[Translation] Now Twitter search is 3 times faster
I have always been interested in Ruby-on-Rails (RoR) and Twitter as a bright representative of the platform on this framework. On April 6 of this year, a blog entry on the Twitter team blog appeared on a complete change of the search platform from RoR to Java. Under the cut translation of how it was.
“In the spring of 2010, the Twitter search team started rewriting our search engine in order to serve the ever-growing traffic, reduce latency for the end user and increase the availability of our service, to gain the ability to quickly develop new search capabilities. As part of the work, we launched a new real-time search engine , changing our back-end from MySQL to the Lucene version. Last week, we launched a replacement for our Ruby-on-Rails front-end: Java server, which we call Blender. We are pleased to announce that this change has reduced the search time by 3 times and will give us the opportunity to consistently increase the search functionality in the following months.
')
Twitter search is one of the world's busiest search engines, serving more than one billion search queries per day. This week, before we deployed Blender, #tsunami in Japan contributed to a significant increase in search queries and associated search delays. After launching Blender, our 95% latency has decreased 3 times, from 800ms to 250ms and the CPU load on our front-end servers has been halved. Now we have the potential to serve 10 times more requests per machine. This means that we can maintain the same number of requests with a smaller number of servers, reducing the cost of our front-end service by an order of magnitude.

95% delay in the search API before and after starting Blender.
To better understand performance gains, you must first understand the flaws of our former Ruby-on-Rails front-end servers. They ran a fixed number of single-threaded workflows, each of which did the following:
We have long known that the synchronous request processing model uses our CPUs inefficiently. For a long time, we also accumulated significant technical debt in our main Ruby code, making it difficult to add functionality and improve the reliability of our search engine. Blender addresses these issues by:
The following diagram shows the architecture of the Twitter search engine. Requests from a website, API, or external clients on Twitter are sent to Blender via a hardware load balancer. Blender parses the search query and sends it to the back-end services using workflows to handle dependencies between services. Finally, the results from the services are combined and formed in the appropriate language of the client.
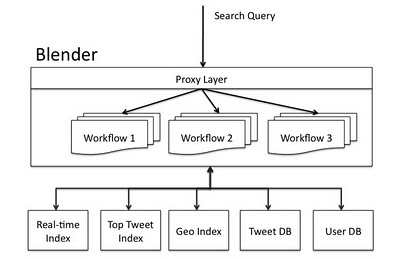
Twitter Search Architecture with Blender.
Blender is a Thrift and HTTP service built on Netty , a widely scalable NIO client-server library written in Java, which allows you to develop for various servers and clients quickly and easily. We chose Netty from several of its competitors, such as Mina and Jetty, because it has a more transparent API, better documentation and, most importantly, because several other Twitter projects use this framework. In order for Netty to work with Thrift, we wrote a simple Thrift codec that decodes Thrift incoming requests from the Netty channel buffer when it is read from a socket and encodes Thrift outgoing responses when it is written to a socket. Netty introduces a key abstraction, called a Channel, to encapsulate a connection to a network socket, which provides an interface for performing a variety of I / O operations, such as read, write, connect, and bind. All channel I / O operations are asynchronous in nature. This means that any I / O call is returned immediately with a ChannelFuture instance that reports when the requested I / O operation is successful, unsuccessful, or canceled. When the Netty server accepts a new connection, it creates a new channel pipeline to handle the connection. A channel pipeline is a sequence of channel handlers that implement the business logic necessary to process a request. In the next section, we show how Blender transports these pipelines for the request processing workflows.
In Blender, a workflow is a set of back-end services with dependencies between them that must be processed to service an incoming request. Blender automatically determines the dependencies between them, for example, if service A depends on service B, A is requested first and its results are transferred to B. This is convenient for representing workflows in the form of directed acyclic graphs (see figure below).
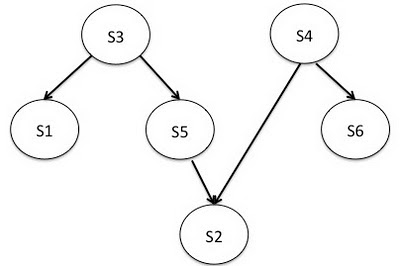
Sample Blender workflow with 6 back-end services.
