The use of metamodel in the design of databases with several abstract layers
The classical approach involves the development of database structures, where all entities of the information model are on the same abstract level, are homogeneous. However, complex and poorly structured subject areas lead relational decomposition to a combinatorial explosion, a disproportionate increase in the number of tables and links. And dynamic subject areas in which daily changes are the norm of the life cycle require constant reengineering of the relational database structure.
In such conditions, the rise of the level of abstraction can solve the problem only partially, because moving from specifics to an abstract model, the specificity of the subject area is lost. Therefore, it is necessary to store two logically related layers of abstraction in one database. The logical bundle should be performed by a meta-layer that defines the parameters of a one-to-one mapping of one abstract layer of the model to another.
 (Fig. 1)
(Fig. 1)
For simplicity of explanations, we take a subject area that everyone understands (see Fig. 1). Entities are shown in yellow, and cross-links between them (many-to-many) are marked in green. We have two hierarchies, organizational: company, division, department (we can expand it further by introducing new levels of hierarchy). And the second hierarchy classifies activity: industry, direction, specialization (we can also expand it). But for simplicity, we will limit ourselves to three links in each hierarchy, and already with such a limited information model we will identify the need to raise the level of abstraction.
')
An idealistic domain model is shown in Fig. 1, however, in practice, it may turn out that specialization needs to be tied not only to departments, but also to divisions or even companies (in different organizations this is different, the structure is extremely dynamic and unstable with initial apparent simplicity). Thus, after analyzing and summarizing the structure of several dozen companies, you can come to the following diagram (see Fig. 2). Three entities in one hierarchy can communicate with three entities in another, almost arbitrarily (of all 9 combinations), one relationship does not apply in this case, and we can eliminate it by receiving 8 types of many-to-many relationships. The situation is complicated when each of the links must also have several attribute groups that define the parameters of the number of positions, requirements for employees, certification standards and salaries (taken for example, in fact, the information model is much more complicated).
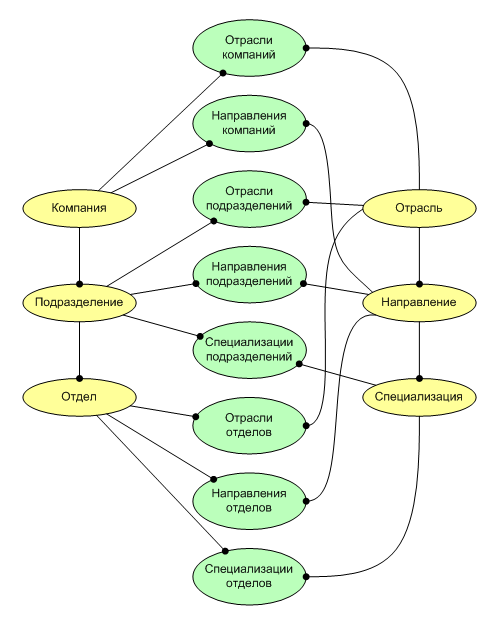 (fig. 2)
(fig. 2)
In Figure 2, we see that even the ER-diagram of such a model becomes difficult to understand, and if each of the links receives another 3-5 groups of parameters, then the cross tables become on the order of two to four dozen, which is generally difficult to display in the diagram. In addition, to create software code and user interfaces for working with a database of such complexity becomes very problematic, and if necessary to make permanent changes to them, such a software product receives a huge cost of ownership and organizational difficulties in maintenance.
The transition to a higher degree of abstraction allows us to highlight the essence of the higher order “structural unit” or “organizational hierarchy”, which is displayed in the database structure into a table with a recursive reference (to itself; the field is usually called ParentId or similarly). From such a table we can expand the hierarchy, with unlimited nesting. The same happens with the second hierarchy, we highlight the essence of a higher order “classification of activity” (see Fig. 3). Thus, we have made the convolution of relations, turning 8 relations “many-to-many” into one such relation. But in this case, when summarizing, semantics was lost, namely: the link between companies and specializations is not needed (in this example), and since companies are structural units in the “organizational hierarchy”, and specializations are included in the “classification of activities”, then according to the diagram in Figure 3, such a connection is possible. However, the information system should prohibit the user to create a connection of this type at the logical level, which is an aspect of information integrity and is an obligatory function of the DBMS.
