Apache Hadoop (Report by Vladimir Klimontovich on ADD-2010)
We bring to your attention the report by Vladimir Klimontovich , made by him at the Application Developer Days conference, in which he shared his experience in processing VERY BIG volumes of data, and using NOSQL approaches, in particular, Apache Hadoop .

Below are the text version of the report + video + audio and presentation slides. Thank you belonesox for working on the preparation of the report materials.
')
Background
Examples of use .
Platforms built on top of Hadoop .
Problems with real-time data access when using Apache Hadoop .
Hadoop as a trend .
Video
In case of problems with the display, you can use the link .
Audio
The audio version of the report is available here .
Presentation of the report
Presentation of the report is available here .
So, what are you talking about, what volume are you talking about? For example, the Facebook company, which everyone knows, probably all have profiles there, this social network has 40 terabytes of data per day - photos, posts, comments, again, the log file is simple - page impressions and so on.
What we have next - again, the New York Stock Exchange - one terabyte of transactions per day, data on transactions, purchases and sales of shares, and so on.
Large Hadron Collider : this is about forty terabytes of experimental data per day, information about the speed and position of particles, and so on.
And for example, so that you can imagine what is happening in small companies - ContextWeb is a small American company where I essentially work, which is engaged in online advertising overwriting, a completely small company with a very small percentage of the market, however it is 115 gigabytes of logs display contextual advertising per day. And it’s not just text files, it’s 115 gigabytes of compressed data, i.e. in fact, data is probably much more.
The question arises, what actually to do with them? Because it is necessary to process them somehow. By themselves, such amounts of data are not interesting to anyone and are rather useless.
One way to handle this amount of data was invented by Google. In 2003, Google released a fairly well-known article about distributed file systems, how they store data and indices, user data, and so on.
In 2004, Google again released an article that describes the paradigm of processing such a volume of data called MapReduce.
Actually, this is exactly what I'm going to tell you now about how it works in general, and how it is implemented in the Apache Hadoop platform.
Distributed Filesystem - what is it all about? What tasks are assigned to Distributed Filesystem?
In fact, how it is implemented. There is a small graph here, probably it is not visible, but in general it is visible, yes.
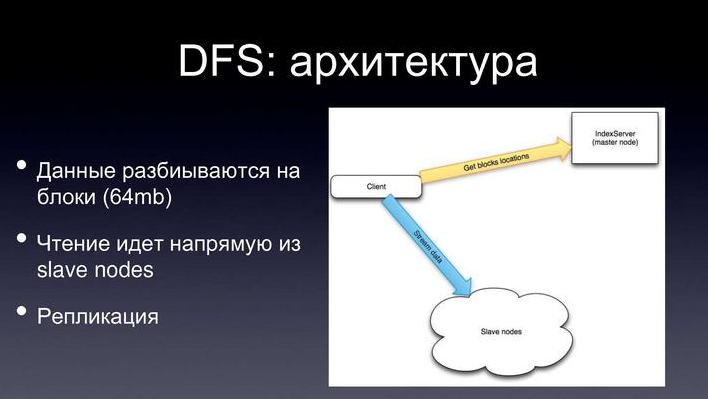
There is a cluster of machines, of which there are many, on which data is stored. There is one machine called master node that coordinates everything.
What is stored on the master node? The master node simply stores a file table. The file system structure, each file is divided into blocks, on which cluster machines, which blocks of files are stored.
How do you write and read? We want to read a file, we ask the master node where the blocks of such a file are stored, it tells us which machine the particular blocks are stored on, and we already read directly from cluster machines.
The same with the record, we ask the master node where we need to write, in which specific blocks, in which particular machines, he tells us, and we write directly there.
And to ensure reliability, each unit is stored in several copies, on several machines. This ensures reliability, even if we lose, say, 10% of the machines in the cluster, most likely, we will not lose anything. Those. Yes, we will lose some blocks, but since these blocks are stored in several copies, we can again read and write
A typical configuration, which, for example, is used in our company. To store large amounts of data, for example, in our company it is 70 terabytes, which we regularly analyze, we are going to do something with them, this is about forty machines, each machine is a weak server, if you look at the industry, this is somewhere 16 gigabytes of RAM or 8 gigabytes, a terabyte disk, no RAID, just a regular disk.
Any Intel Xeon, in general, some cheap server. There are forty such servers too, and this allows you to store such amounts of data, say, hundreds of terabytes.
After all the files are stored on the distributed file system, the question arises how to process them. For this, Google has invented a paradigm called MapReduce. She looks pretty weird. This is data processing, in three operations.
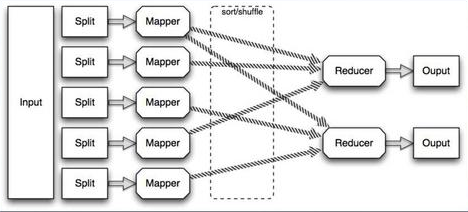
The first operation ..., we have some input data, for example, a set of some input records.
