ABBYY FlexiCapture Engine 9.0: technology to extract data from documents is now available to developers
Products based on our data extraction technology are used in various projects around the world and solve both highly specialized tasks in individual industries (education, banking, insurance, telecommunications, and others), as well as major tasks in national-scale projects (unified state exam of the Unified State Exam in Russia population census in a number of countries, presidential elections in Chile , the system for entering reports of the State Employment Center of Ukraine).
ABBYY FlexiCapture exists both in the form of a customizable solution, and in the form of an SDK. Often, deep integration of the data entry subsystem into the customer's information system is impossible when using ready-made solutions. In this case, our SDK comes to the rescue, and now we will tell you about how it works and in what projects it is used.
')
Surely most of you know what an SDK is, for the rest we say: SDK is a set of ready-made function libraries that allows developers to embed ready-made technologies (in our case, recognition and processing technologies) into the solutions they create. Since in this blog we have not yet told you about earlier versions of ABBYY FlexiCapture Engine, at the beginning of the post - a few words about what this product can do at all, and then move on to the new version.
ABBYY FlexiCapture Engine for Windows features:
1. Automatic classification of documents.
2. Processing of any types of documents, regardless of structure:
- rigid structures / structured documents: questionnaires, exam tests, forms, insurance forms, requests for payment of health insurance, tax returns, etc.
- semi-structured documents: invoices, purchase orders, delivery notes, etc.
- unstructured documents: letters, contracts, articles, etc.
3. Processing of multipage documents and tables.
Document processing occurs by comparing the recognized document with a set of predefined templates. At the same time, document templates can be of two types - hard (with a predetermined location of fields in the document) and flexible (in which the location of fields is determined on the basis of specified elements, data, or various kinds of relationships and rules).
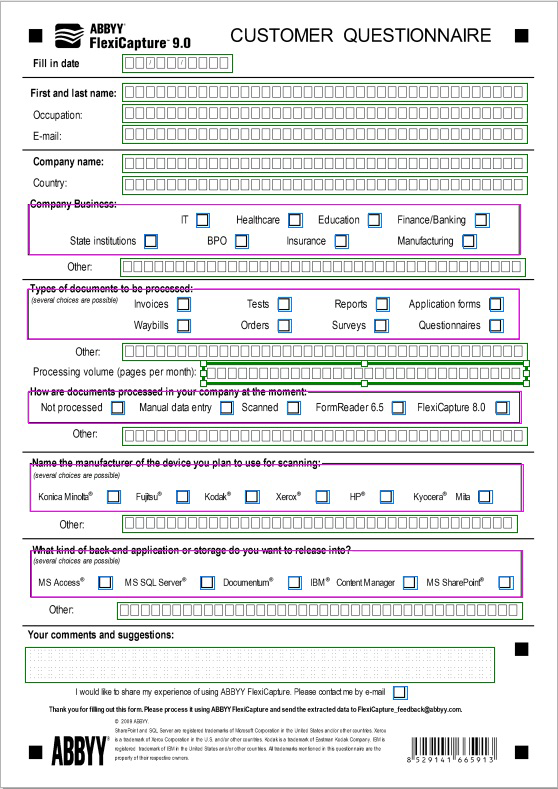
For convenient and quick development of templates, special visual modeling tools are provided. Templates can be created independently for any kind of documents, including unstructured ones - this is very easy to do. Below is an example of a template that was created and used to process invoices (accounts belong to the category of documents with a weak structure), as well as a template for an application form (an example of a document with a rigid structure).

A special verification API in ABBYY FlexiCapture Engine allows you to get a list of fields / characters to be checked by the user. In addition, it is possible to obtain additional information about the recognized fields, for example, coordinates, field type, error list, percentage of confidently recognized characters, which in turn allows you to adjust the quality of validation of recognized characters, as well as track errors occurring during processing and assembly of the document.
After processing, documents can be exported to the target information system in the form of structured data, and additionally in the form of electronic documents in PDF or PDF / A format. This feature allows, along with data extraction for further processing, to simultaneously form archives of electronic documents with the ability to search for documents by their contents. For example, processing invoices in this scenario will automatically upload financial data to the ERP system, and save electronic copies of invoices in PDF format to an electronic archive.
This is a classic scenario of the product, but there are more unusual. For example, ABBYY FlexiCapture Engine can be installed in self-service terminals where we pay for the phone or pay for receipts, the product can be used in security systems or access control systems where you need to recognize data from identity documents (for example, passports).
You can also get data not from a scanner, but from a mobile phone and transfer them not to the company's database, but, for example ... to the tax service. This scenario came up with and implemented the American company Intuit. With the help of a mobile application, any American can take a picture of his income statement (Form W-2, an analogue of the Russian NDFL-2), the program will send the image to the server where our FlexiCapture Engine is installed, after processing the data are sent to the IRS (US tax authority).