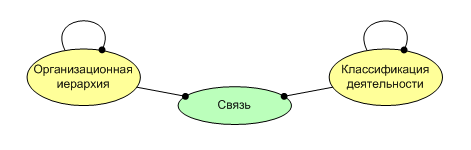 (pic. 3)
(pic. 3)
The logical level is provided by the metamodel of the domain and is interpreted dynamically at the application level, which introduces additional flexibility to the system, since the domain logic can be changed without modifying the program code. To allow or prohibit a certain type of connection at the logical level, it suffices only to specify this in formal terms of the metamodel.
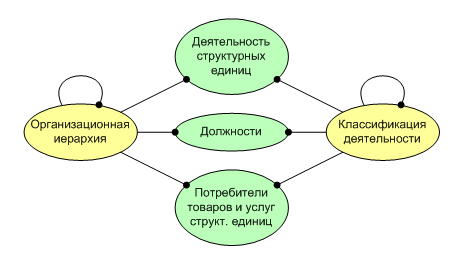 (pic. 4)
(pic. 4)
With the introduction of link parameters (even several groups of parameters), we must modify the structure of Figure 3, breaking the links into three. Moreover, metadata define logical constraints on the establishment of relationships in order to reflect the semantics of the subject area: each company deals with industries and directions; divisions and departments can deal with industries, areas and specializations; divisions and departments (but not companies) have certain positions; companies and divisions (but not departments) are aimed at meeting the demand of other market entities belonging to industries and areas (but not to specializations). Thus, for example, the connection with the attribute group “posts” between a company and a specialization is logically prohibited. Cross tables of the database will contain only one group of parameters for several types of links, as shown in fig. four.
 (Fig. 5)
(Fig. 5)
But the question is where to store the attributes of the entities? Indeed, the table “Organizational hierarchy” can contain only a group of attributes that is common to all entities of the lowest order of abstraction: company, division, department. And all non-intersecting attributes should be placed in separate tables in order not to create a non-normalized structure with a large number of “empty” cells. Thus, we come to the need to have several tables of a lower level of abstraction in the same database with our hierarchical table. And they will be connected with it by a common (more precisely, the same) primary key in the whole group of tables united by a one-to-one relationship with the table “organizational hierarchy”. Such a relationship (see Fig. 5) provides for an entry with the corresponding primary key from the “organizational hierarchy” in only one of the four tables. The “one-to-one-of” or “supertype-and-sybtype-discriminator” link graphic is taken from IDEF1 notation used in a large number of CASE-tools for developing database information models (ErWin, Logic Works, Rational Rose, ER / Studio and etc.).
 (pic. 6)
(pic. 6)
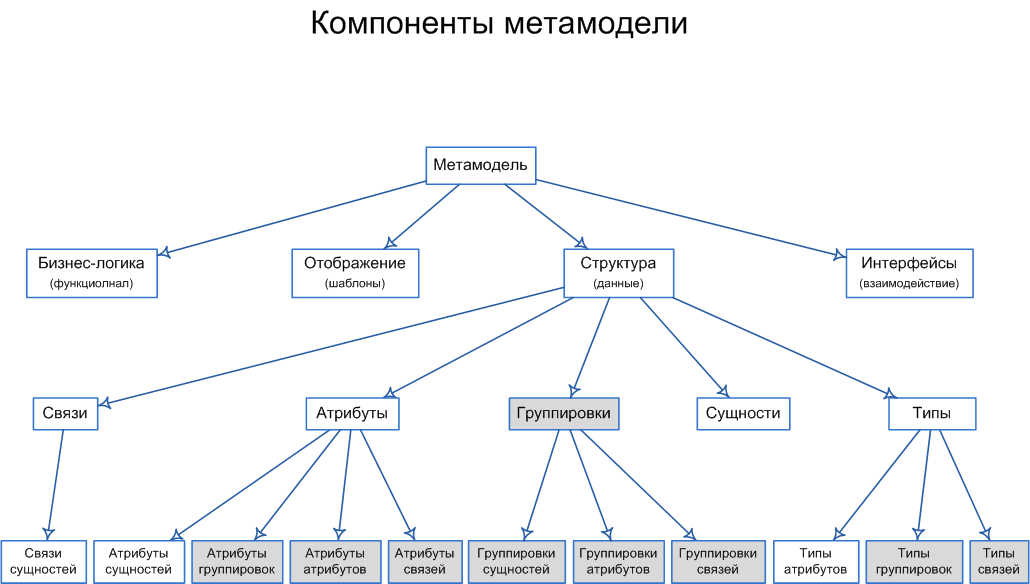
Description of metamodel elements (in Fig. 6):
Profile - entity or profile, is a second-order mapping of the domain object. A profile has a pass-through identifier used to refer to it throughout the entire information system; however, a URI is used for external links.
