Pacemaker HA: Network Connections and Dynamic Cluster Resource Allocation
Cluster nodes are very dependent on their physical connection. As practice shows, the majority of cases of working off failove migrations of resources occur due to the fault of network connections. Therefore, a lot depends on how you connect between the nodes and set up resource allocation.
For example, I will consider a cluster consisting of two nodes. One node will be Active, and the other Hot Spare. Our cluster will serve the internal private network and contain the following cluster resources: Mysql server and Mysql VIP. On two Mysql nodes, the server will be launched with Master-Master replication. However, all work will be done with only one instance through a virtual ip address. This scheme allows you to get the fastest failover. Omit the choice of this particular configuration its advantages and disadvantages - we are now interested in the availability of these resources in the event of a drop in network links.

rice 1 Classical layout
')
The main thing you should pay attention to when designing any cluster is the redundancy of the network connection between the nodes of the cluster. In other words, there should be at least two cross-connections between our nodes. They can be combined by bonding into one interface, or you can simply use two different interfaces in a heartbeat or corosyn configuration. When designing a new cluster, I would recommend using corosync, not only because the development of heartbeat is gradually minimized towards the pacemaker and corosync, but because it has more flexible settings for working with several interfaces and can use them in parallel or in “acting and spare ".
Not following the rules of redundancy or the allocation of individual network interfaces can lead to a split brain situation (split brain). That, in principle, does not bode well. Also make sure that you use different network cards, otherwise there will not be much confusion in case of a hardware failure.
Because we have a cluster of two nodes, then we have problems with quorum. Or rather its complete absence, which again hints at the need for a backup connection between the nodes.
At this enough theory turn to practice.
We expose the behavior of the node in the case of a lack of quorum:
Also for a cluster of two nodes, I recommend making the cluster non-symmetrical. This will allow more accurate configuration and catch strange behavior:
An asymmetrical cluster will not start resources unless they have explicitly indicated the values of the cost of their launch on each of the nodes. For example, this is how we can set the value 100 for some P_RESOURCE resource for the first.local node and the value 10 for the second.local node.
This configuration tells us that the resource will start on the first.local node - because its total cost on this node turned out to be more than on the second.local node.
I deliberately omit the primary settings of the nodes, setting up the Bondig (optional), installing the pacemaker and corosync, setting the Master-Master replication, etc. This is already enough on the Internet and is easily located. In turn, I will show how to properly configure the cluster resources, taking into account the network specifics.
We agree that we have a private network: 192.168.56.0/24, Mysql VIP - 192.168.56.133 and two nodes in the network, which we will use to assess the adequacy of the network connection: 192.168.56.1 and 192.168.56.100.
A small digression: for Mysql to work properly in conjunction with the pacemaker, you need to disable its automatic start:
Because Musql server is used only in a private network - the fall of a private connection on the active node should lead to the migration of the resource to another node where the connection is present. We achieve this behavior.
We need to check the status of hosts in a private network. For this we will use the ping cluster resource. At the moment there are the following resources that allow you to monitor the status of the network:
Two of which are obsolete.
Based on these resources, we can manage the placement of resources on nodes. This is done using the location parameter.
For example, first, we describe the configuration of the pacemaker cluster shown in the figure (Fig. 1):
This configuration describes a cluster of two nodes with two Mysql wizards (cloned). Work with the database is conducted through the VIP address.
For the case of an asymmetric cluster, we need to explicitly set the values for location:
This record tells us that “clone” resources should be run on two nodes of the cluster.
Now the same for VIP:
Here we give preference to launch VIP at the node first.local
And complete the setup:
If you now check how failover works, then when it starts, the VIP starts at first.local when it crashes (kill -9 corosync) - it moves to second.local. However, when the node is returned first.local - it comes back. This is due to the fact that the score value for first.local is more than on secon.local (100> 10). To prevent such moves on a high-load cluster, which can lead to undesirable downtime, we need to set the parameter “stickiness” (resource-stickiness):
Now, by repeating the same operation, we have the score score: 110 + 10 = 120 versus 100, which prevents the move.
The cluster works and allows in case of problems with iron / power to switch automatically to the backup node.