The first operation, which is called Map, which for each input record gives us a pair of "key → value". After that, inside, these “key → value” pairs are grouped; for each key, when we process all the input records there can be several values. Grouped, and issued to the procedure Reduce, which receives the key, and accordingly, a set of values, and gives already, the final final result.
Thus, we already have a set of some input records, for example, these are lines in the log file, and we get some kind of output record records.
All this looks rather strange, like some kind of highly specialized thing, like something from functional programming, it is not immediately clear how this can be applied in general practice.
In fact, it can be applied very well in wide practice.
The simplest example. Suppose we are a Facebook company, we have a lot of data, ... well, just logs show Facebook pages. And we must calculate what browser is used by anyone.
This is done quite easily using the MapReduce paradigm.
We define the Map operation, which, by the line in the access loge, defines the key value, where the key is the browser, and the value is just one.
After that, it remains to do the Reduce operation, which simply does summation over a set of browsers and a multitude of ones, and at the output gives out for each browser the resulting amount.
We run this MapReduce task on a cluster, at the beginning we have many, many log files, at the end we have such a small file, in which we have a browser, and accordingly, the number of hits. This way we will know the statistics.
Why is this good, MapReduce?
Such programs, when we set the Map and set the Reduce, they are very well parallel.
Suppose we have some Input, this is a large file, or file sets, this file can be divided into many, many small pieces, for example, by the number of machines in a cluster, or more. Accordingly, on each piece we will run our Map function, this can be done in parallel, it all runs on the cluster, is calculated in a quiet way, the result of each map is sorted inside, and sent to Reduce.
The same thing, when we have the result of some Map, a lot of some data, we can again break this data into pieces, again run on a cluster, on many machines.
Thanks to this scalability is achieved. When we need to process the data twice as fast, we will simply add twice as many machines, the hardware is now relatively cheap, i.e. without any changes to the architecture, we get twice the performance.
Apache Hadoop - what is it? After Google published these articles, everyone decided that this was a very convenient paradigm, in particular, the Apache Hadoop project was born. They simply decided that what is written in these articles, about distributed file systems and the MapReduce paradigm, be implemented as an open-source Java project.
It started back in 2004, when people wanted to write an open search engine Nutch, then, somewhere in 2005, from it Apache Hadoop stood out as a separate project, as the implementation of the distributed file system and the MapReduce paradigm. At first it was a small project, not very stable, somewhere in 2006, Yahoo began trying to use Hadoop in its projects, and in 2008-2009, Yahoo launched its search, or rather not search, but indexing, which was completely arranged on the Apache Hadoop platform, and now Yahoo is indexing the Internet using the Apache Hadoop platform. The index is stored in the distributed file system, and the index itself is made as a series of Map-Reduce tasks.
Yes, again, Hadoop recently won a data sorting competition, there is such a “1TB sort contest” when some people get together and try to sort one terabyte of data faster. A system based on Apache Hadoop that runs on a Yahoo cluster wins on a regular basis.
Hadoop consists of two modules. This is an implementation of the distributed file system paradigm called HDFS, and MapReduce, i.e. implementation of the MapReduce framework.
Here are some more examples of how, let's say, Yahoo uses Hadoop. Yahoo needs, for example, to build a graph of the entire Internet. As vertices, we will have pages, if from one page there is a link to another, it will be an edge in the graph, and this edge is marked with the text of the link.
For example, as does Yahoo. This is also from the Map-Reduce task series. First, Yahoo downloads all the pages that they are interested in indexing, and stores them, again, in HDFS. To build such a graph, a map-reduce task is run.
So, Map, we just take a page, and look where it refers, and just gives this as a key, Target URL, i.e. where the page, value → SourceURL, i.e. where we link and link text.
Reduce just gets all these pairs, ... i.e. it receives the key, it is the TargetURL and the value set, i.e. the set of SourceURLs and texts does some sort of filtering, for we obviously have some spam links that we don’t want to index, and returns all of this in a table — TargetURL, SourceURL and text.

Such a table is a graph of the entire Internet.
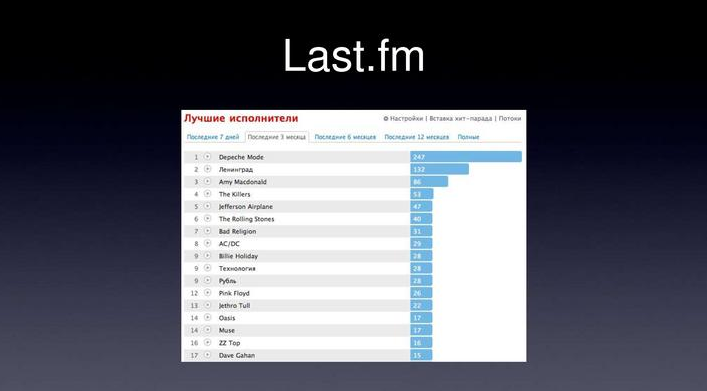
Again, Last.fm, probably many people use it, who don't use it - I'll explain a little. This is such a service, you install a plugin for your iTunes or WinAmp, it sends what you listen to last.fm in real time, then Last.fm does two things - for example, it builds such beautiful charts i.e. for the last seven days or three months, which groups have you listened to, what compositions have you had, and still does some last.fm ??? radio based on the statistics of the songs you listened to, they recommend something different to you, something new and interesting for you, something that supposedly will be interesting to you. If someone noticed, these charts, they are not updated in real-time, once a day, which, I don't remember, in general, is rare.