Template is a template that is analogous to a class in the object model with support for multiple inheritance and indirect inheritance. The plural is that each profile can inherit from several templates, and indirect inheritance is expressed in the possibility of attaching “tabs” - property groups to templates, while templates may not inherit tabs from each other, but receive tabs from any template of another branch of classification .
URI is a unique identifier of a profile used for external links to domain objects, object properties, relationships, and methods. URI allows you to address all elements of the metamodel and all elements of the information model of the domain.
Relation Type - type of communication profiles.
Relation - a relationship between two or more profiles (at the second level of abstraction) or two or more entities (at the level of the relational model).
Link - a link to a profile (entity) that allows you to include several profiles in links.
Tab - a group of profile properties that is displayed in the relational model as a database table.
Property is a property of a profile that is displayed in a relational model, most often, in the form of a database field, but for directories and classifiers a property can be displayed in a “foreign key” or in a reference table and a many-to-many relationship with the profile tab.
Type - the data type assigned to the profile attribute (entity).
Method - a method or function that implements the business logic of the profile.
At the second level of abstraction of the model, we can arrive at the convolution of the relational structure of the base to an even greater generalization (see Fig. 6). In the figure we see the elements of the metamodel, where yellow and green are colors, are responsible for entities and connections, respectively, and a group of gray tables is responsible for the attributes of entities. This structure is suitable for the vast majority of subject areas in the field of applied information systems. This is a metadata structure that describes the structure of tables in more general categories, which allows the software to rely not on the database structure and metadata, but on the structure of the metamodel, that is, a second-order abstraction. However, the metamodel does not have sufficient specificity to solve applied problems and needs to be detailed, which is what happens at the first abstract level (see Fig. 4). Thus, we have two base structures, at different levels of abstraction, stored in the same database in parallel. The connection between them takes place through the unique identifiers, since the Profile is an abstract entity of the second order associated with all entities of the first order by a one-to-one relationship of (or “supertype-and-sybtype-discriminator”, see figure 5 and explanation above).
Continuation will be in the second part.
For discussion, add another scheme, which will be described in the second part:
Thanks for attention.
In such conditions, the rise of the level of abstraction can solve the problem only partially, because moving from specifics to an abstract model, the specificity of the subject area is lost. Therefore, it is necessary to store two logically related layers of abstraction in one database. The logical bundle should be performed by a meta-layer that defines the parameters of a one-to-one mapping of one abstract layer of the model to another.
(Fig. 1)For simplicity of explanations, we take a subject area that everyone understands (see Fig. 1). Entities are shown in yellow, and cross-links between them (many-to-many) are marked in green. We have two hierarchies, organizational: company, division, department (we can expand it further by introducing new levels of hierarchy). And the second hierarchy classifies activity: industry, direction, specialization (we can also expand it). But for simplicity, we will limit ourselves to three links in each hierarchy, and already with such a limited information model we will identify the need to raise the level of abstraction.
')
An idealistic domain model is shown in Fig. 1, however, in practice, it may turn out that specialization needs to be tied not only to departments, but also to divisions or even companies (in different organizations this is different, the structure is extremely dynamic and unstable with initial apparent simplicity). Thus, after analyzing and summarizing the structure of several dozen companies, you can come to the following diagram (see Fig. 2). Three entities in one hierarchy can communicate with three entities in another, almost arbitrarily (of all 9 combinations), one relationship does not apply in this case, and we can eliminate it by receiving 8 types of many-to-many relationships. The situation is complicated when each of the links must also have several attribute groups that define the parameters of the number of positions, requirements for employees, certification standards and salaries (taken for example, in fact, the information model is much more complicated).
(fig. 2)In Figure 2, we see that even the ER-diagram of such a model becomes difficult to understand, and if each of the links receives another 3-5 groups of parameters, then the cross tables become on the order of two to four dozen, which is generally difficult to display in the diagram. In addition, to create software code and user interfaces for working with a database of such complexity becomes very problematic, and if necessary to make permanent changes to them, such a software product receives a huge cost of ownership and organizational difficulties in maintenance.
The transition to a higher degree of abstraction allows us to highlight the essence of the higher order “structural unit” or “organizational hierarchy”, which is displayed in the database structure into a table with a recursive reference (to itself; the field is usually called ParentId or similarly). From such a table we can expand the hierarchy, with unlimited nesting. The same happens with the second hierarchy, we highlight the essence of a higher order “classification of activity” (see Fig. 3). Thus, we have made the convolution of relations, turning 8 relations “many-to-many” into one such relation. But in this case, when summarizing, semantics was lost, namely: the link between companies and specializations is not needed (in this example), and since companies are structural units in the “organizational hierarchy”, and specializations are included in the “classification of activities”, then according to the diagram in Figure 3, such a connection is possible. However, the information system should prohibit the user to create a connection of this type at the logical level, which is an aspect of information integrity and is an obligatory function of the DBMS.