In the example of the workflow, we have 6 services {s1, s2, s3, s4, s5, s6} with dependencies between them. The straight line from s3 to s1 means that s3 must be called before the call to s1, because s1 needs s3 results. For such a working project, the Blender library performs topological sorting on the DAG to determine the final order of the services, which is also the order in which they are called. The execution order for the workflow above will be {(s3, s4), (s1, s5, s6), (s2)}. This means that s3 and s4 can be called in parallel in the first step; when they return the results, s1, s5, and s6 are also called in parallel in the next step; before the final call s2. After Blender has determined the order of execution, it is displayed on the Netty pipeline. This pipeline is a sequence of handlers that need to send a request for processing.
Since the workflows are mapped to the Netty pipelines in Blender, we needed to send incoming client requests to the appropriate pipeline. For this, we built a proxy layer, which multiplexes and sends client requests according to the following rules:
We used the event-driven Netty model to perform all the listed tasks asynchronously, so there are no more threads waiting for I / O.
As soon as a search request arrives at the workflow pipeline, it passes through a sequence of service handlers in the sequence defined by the workflow. Each service handler creates a corresponding back-end request for this search request and sends it to a remote server. For example, a real-time service handler creates a real-time request and sends it asynchronously to one or more real-time indices. We use the twitter commons library (recently become open source!) To provide connection pool management, load balancing, and dead host definitions. The I / O stream that processes the search request is released when all back-end responses are processed. The timer thread checks every few milliseconds to see if any of the back-end responses are returned from remote servers and sets a flag indicating if the request is successful, timed out, or unsuccessful. We maintain one object throughout the search query life cycle to manage this data type. Successful responses are aggregated and sent to the next step for processing by service handlers in the workflow pipeline. When all responses from the first step arrive, the second step of the asynchronous requests is made. This process is repeated until we complete the workflow or the waiting time does not exceed the allowable one. As you can see, during the execution of the workflow, no thread is idle waiting for I / O. This allows us to efficiently use the CPU on our machines with Blender and handle a large number of concurrent requests. We also save on delays, since we execute most requests for back-end services in parallel.
In order to ensure the high quality of the service while we integrate Blender into our system, we use the old Ruby-on-Rails front-end server as a proxy to redirect thrift requests for our Blender cluster. Using old front-end servers as a proxy allows us to ensure the integrity of user perception, making significant changes in the underlying technology. In the next phase of our deployment, we will completely remove Ruby-on-Rails from our search stack, connecting users directly to Blender and potentially reducing delays even more. ”
“In the spring of 2010, the Twitter search team started rewriting our search engine in order to serve the ever-growing traffic, reduce latency for the end user and increase the availability of our service, to gain the ability to quickly develop new search capabilities. As part of the work, we launched a new real-time search engine , changing our back-end from MySQL to the Lucene version. Last week, we launched a replacement for our Ruby-on-Rails front-end: Java server, which we call Blender. We are pleased to announce that this change has reduced the search time by 3 times and will give us the opportunity to consistently increase the search functionality in the following months.
')
Performance boost
Twitter search is one of the world's busiest search engines, serving more than one billion search queries per day. This week, before we deployed Blender, #tsunami in Japan contributed to a significant increase in search queries and associated search delays. After launching Blender, our 95% latency has decreased 3 times, from 800ms to 250ms and the CPU load on our front-end servers has been halved. Now we have the potential to serve 10 times more requests per machine. This means that we can maintain the same number of requests with a smaller number of servers, reducing the cost of our front-end service by an order of magnitude.
95% delay in the search API before and after starting Blender.
Improved Twitter Search Architecture
To better understand performance gains, you must first understand the flaws of our former Ruby-on-Rails front-end servers. They ran a fixed number of single-threaded workflows, each of which did the following:
- Parsed the search query;
- Synchronously requested search servers;
- Aggregated and shaped the results.
We have long known that the synchronous request processing model uses our CPUs inefficiently. For a long time, we also accumulated significant technical debt in our main Ruby code, making it difficult to add functionality and improve the reliability of our search engine. Blender addresses these issues by:
- Creating a fully asynchronous aggregation service. No threads waiting for network I / O to complete;
- Aggregating results from back-end services, such as real-time service, top tweet service (tweet) and geographic indices service;
- Accurately resolving dependencies between services. Workflows automatically handle transitive dependencies between back-end services.
The following diagram shows the architecture of the Twitter search engine. Requests from a website, API, or external clients on Twitter are sent to Blender via a hardware load balancer. Blender parses the search query and sends it to the back-end services using workflows to handle dependencies between services. Finally, the results from the services are combined and formed in the appropriate language of the client.