Actually, these charts, they are built again, on the Apache Hadoop platform. When you listen to a song, a line is simply written to a log file, “a user with such an identifier listened to such and such a composition of such and such a group”. After that, the Map-Reduce task is launched once a day. How she looks like?
After that, when you go to your page, this file is parsed, there is a record relating to you, and this is the chart that was on the last slide.
In fact, a large number of SQL queries easily parallel in the form of ..., can be easily expressed in the form of Map-Reduce tasks. For example, standard SQL, many people write, many use it like this, - a set of fields, f1, f2, sum, where, some condition and group by.
Those. This is a standard SQL query that is used in many places, for building reports and some statistics.
So, such a request is easily parallelized as a map-reduce. Instead of a table, let's say we have a text file, as data storage. Instead of SQL engine, we have map-reduce. Instead of query results, we have a text file.
In fact, how it works.
Map process. As input, we have lines in the log file, as an output, we parse this line and output as a key, fields that interest us as a group by, and value, a field that we aggregate, in this case we count the amount of a.
Reduce gets as a key these fields, as values, a set of fields that we aggregate, i.e. some A1, .... An, and just do the summation.
As a matter of fact, that's all, we defined such map-reduce procedures on a cluster and got the results for this query.
In fact, many SQL queries can be parallelized ..., can be expressed in terms of map-reduce job.
If we have GROUP BY, the fields by which we make GROUP BY are defined as the key in the Map process.
WHERE is just a filtering in the Map process.
Again, we consider all sums, AVG, and other aggregation functions at the Reduce stage.
It is very easy to implement the condition of HAVING, JOIN and so on.
A bit about partitioning. When we process data in this way, let's say, in the same last.fm, we build these statistics, we have data stored in a file, if we run map-reduce work every time on all the files that exist, it will be very long and wrong.
Usually partitioning is used for data, for example, by date. Those. we store everything not in one single log file, but break it by the hour or by day. Then, when we map our SQL query on MapReduce-jobs, we first limit the set of input data to ..., strictly speaking, by files. Suppose if we are interested in the data for the last day, we only take the data for the last day, and only then we start map-reduce-job.
Strictly speaking, this principle is implemented in the Apache Hive project, this is such a framework built on the basis of Hadoop.
How does all this look from the user's point of view? We set some SQL query, define where we have data, after that, this framework expresses this SQL query as map-reduce tasks, in the form of one or a whole sequence, runs them ... everything looks quite transparent to the user.
Those. we defined a set of input data, defined a SQL query, and at the output we also received some kind of table.
The second framework, Apache Pig , is the same, approximately, solves the same problem, i.e. transparent for the user creation of map-reduce job-s, without having to write any code.
We set in such an ETL language, the sequence that we want, where we want to load something from, how we will filter this data, which columns we are interested in, and all of this is translated into map-reduce jobs.

As a matter of fact, the fields of application, all this Hadoop and others.
Hadoop is very well used for building statistical models, and in general for data analysis.
If we have a lot of log files, we want to find some correlations, how the user behaves, depending on what, such tasks are very well solved with the help of Hadoop, respectively, building reports, again, the same Last.fm. When we have a lot of data, and we need to build some reports, we don’t need them real-time, we are ready to update them once a day, or in a few hours, everything is also very convenient.
The advantages of this approach, this platform. Very good and smooth scalability. Those. if we need to process twice as much data, or store twice as much data, we just need to add twice as many machines to the cluster. Those. not exactly exactly twice, but almost twice.
Zero cost software. There you have a lot of data, you can go to Oracle, buy a clustered Oracle for a couple of million dollars, and as many consultants, this is not suitable for all companies, especially startup companies. I do not know, well, any new social network, they just can not afford to spend a few million on Oracle. They can afford Hadoop, take a cluster and use open-source Hadoop as a data analysis and storage system.
Another Hadoop is convenient for research tasks. For example, you are researcher, and you want to investigate the correlation of user behavior with anything on Facebook, anywhere else on your social network, you have a lot of files, hadoop is available, as an on-demand service on Amazon.
Those. you wrote something at yourself, locally debugged, say, OK, now I need a cluster of one hundred machines for two hours, Amazon immediately represents a cluster of one hundred machines, you run your task there, get some results, and everything is would.