Now we will configure monitoring of an internal network. We will ping 192.168.56.1 and 192.168.56.100:
This configuration pings two hosts. Each host is rated at 111 points. The total value for each node is stored in the ping_intranet variable. These values can and should be used when determining the location of the resource. Now we will indicate the VIP so that he will use these points in deciding where he should be:
These additional points are summed up with the previous ones given by us. And on the basis of the total amount is determined by the position of the resource.
The cluster status monitoring with indication of the score value is performed by two utilities: ptest and crm_mon:
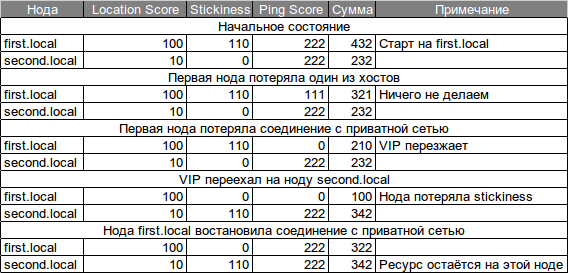
In order to bring the cluster to its original position, it is necessary to transfer the resource to the first.local node:
After that, the resource receives a location with 1,000,000 points (this is INF for the pacemaker) and moves to first.local. It is very important to further unmove this resource, which will return the locatoin glasses to the place, but will not change the location of the resource, since he already has more points (see the initial situation):
You can check whether the ping resource is running and check its value:
This location prohibits placing the P_RESOURCE resource on the node where the ping is less than or equal to 0 (lte - less then or equal) or the ping resource is not running.
You can also combine this rule with the name of the node:
Tells us that if this is the node first.local and ping = <0, then this resource cannot be here.
For example, I will consider a cluster consisting of two nodes. One node will be Active, and the other Hot Spare. Our cluster will serve the internal private network and contain the following cluster resources: Mysql server and Mysql VIP. On two Mysql nodes, the server will be launched with Master-Master replication. However, all work will be done with only one instance through a virtual ip address. This scheme allows you to get the fastest failover. Omit the choice of this particular configuration its advantages and disadvantages - we are now interested in the availability of these resources in the event of a drop in network links.
rice 1 Classical layout
')
The main thing you should pay attention to when designing any cluster is the redundancy of the network connection between the nodes of the cluster. In other words, there should be at least two cross-connections between our nodes. They can be combined by bonding into one interface, or you can simply use two different interfaces in a heartbeat or corosyn configuration. When designing a new cluster, I would recommend using corosync, not only because the development of heartbeat is gradually minimized towards the pacemaker and corosync, but because it has more flexible settings for working with several interfaces and can use them in parallel or in “acting and spare ".
Not following the rules of redundancy or the allocation of individual network interfaces can lead to a split brain situation (split brain). That, in principle, does not bode well. Also make sure that you use different network cards, otherwise there will not be much confusion in case of a hardware failure.
Because we have a cluster of two nodes, then we have problems with quorum. Or rather its complete absence, which again hints at the need for a backup connection between the nodes.
At this enough theory turn to practice.
We expose the behavior of the node in the case of a lack of quorum:
crm configure property no-quorum-policy = "ignore"
Also for a cluster of two nodes, I recommend making the cluster non-symmetrical. This will allow more accurate configuration and catch strange behavior:
crm configure property symmetric-cluster = "false"
An asymmetrical cluster will not start resources unless they have explicitly indicated the values of the cost of their launch on each of the nodes. For example, this is how we can set the value 100 for some P_RESOURCE resource for the first.local node and the value 10 for the second.local node.
location L_RESOURCE_01 P_RESOURCE 100: first.local location L_RESOURCE_02 P_RESOURCE 10: second.local
This configuration tells us that the resource will start on the first.local node - because its total cost on this node turned out to be more than on the second.local node.
I deliberately omit the primary settings of the nodes, setting up the Bondig (optional), installing the pacemaker and corosync, setting the Master-Master replication, etc. This is already enough on the Internet and is easily located. In turn, I will show how to properly configure the cluster resources, taking into account the network specifics.
We agree that we have a private network: 192.168.56.0/24, Mysql VIP - 192.168.56.133 and two nodes in the network, which we will use to assess the adequacy of the network connection: 192.168.56.1 and 192.168.56.100.
A small digression: for Mysql to work properly in conjunction with the pacemaker, you need to disable its automatic start:
chkconfig mysql --list mysql 0: off 1: off 2: off 3: off 4: off 5: off 6: off
Because Musql server is used only in a private network - the fall of a private connection on the active node should lead to the migration of the resource to another node where the connection is present. We achieve this behavior.
