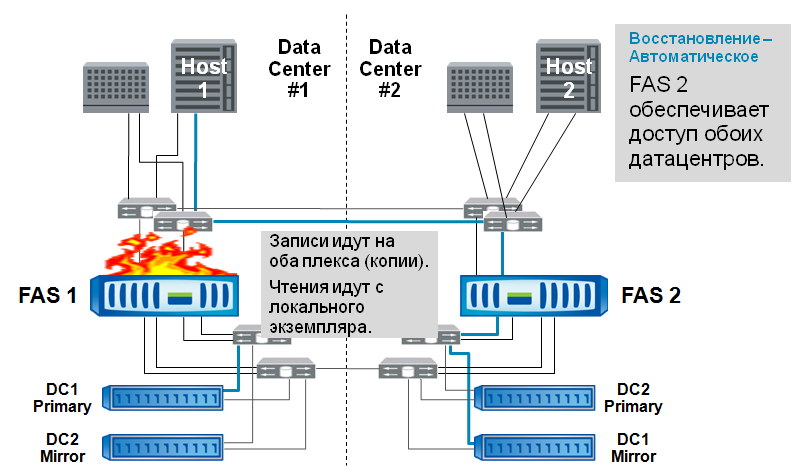
The drama is growing. Failure of half the entire repository. The operator or the control software makes a decision about cluster takeover, which is carried out in a few seconds with one cf takeover command, and is transparent to applications.

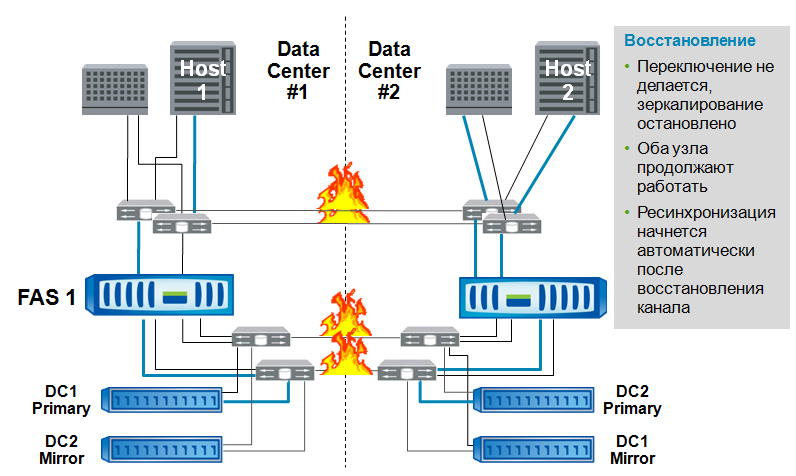
Catastrophe. Lost the entire data center, along with the hosts and half the storage system. Data access saved. The second cluster controller serves “its” data as usual, and the partner’s data from its copy on its website.

Break the communication channel. Cluster controllers are isolated. Work continues in the normal way, when communication is restored, the plexes will be resynchronized. To prevent the situation of a split brain, if your software can create such a situation, you may need a site-arbiter - “tiebreaker”.
Of course, the solution as a whole turns out to be difficult and not cheap (although cheaper than analogs). Two sets of disks for data (a sort of distributed Network RAID-1), one for each site, a dedicated internal “factory” of FC switching, through which communication takes place within the “storage cluster” and mutual synchronous replication of data between sites, but in those cases when it is necessary to ensure the work is not “ in 31% of cases ”, but “always” when the cost of downtime or data damage is high, organizations prefer not to save.
However, with the release of the new FAS3200 / 6200 storage system series, in which a set of licenses for the organization of the metrocluster is already included in the basic delivery, a step has been taken towards a more mass application of this solution.
Source: https://habr.com/ru/post/119776/
All Articles