A hundred cars for an hour at Amazon are relatively cheap, cheaper than storing a cluster at home. For research, this is quite convenient, in the sense that you need all this once a week, you do not need to keep a cluster, you can order it from Amazon.
From the audience: How much is the order of numbers?
For an hour ... well, that's about a hundred dollars. I honestly do not remember the price of an Amazon, but it is quite cheap, it is quite affordable.
From the audience: Fifty cents per hour ...
Yes, but for Hadoop, we need more instances, and perhaps a bigger cluster, well, yes, in general, hundreds of dollars. This is such an order, it is clear that if a big task, then it’s not an hour, but ten hours, but still, it’s about hundreds of dollars, i.e. about something not very big.
And what are the flaws in Hadoop?
First, it is a rather high cost of support. If you have a Hadoop cluster, from many machines, you need to find a smart system administrator who will understand the Hadoop architecture, how it works, and will support all this. Those. it really is not easy, it really takes a lot of time.
This, unlike any industrial and expensive storage, the cost of new data processing is quite high. Those. if you buy some kind of Oracle, or something similar in this style, it’s enough for you in principle to hire some business analysts who will write just SQL queries and get some results. In this case, this will not work with Hadoop, you will need people who will invent the business part, what kind of data they need, and you will need a team of Java developers who will write these map-reduce jobs.
The team is not very big, but nevertheless, it still costs money, the developers are quite expensive.
And again, the problem with real-time. Hadoop is not a real-time system. If you want to receive any data, you will not be able to run map-reduce jobs when the user visits the site. You need to update the data, at least once an hour, in the background, and the user to show the already calculated data.
With real-tim, the problem is relatively solvable. For example, how this is solved in our company. We do not need to provide real-time access to the entire amount of data that we have, we run map-reduce jobs, get some rather valuable, but reasonable-sized results that we store in the SQL database, in MemCache, in memory, this however, will not work when you have a lot of this data.
So now ... is there any time left?
Ten minutes left, so I will talk about column-oriented databases, also an approach to storing large amounts of data that need realtime access.
How does it work? What are some problems with SQL? In SQL, in MySQL, you cannot store volumes, say, in several terabytes, such a table simply will not work, you cannot receive data from it.
Other problems with SQL, if you change the schema, say, some ALTER TABLE, it is long and problematic to add some columns on a large table. This is quite problematic, and when you don’t need it, when you don’t need to store structured data, when you remove restrictions ... you don’t use SQL capabilities, like structured data storages, you don’t use relationality, you can store data in a slightly more efficient structure, and for that get great performance.
This is just a slightly different approach called the column-oriented database.
It was submitted by Google, and they still use it, if my memory serves me, this is the article “BigTable”, which was published in 2004.
Actually, what is BigTable?
It is built on several principles.
The first principle is that we abandon relationality, indexation by fields, in our table there is exactly one field by which you can perform a search, what is called rowkey, the analog is the primary key in the table.
We do not index all other fields, do not look for them, do not structure them, and the second principle is that the table is wide, i.e. we can add columns at any time, with any type of data, should be cheap and good.
Let me give you an example when it is used. We want to store data about users of our site. I went to the site, did some actions, in the case of Google - made some requests, looked at something, looked at some advertisements, this is an anonymous user ... and we want to remember what he did. How is this problem solved? Many people store information about users in Cookies, what he did, what pages he looked at, what advertisements he looked at, what he clicked on. There is a big problem with this approach - the size of the cookie is very limited, it’s impossible to write there, let's say, the history of the user’s actions for the last month, it doesn’t work, there’s no space. How can this problem be solved with BigTable?
If we have a repository such as BigTable, we can store a single parameter in the cookie — a unique user ID. In BigTable, we will store the UserUID as the main key in the table, and many-many fields that interest us, for example, history of visits, clicks on advertising, clicks on links, and so on.
What is good? The fact that we obviously do not need to look for anything in the other fields. If we want to know some information about the user, in order to show him the appropriate advertising, we need to search only for information on the UserID.
And it’s also good that since business can change, we can add many different fields, and it will be cheap and good. Actually for this it is very good to use BigTable, userID, as rowkey, and all other data, as the table.
How does all this work? , BigTable, . Those. rowkey, rowkey, , , , , rang- . Those. « -»? - , range- , , -, , , .
— → , , , , , , .
BigTable, Apache Hadoop, , HBase .
Hadoop Distributed File System, , Hadoop-, , - map-reduce job, - , , .. Reduce . Reduce , , HBase, , Hadoop, .
, . , , — 16 8 , , 10 RPM, - Intel Xeon, .
, , 3-5 … 300 , - 18 , —— , - 10 . - MySQL . HBase .
HBase, , BigTable ? , .. . , , join-, WHERE, , , , .
, HBase , , , , , , , .
, , map-reduce , research, , , HBase BigTable…, , HBase-, , , , - , , , , , , , .
HBase , , , , . , , .… … ( ).
, — , (. ) .
Below are the text version of the report + video + audio and presentation slides. Thank you belonesox for working on the preparation of the report materials.