(pic. 3)The logical level is provided by the metamodel of the domain and is interpreted dynamically at the application level, which introduces additional flexibility to the system, since the domain logic can be changed without modifying the program code. To allow or prohibit a certain type of connection at the logical level, it suffices only to specify this in formal terms of the metamodel.
(pic. 4)With the introduction of link parameters (even several groups of parameters), we must modify the structure of Figure 3, breaking the links into three. Moreover, metadata define logical constraints on the establishment of relationships in order to reflect the semantics of the subject area: each company deals with industries and directions; divisions and departments can deal with industries, areas and specializations; divisions and departments (but not companies) have certain positions; companies and divisions (but not departments) are aimed at meeting the demand of other market entities belonging to industries and areas (but not to specializations). Thus, for example, the connection with the attribute group “posts” between a company and a specialization is logically prohibited. Cross tables of the database will contain only one group of parameters for several types of links, as shown in fig. four.
(Fig. 5)But the question is where to store the attributes of the entities? Indeed, the table “Organizational hierarchy” can contain only a group of attributes that is common to all entities of the lowest order of abstraction: company, division, department. And all non-intersecting attributes should be placed in separate tables in order not to create a non-normalized structure with a large number of “empty” cells. Thus, we come to the need to have several tables of a lower level of abstraction in the same database with our hierarchical table. And they will be connected with it by a common (more precisely, the same) primary key in the whole group of tables united by a one-to-one relationship with the table “organizational hierarchy”. Such a relationship (see Fig. 5) provides for an entry with the corresponding primary key from the “organizational hierarchy” in only one of the four tables. The “one-to-one-of” or “supertype-and-sybtype-discriminator” link graphic is taken from IDEF1 notation used in a large number of CASE-tools for developing database information models (ErWin, Logic Works, Rational Rose, ER / Studio and etc.).
(pic. 6)Description of metamodel elements (in Fig. 6):
Profile - entity or profile, is a second-order mapping of the domain object. A profile has a pass-through identifier used to refer to it throughout the entire information system; however, a URI is used for external links.
Template is a template that is analogous to a class in the object model with support for multiple inheritance and indirect inheritance. The plural is that each profile can inherit from several templates, and indirect inheritance is expressed in the possibility of attaching “tabs” - property groups to templates, while templates may not inherit tabs from each other, but receive tabs from any template of another branch of classification .
URI is a unique identifier of a profile used for external links to domain objects, object properties, relationships, and methods. URI allows you to address all elements of the metamodel and all elements of the information model of the domain.
Relation Type - type of communication profiles.
Relation - a relationship between two or more profiles (at the second level of abstraction) or two or more entities (at the level of the relational model).
Link - a link to a profile (entity) that allows you to include several profiles in links.
Tab - a group of profile properties that is displayed in the relational model as a database table.
Property is a property of a profile that is displayed in a relational model, most often, in the form of a database field, but for directories and classifiers a property can be displayed in a “foreign key” or in a reference table and a many-to-many relationship with the profile tab.
Type - the data type assigned to the profile attribute (entity).
Method - a method or function that implements the business logic of the profile.
At the second level of abstraction of the model, we can arrive at the convolution of the relational structure of the base to an even greater generalization (see Fig. 6). In the figure we see the elements of the metamodel, where yellow and green are colors, are responsible for entities and connections, respectively, and a group of gray tables is responsible for the attributes of entities. This structure is suitable for the vast majority of subject areas in the field of applied information systems. This is a metadata structure that describes the structure of tables in more general categories, which allows the software to rely not on the database structure and metadata, but on the structure of the metamodel, that is, a second-order abstraction. However, the metamodel does not have sufficient specificity to solve applied problems and needs to be detailed, which is what happens at the first abstract level (see Fig. 4). Thus, we have two base structures, at different levels of abstraction, stored in the same database in parallel. The connection between them takes place through the unique identifiers, since the Profile is an abstract entity of the second order associated with all entities of the first order by a one-to-one relationship of (or “supertype-and-sybtype-discriminator”, see figure 5 and explanation above).
Continuation will be in the second part.
For discussion, add another scheme, which will be described in the second part:
Thanks for attention.
Source: https://habr.com/ru/post/119317/
All Articles