In one of the next posts we will tell you more about this project.
And now - about the new version of our product.
What's new in ABBYY FlexiCapture Engine 9.0
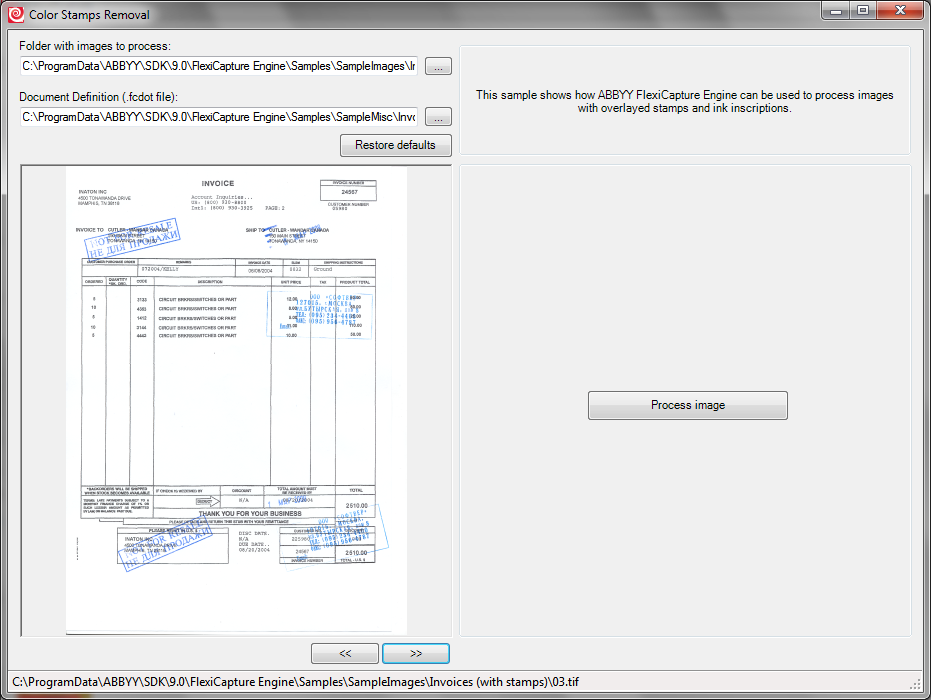
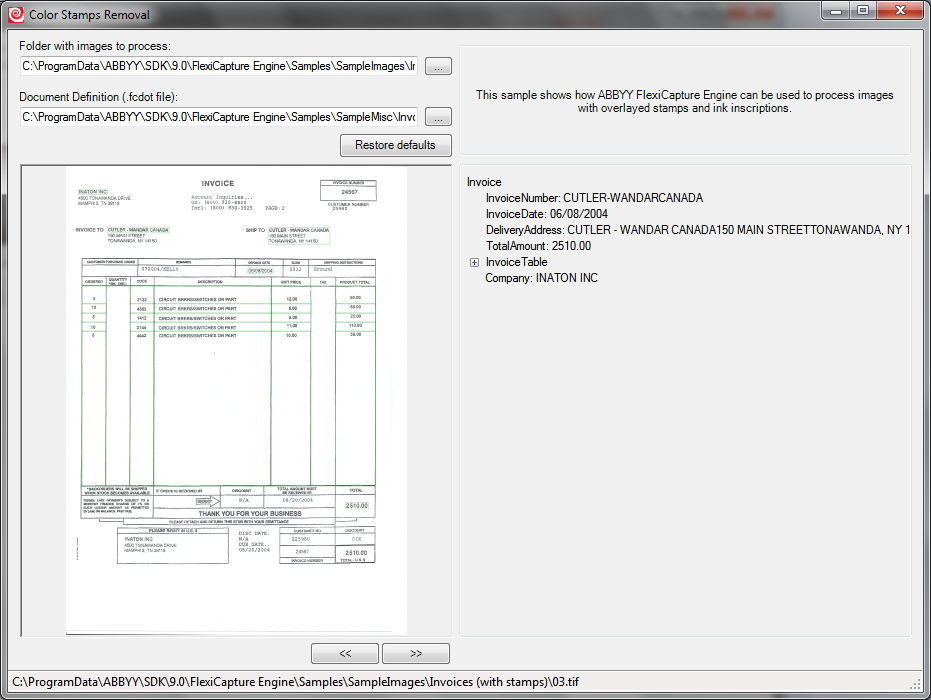
This version contains almost all the improvements that appeared in the ninth version of the product ABBYY FlexiCapture . These are new recognition languages (Chinese, Japanese and Korean), a new multi-level classifier, a technology for removing color seals and stamps from documents to improve the quality of recognition or, on the contrary, to hide individual fields during export.
This is how color stamps are removed from documents. It was:
It became:
This is how the function of hiding individual fields works. It was:
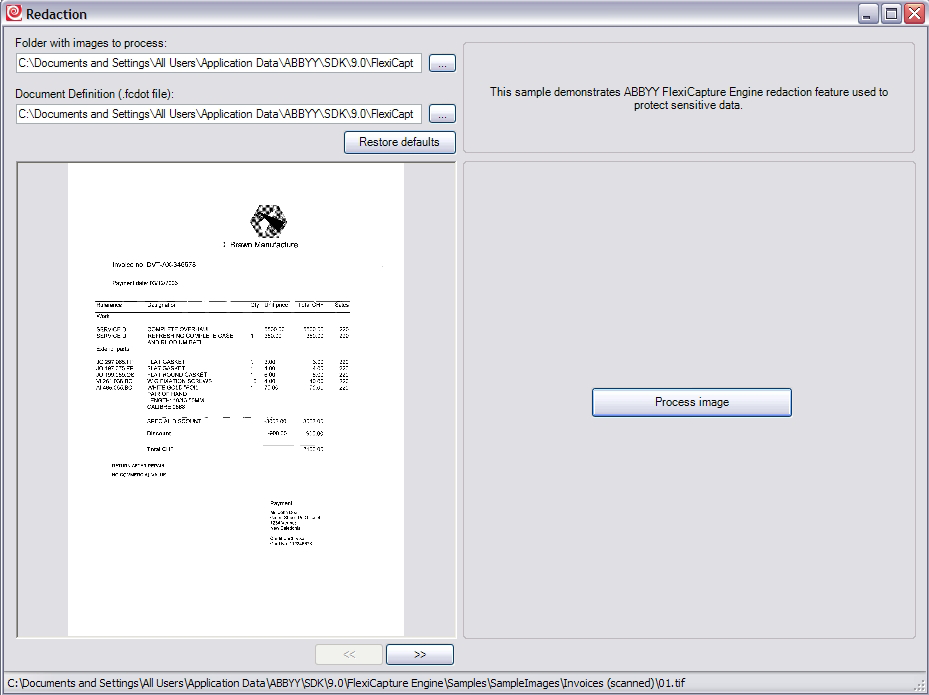
It became:

In addition to improvements in technology, the API has been significantly improved. In the new version, developers can directly control the processing process through the code — upload images, set processing parameters, generate a list of overlaid templates, and upload (export) data.
Source images and processing templates can be stored not only in the file system on a disk, but also in arbitrary storage (database, network storage). In the previous version of the product, when accessing such repositories, it was necessary to create temporary files; moreover, all these files had to be uploaded beforehand even before processing began. The new version has the opportunity to work with files from remote repositories directly, referring to the data as a stream of bytes in memory. This allows you to organize parallel processing and loading of images (download the first image, begin to recognize it, and simultaneously download the remaining images). For many scenarios, this significantly speeds up the work of the program,
For example, a developer can make an application that will process user images stored in Picasa web albums. At the same time, templates for processing these images can be stored centrally, which is convenient for keeping the database of templates up to date.

In addition, ABBYY FlexiCapture Engine 9.0 is specially optimized for use in multi-threading mode, where tasks can be distributed to different cores in multi-core processor systems, and the processing of documents is much faster.
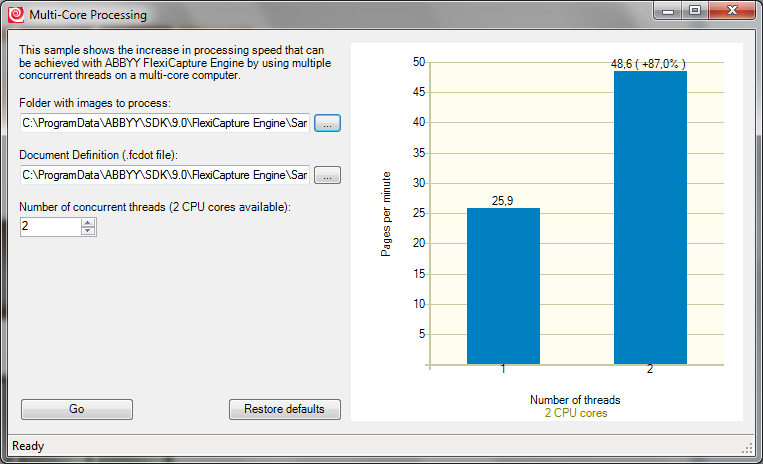
Even in the new version, we updated and expanded the Code Samples Library - a list of FCE scripts with hints on how to write code to implement a particular script and a demonstration of how this script works.

In one of the next releases, another important component will be added - visual components - that is, interface elements that developers can insert into their applications.
At the end we got a universal developer toolkit that includes a whole range of features: a greater number of recognition languages, an easy-to-use API, visual tools for creating templates, a library of code samples, support for various development environments, and, of course, recognition accuracy. Anticipating questions, let's say that the Linux version is already in development.
You can read more about ABBYY FlexiCapture 9.0 for Windows on the ABBYY website .
Maxim Bochkarev
Product Development Department
Source: https://habr.com/ru/post/118089/
All Articles