')
Background
- Why the problem of processing more data becomes more and more urgent (an example of the growth in the amount of data in different areas).
- An article from Google about the MapReduce paradigm. Brief description of the paradigm.
- Brief description of adjacent areas (distributed file system, bigtable-like storage).
- History and brief description of the Apache Hadoop platform.
Examples of use .
- Using the hadoop platform in three separate areas: last.fm (building charts), online-advertising'e (building statistics), Yahoo (building a search index).
- Description of the traditional approach (SQL database) and the approach using Hadoop for each of the above problems. Pros and cons of the SQL / Hadoop approach
- The general principle of the translation of a certain subtype of SQL queries in MapReduce job.
Platforms built on top of Hadoop .
- Brief description of ETL-framework Hive and Pig, built on the basis of Hadoop.
- Examples of use (for example, facebook.com and Yahoo); comparison with standard SQL approach
Problems with real-time data access when using Apache Hadoop .
- Descriptions of cases when real-time is needed, and when not.
- Description of the solution to simple problems with realtime: in-memory caching (memcached), symbiosis with SQL
- Symbiosis with a bigtable-like database using the HBase example. Brief description of HBase.
Hadoop as a trend .
- A brief overview of the technical and business problems encountered when using Hadoop
- The hype around the Hadoop and NoSQL approach. Describe when SQL is convenient.
Video
In case of problems with the display, you can use the link .
Audio
The audio version of the report is available here .
Presentation of the report
Presentation of the report is available here .
Data volumes
So, what are you talking about, what volume are you talking about? For example, the Facebook company, which everyone knows, probably all have profiles there, this social network has 40 terabytes of data per day - photos, posts, comments, again, the log file is simple - page impressions and so on.
What we have next - again, the New York Stock Exchange - one terabyte of transactions per day, data on transactions, purchases and sales of shares, and so on.
Large Hadron Collider : this is about forty terabytes of experimental data per day, information about the speed and position of particles, and so on.
And for example, so that you can imagine what is happening in small companies - ContextWeb is a small American company where I essentially work, which is engaged in online advertising overwriting, a completely small company with a very small percentage of the market, however it is 115 gigabytes of logs display contextual advertising per day. And it’s not just text files, it’s 115 gigabytes of compressed data, i.e. in fact, data is probably much more.
DFS / MapReduce
The question arises, what actually to do with them? Because it is necessary to process them somehow. By themselves, such amounts of data are not interesting to anyone and are rather useless.
One way to handle this amount of data was invented by Google. In 2003, Google released a fairly well-known article about distributed file systems, how they store data and indices, user data, and so on.
In 2004, Google again released an article that describes the paradigm of processing such a volume of data called MapReduce.
Actually, this is exactly what I'm going to tell you now about how it works in general, and how it is implemented in the Apache Hadoop platform.
Distributed FS
Distributed Filesystem - what is it all about? What tasks are assigned to Distributed Filesystem?
- First, it is storing large amounts of data — files of any size ...
- Secondly, this is just transparency, we want to work with this file system as with a regular file system - we want to open files, write something there, close files, and not think about the fact that this is something distrubuted and big.
- We also want ... another requirement is scalability. We want to store files on a cluster and rather easily scale it. For example, our business has grown twice, it has doubled the amount of data, I want to, without fixed changes in the architecture, store more data twice, simply adding twice as many machines.
- And also reliability. Those. we have a cluster, let's say from a hundred machines, out of operation, let's say five, it’s necessary that it goes unnoticed for us - that the files are accessible, that we can read-write, yes, perhaps with a slightly lower performance, but that everything works until these five cars are noticed.
DFS: architecture
In fact, how it is implemented. There is a small graph here, probably it is not visible, but in general it is visible, yes.
There is a cluster of machines, of which there are many, on which data is stored. There is one machine called master node that coordinates everything.
What is stored on the master node? The master node simply stores a file table. The file system structure, each file is divided into blocks, on which cluster machines, which blocks of files are stored.
How do you write and read? We want to read a file, we ask the master node where the blocks of such a file are stored, it tells us which machine the particular blocks are stored on, and we already read directly from cluster machines.
The same with the record, we ask the master node where we need to write, in which specific blocks, in which particular machines, he tells us, and we write directly there.
And to ensure reliability, each unit is stored in several copies, on several machines. This ensures reliability, even if we lose, say, 10% of the machines in the cluster, most likely, we will not lose anything. Those. Yes, we will lose some blocks, but since these blocks are stored in several copies, we can again read and write
Configuration
A typical configuration, which, for example, is used in our company. To store large amounts of data, for example, in our company it is 70 terabytes, which we regularly analyze, we are going to do something with them, this is about forty machines, each machine is a weak server, if you look at the industry, this is somewhere 16 gigabytes of RAM or 8 gigabytes, a terabyte disk, no RAID, just a regular disk.
Any Intel Xeon, in general, some cheap server. There are forty such servers too, and this allows you to store such amounts of data, say, hundreds of terabytes.