We need to check the status of hosts in a private network. For this we will use the ping cluster resource. At the moment there are the following resources that allow you to monitor the status of the network:
ocf: heartbeat: pingd (Deprecated) ocf: pacemaker: pingd (Deprecated) ocf: pacemaker: ping
Two of which are obsolete.
Based on these resources, we can manage the placement of resources on nodes. This is done using the location parameter.
For example, first, we describe the configuration of the pacemaker cluster shown in the figure (Fig. 1):
crm configure primitive P_MYSQL lsb: mysql primitive P_MYSQL_IP ocf: heartbeat: Ipaddr2 params \ ip = "192.168.56.133" nic = "eth0" clone CL_MYSQL P_MYSQL clone-max = "2" clone-node-max = "1" \ globally-unique = "false"
This configuration describes a cluster of two nodes with two Mysql wizards (cloned). Work with the database is conducted through the VIP address.
For the case of an asymmetric cluster, we need to explicitly set the values for location:
location L_MYSQL_01 CL_MYSQL 100: first.local location L_MYSQL_02 CL_MYSQL 100: second.local
This record tells us that “clone” resources should be run on two nodes of the cluster.
Now the same for VIP:
location L_MYSQL_IP_01 P_MYSQL_IP 100: first.local location L_MYSQL_IP_02 P_MYSQL_IP 10: second.local
Here we give preference to launch VIP at the node first.local
And complete the setup:
commit
If you now check how failover works, then when it starts, the VIP starts at first.local when it crashes (kill -9 corosync) - it moves to second.local. However, when the node is returned first.local - it comes back. This is due to the fact that the score value for first.local is more than on secon.local (100> 10). To prevent such moves on a high-load cluster, which can lead to undesirable downtime, we need to set the parameter “stickiness” (resource-stickiness):
crm configure property rsc_defaults resource-stickiness = "110"
Now, by repeating the same operation, we have the score score: 110 + 10 = 120 versus 100, which prevents the move.
The cluster works and allows in case of problems with iron / power to switch automatically to the backup node.
Now we will configure monitoring of an internal network. We will ping 192.168.56.1 and 192.168.56.100:
crm configure primitive P_INTRANET ocf: pacemaker: ping \ params host_list = "192.168.56.1 192.168.56.100" \ multiplier = "111" name = "ping_intranet" \ op monitor interval = "5s" timeout = "20s" clone CL_INTRANET P_INTRANET globally-unique = "false" location L_INTRANET_01 CL_INTRANET 100: first.local location L_INTRANET_02 CL_INTRANET 100: second.local commit
This configuration pings two hosts. Each host is rated at 111 points. The total value for each node is stored in the ping_intranet variable. These values can and should be used when determining the location of the resource. Now we will indicate the VIP so that he will use these points in deciding where he should be:
crm configure location L_MYSQL_IP_PING_INTRANET P_MYSQL_IP rule \ ping_intranet: defined intranet commit
These additional points are summed up with the previous ones given by us. And on the basis of the total amount is determined by the position of the resource.
The cluster status monitoring with indication of the score value is performed by two utilities: ptest and crm_mon:
- ptest -sL - shows the current placement value for each node.
- crm_mon -A - shows the status of the ping_intranet variable for each of the nodes.
In order to bring the cluster to its original position, it is necessary to transfer the resource to the first.local node:
crm resource move P_MYSQL_IP first.local
After that, the resource receives a location with 1,000,000 points (this is INF for the pacemaker) and moves to first.local. It is very important to further unmove this resource, which will return the locatoin glasses to the place, but will not change the location of the resource, since he already has more points (see the initial situation):
crm resource unmove P_MYSQL_IP
What else can you do with location and ping
You can check whether the ping resource is running and check its value:
location L_RESOURCE P_RESOURCE rule -inf: not_defined ping_intranet or ping_intranet lte 0
This location prohibits placing the P_RESOURCE resource on the node where the ping is less than or equal to 0 (lte - less then or equal) or the ping resource is not running.
You can also combine this rule with the name of the node:
location L_RESOURCE P_RESOURCE rule -inf: #host eq first.local and ping_intranet lte 0
Tells us that if this is the node first.local and ping = <0, then this resource cannot be here.
Source: https://habr.com/ru/post/118925/
All Articles