MapReduce
After all the files are stored on the distributed file system, the question arises how to process them. For this, Google has invented a paradigm called MapReduce. She looks pretty weird. This is data processing, in three operations.
The first operation ..., we have some input data, for example, a set of some input records.
The first operation, which is called Map, which for each input record gives us a pair of "key → value". After that, inside, these “key → value” pairs are grouped; for each key, when we process all the input records there can be several values. Grouped, and issued to the procedure Reduce, which receives the key, and accordingly, a set of values, and gives already, the final final result.
Thus, we already have a set of some input records, for example, these are lines in the log file, and we get some kind of output record records.
All this looks rather strange, like some kind of highly specialized thing, like something from functional programming, it is not immediately clear how this can be applied in general practice.
Example
In fact, it can be applied very well in wide practice.
The simplest example. Suppose we are a Facebook company, we have a lot of data, ... well, just logs show Facebook pages. And we must calculate what browser is used by anyone.
This is done quite easily using the MapReduce paradigm.
We define the Map operation, which, by the line in the access loge, defines the key value, where the key is the browser, and the value is just one.
After that, it remains to do the Reduce operation, which simply does summation over a set of browsers and a multitude of ones, and at the output gives out for each browser the resulting amount.
We run this MapReduce task on a cluster, at the beginning we have many, many log files, at the end we have such a small file, in which we have a browser, and accordingly, the number of hits. This way we will know the statistics.
Parallelism
Why is this good, MapReduce?
Such programs, when we set the Map and set the Reduce, they are very well parallel.
Suppose we have some Input, this is a large file, or file sets, this file can be divided into many, many small pieces, for example, by the number of machines in a cluster, or more. Accordingly, on each piece we will run our Map function, this can be done in parallel, it all runs on the cluster, is calculated in a quiet way, the result of each map is sorted inside, and sent to Reduce.
The same thing, when we have the result of some Map, a lot of some data, we can again break this data into pieces, again run on a cluster, on many machines.
Thanks to this scalability is achieved. When we need to process the data twice as fast, we will simply add twice as many machines, the hardware is now relatively cheap, i.e. without any changes to the architecture, we get twice the performance.
Apache hadoop
Apache Hadoop - what is it? After Google published these articles, everyone decided that this was a very convenient paradigm, in particular, the Apache Hadoop project was born. They simply decided that what is written in these articles, about distributed file systems and the MapReduce paradigm, be implemented as an open-source Java project.
It started back in 2004, when people wanted to write an open search engine Nutch, then, somewhere in 2005, from it Apache Hadoop stood out as a separate project, as the implementation of the distributed file system and the MapReduce paradigm. At first it was a small project, not very stable, somewhere in 2006, Yahoo began trying to use Hadoop in its projects, and in 2008-2009, Yahoo launched its search, or rather not search, but indexing, which was completely arranged on the Apache Hadoop platform, and now Yahoo is indexing the Internet using the Apache Hadoop platform. The index is stored in the distributed file system, and the index itself is made as a series of Map-Reduce tasks.
Yes, again, Hadoop recently won a data sorting competition, there is such a “1TB sort contest” when some people get together and try to sort one terabyte of data faster. A system based on Apache Hadoop that runs on a Yahoo cluster wins on a regular basis.
Hadoop Moduli
Hadoop consists of two modules. This is an implementation of the distributed file system paradigm called HDFS, and MapReduce, i.e. implementation of the MapReduce framework.
Yahoo: web graph
Here are some more examples of how, let's say, Yahoo uses Hadoop. Yahoo needs, for example, to build a graph of the entire Internet. As vertices, we will have pages, if from one page there is a link to another, it will be an edge in the graph, and this edge is marked with the text of the link.
For example, as does Yahoo. This is also from the Map-Reduce task series. First, Yahoo downloads all the pages that they are interested in indexing, and stores them, again, in HDFS. To build such a graph, a map-reduce task is run.
So, Map, we just take a page, and look where it refers, and just gives this as a key, Target URL, i.e. where the page, value → SourceURL, i.e. where we link and link text.
Reduce just gets all these pairs, ... i.e. it receives the key, it is the TargetURL and the value set, i.e. the set of SourceURLs and texts does some sort of filtering, for we obviously have some spam links that we don’t want to index, and returns all of this in a table — TargetURL, SourceURL and text.
Such a table is a graph of the entire Internet.
Last.fm
Again, Last.fm, probably many people use it, who don't use it - I'll explain a little. This is such a service, you install a plugin for your iTunes or WinAmp, it sends what you listen to last.fm in real time, then Last.fm does two things - for example, it builds such beautiful charts i.e. for the last seven days or three months, which groups have you listened to, what compositions have you had, and still does some last.fm ??? radio based on the statistics of the songs you listened to, they recommend something different to you, something new and interesting for you, something that supposedly will be interesting to you. If someone noticed, these charts, they are not updated in real-time, once a day, which, I don't remember, in general, is rare.
Actually, these charts, they are built again, on the Apache Hadoop platform. When you listen to a song, a line is simply written to a log file, “a user with such an identifier listened to such and such a composition of such and such a group”. After that, the Map-Reduce task is launched once a day. How she looks like?
- Input is the same log file of these auditions.
- Map looks like - we take a line from this log file, its parsim, and as a key, we give the pair “user and group”, and the value is one.
- Appropriately, then it all falls on Reduce in the form of a “user and group” pair and with a value in the form of a set of units, and is written at the end of the entire file as “user-group and number of auditions”.
After that, when you go to your page, this file is parsed, there is a record relating to you, and this is the chart that was on the last slide.
SQL
In fact, a large number of SQL queries easily parallel in the form of ..., can be easily expressed in the form of Map-Reduce tasks. For example, standard SQL, many people write, many use it like this, - a set of fields, f1, f2, sum, where, some condition and group by.
Those. This is a standard SQL query that is used in many places, for building reports and some statistics.
So, such a request is easily parallelized as a map-reduce. Instead of a table, let's say we have a text file, as data storage. Instead of SQL engine, we have map-reduce. Instead of query results, we have a text file.
In fact, how it works.
Map process. As input, we have lines in the log file, as an output, we parse this line and output as a key, fields that interest us as a group by, and value, a field that we aggregate, in this case we count the amount of a.
Reduce gets as a key these fields, as values, a set of fields that we aggregate, i.e. some A1, .... An, and just do the summation.
As a matter of fact, that's all, we defined such map-reduce procedures on a cluster and got the results for this query.
SQL: Principle
In fact, many SQL queries can be parallelized ..., can be expressed in terms of map-reduce job.
If we have GROUP BY, the fields by which we make GROUP BY are defined as the key in the Map process.
WHERE is just a filtering in the Map process.
Again, we consider all sums, AVG, and other aggregation functions at the Reduce stage.
It is very easy to implement the condition of HAVING, JOIN and so on.
SQL: partitioning
A bit about partitioning. When we process data in this way, let's say, in the same last.fm, we build these statistics, we have data stored in a file, if we run map-reduce work every time on all the files that exist, it will be very long and wrong.
Usually partitioning is used for data, for example, by date. Those. we store everything not in one single log file, but break it by the hour or by day. Then, when we map our SQL query on MapReduce-jobs, we first limit the set of input data to ..., strictly speaking, by files. Suppose if we are interested in the data for the last day, we only take the data for the last day, and only then we start map-reduce-job.
Apache heve
Strictly speaking, this principle is implemented in the Apache Hive project, this is such a framework built on the basis of Hadoop.
How does all this look from the user's point of view? We set some SQL query, define where we have data, after that, this framework expresses this SQL query as map-reduce tasks, in the form of one or a whole sequence, runs them ... everything looks quite transparent to the user.
Those. we defined a set of input data, defined a SQL query, and at the output we also received some kind of table.
Apache pig
The second framework, Apache Pig , is the same, approximately, solves the same problem, i.e. transparent for the user creation of map-reduce job-s, without having to write any code.
We set in such an ETL language, the sequence that we want, where we want to load something from, how we will filter this data, which columns we are interested in, and all of this is translated into map-reduce jobs.
Areas of use
As a matter of fact, the fields of application, all this Hadoop and others.
Hadoop is very well used for building statistical models, and in general for data analysis.
If we have a lot of log files, we want to find some correlations, how the user behaves, depending on what, such tasks are very well solved with the help of Hadoop, respectively, building reports, again, the same Last.fm. When we have a lot of data, and we need to build some reports, we don’t need them real-time, we are ready to update them once a day, or in a few hours, everything is also very convenient.
Virtues
The advantages of this approach, this platform. Very good and smooth scalability. Those. if we need to process twice as much data, or store twice as much data, we just need to add twice as many machines to the cluster. Those. not exactly exactly twice, but almost twice.
Zero cost software. There you have a lot of data, you can go to Oracle, buy a clustered Oracle for a couple of million dollars, and as many consultants, this is not suitable for all companies, especially startup companies. I do not know, well, any new social network, they just can not afford to spend a few million on Oracle. They can afford Hadoop, take a cluster and use open-source Hadoop as a data analysis and storage system.
Another Hadoop is convenient for research tasks. For example, you are researcher, and you want to investigate the correlation of user behavior with anything on Facebook, anywhere else on your social network, you have a lot of files, hadoop is available, as an on-demand service on Amazon.
Those. you wrote something at yourself, locally debugged, say, OK, now I need a cluster of one hundred machines for two hours, Amazon immediately represents a cluster of one hundred machines, you run your task there, get some results, and everything is would.
A hundred cars for an hour at Amazon are relatively cheap, cheaper than storing a cluster at home. For research, this is quite convenient, in the sense that you need all this once a week, you do not need to keep a cluster, you can order it from Amazon.
From the audience: How much is the order of numbers?
For an hour ... well, that's about a hundred dollars. I honestly do not remember the price of an Amazon, but it is quite cheap, it is quite affordable.
From the audience: Fifty cents per hour ...
Yes, but for Hadoop, we need more instances, and perhaps a bigger cluster, well, yes, in general, hundreds of dollars. This is such an order, it is clear that if a big task, then it’s not an hour, but ten hours, but still, it’s about hundreds of dollars, i.e. about something not very big.
disadvantages
And what are the flaws in Hadoop?
First, it is a rather high cost of support. If you have a Hadoop cluster, from many machines, you need to find a smart system administrator who will understand the Hadoop architecture, how it works, and will support all this. Those. it really is not easy, it really takes a lot of time.
This, unlike any industrial and expensive storage, the cost of new data processing is quite high. Those. if you buy some kind of Oracle, or something similar in this style, it’s enough for you in principle to hire some business analysts who will write just SQL queries and get some results. In this case, this will not work with Hadoop, you will need people who will invent the business part, what kind of data they need, and you will need a team of Java developers who will write these map-reduce jobs.
The team is not very big, but nevertheless, it still costs money, the developers are quite expensive.
And again, the problem with real-time. Hadoop is not a real-time system. If you want to receive any data, you will not be able to run map-reduce jobs when the user visits the site. You need to update the data, at least once an hour, in the background, and the user to show the already calculated data.
Real-Time?
With real-tim, the problem is relatively solvable. For example, how this is solved in our company. We do not need to provide real-time access to the entire amount of data that we have, we run map-reduce jobs, get some rather valuable, but reasonable-sized results that we store in the SQL database, in MemCache, in memory, this however, will not work when you have a lot of this data.
So now ... is there any time left?
Ten minutes left, so I will talk about column-oriented databases, also an approach to storing large amounts of data that need realtime access.
Column oriented databases
How does it work? What are some problems with SQL? In SQL, in MySQL, you cannot store volumes, say, in several terabytes, such a table simply will not work, you cannot receive data from it.
Other problems with SQL, if you change the schema, say, some ALTER TABLE, it is long and problematic to add some columns on a large table. This is quite problematic, and when you don’t need it, when you don’t need to store structured data, when you remove restrictions ... you don’t use SQL capabilities, like structured data storages, you don’t use relationality, you can store data in a slightly more efficient structure, and for that get great performance.
This is just a slightly different approach called the column-oriented database.
Bigtable
It was submitted by Google, and they still use it, if my memory serves me, this is the article “BigTable”, which was published in 2004.
Actually, what is BigTable?
It is built on several principles.
The first principle is that we abandon relationality, indexation by fields, in our table there is exactly one field by which you can perform a search, what is called rowkey, the analog is the primary key in the table.
We do not index all other fields, do not look for them, do not structure them, and the second principle is that the table is wide, i.e. we can add columns at any time, with any type of data, should be cheap and good.
BigTable example
Let me give you an example when it is used. We want to store data about users of our site. I went to the site, did some actions, in the case of Google - made some requests, looked at something, looked at some advertisements, this is an anonymous user ... and we want to remember what he did. How is this problem solved? Many people store information about users in Cookies, what he did, what pages he looked at, what advertisements he looked at, what he clicked on. There is a big problem with this approach - the size of the cookie is very limited, it’s impossible to write there, let's say, the history of the user’s actions for the last month, it doesn’t work, there’s no space. How can this problem be solved with BigTable?
If we have a repository such as BigTable, we can store a single parameter in the cookie — a unique user ID. In BigTable, we will store the UserUID as the main key in the table, and many-many fields that interest us, for example, history of visits, clicks on advertising, clicks on links, and so on.
What is good? The fact that we obviously do not need to look for anything in the other fields. If we want to know some information about the user, in order to show him the appropriate advertising, we need to search only for information on the UserID.
And it’s also good that since business can change, we can add many different fields, and it will be cheap and good. Actually for this it is very good to use BigTable, userID, as rowkey, and all other data, as the table.
BigTable: design
How does all this work? , BigTable, . Those. rowkey, rowkey, , , , , rang- . Those. « -»? - , range- , , -, , , .
— → , , , , , , .
HBase
BigTable, Apache Hadoop, , HBase .
Hadoop Distributed File System, , Hadoop-, , - map-reduce job, - , , .. Reduce . Reduce , , HBase, , Hadoop, .
HBase:
, . , , — 16 8 , , 10 RPM, - Intel Xeon, .
, , 3-5 … 300 , - 18 , —— , - 10 . - MySQL . HBase .
HBase:
HBase, , BigTable ? , .. . , , join-, WHERE, , , , .
, HBase , , , , , , , .
Hadoop:
, , map-reduce , research, , , HBase BigTable…, , HBase-, , , , - , , , , , , , .
HBase , , , , . , , .… … ( ).
Questions
, — , (. ) .
Source: https://habr.com/ru/post/117359/
All Articles