Twitter Search Architecture with Blender.
Blender Review
Blender is a Thrift and HTTP service built on Netty , a widely scalable NIO client-server library written in Java, which allows you to develop for various servers and clients quickly and easily. We chose Netty from several of its competitors, such as Mina and Jetty, because it has a more transparent API, better documentation and, most importantly, because several other Twitter projects use this framework. In order for Netty to work with Thrift, we wrote a simple Thrift codec that decodes Thrift incoming requests from the Netty channel buffer when it is read from a socket and encodes Thrift outgoing responses when it is written to a socket. Netty introduces a key abstraction, called a Channel, to encapsulate a connection to a network socket, which provides an interface for performing a variety of I / O operations, such as read, write, connect, and bind. All channel I / O operations are asynchronous in nature. This means that any I / O call is returned immediately with a ChannelFuture instance that reports when the requested I / O operation is successful, unsuccessful, or canceled. When the Netty server accepts a new connection, it creates a new channel pipeline to handle the connection. A channel pipeline is a sequence of channel handlers that implement the business logic necessary to process a request. In the next section, we show how Blender transports these pipelines for the request processing workflows.
Workflow library
In Blender, a workflow is a set of back-end services with dependencies between them that must be processed to service an incoming request. Blender automatically determines the dependencies between them, for example, if service A depends on service B, A is requested first and its results are transferred to B. This is convenient for representing workflows in the form of directed acyclic graphs (see figure below).
Sample Blender workflow with 6 back-end services.
In the example of the workflow, we have 6 services {s1, s2, s3, s4, s5, s6} with dependencies between them. The straight line from s3 to s1 means that s3 must be called before the call to s1, because s1 needs s3 results. For such a working project, the Blender library performs topological sorting on the DAG to determine the final order of the services, which is also the order in which they are called. The execution order for the workflow above will be {(s3, s4), (s1, s5, s6), (s2)}. This means that s3 and s4 can be called in parallel in the first step; when they return the results, s1, s5, and s6 are also called in parallel in the next step; before the final call s2. After Blender has determined the order of execution, it is displayed on the Netty pipeline. This pipeline is a sequence of handlers that need to send a request for processing.
Multiplexing incoming requests
Since the workflows are mapped to the Netty pipelines in Blender, we needed to send incoming client requests to the appropriate pipeline. For this, we built a proxy layer, which multiplexes and sends client requests according to the following rules:
- When a remote Thrift client opens a permanent connection to Blender, the proxy layer creates a map for local clients, one for each of the local servers serving the workflows. Notice that all of these servers are started in the Blender process of the JVM environment and are created when the Blender process starts;
- When a request arrives on a socket, the proxy layer reads it, determines which workflow has been requested and forwards it to the appropriate workflow server;
- Similarly, when a response comes from a local server serving the workflow, the proxy reads it and writes the answer to the remote client.
We used the event-driven Netty model to perform all the listed tasks asynchronously, so there are no more threads waiting for I / O.
Dispatch back-end requests
As soon as a search request arrives at the workflow pipeline, it passes through a sequence of service handlers in the sequence defined by the workflow. Each service handler creates a corresponding back-end request for this search request and sends it to a remote server. For example, a real-time service handler creates a real-time request and sends it asynchronously to one or more real-time indices. We use the twitter commons library (recently become open source!) To provide connection pool management, load balancing, and dead host definitions. The I / O stream that processes the search request is released when all back-end responses are processed. The timer thread checks every few milliseconds to see if any of the back-end responses are returned from remote servers and sets a flag indicating if the request is successful, timed out, or unsuccessful. We maintain one object throughout the search query life cycle to manage this data type. Successful responses are aggregated and sent to the next step for processing by service handlers in the workflow pipeline. When all responses from the first step arrive, the second step of the asynchronous requests is made. This process is repeated until we complete the workflow or the waiting time does not exceed the allowable one. As you can see, during the execution of the workflow, no thread is idle waiting for I / O. This allows us to efficiently use the CPU on our machines with Blender and handle a large number of concurrent requests. We also save on delays, since we execute most requests for back-end services in parallel.
Deploying Blender and Future Work
In order to ensure the high quality of the service while we integrate Blender into our system, we use the old Ruby-on-Rails front-end server as a proxy to redirect thrift requests for our Blender cluster. Using old front-end servers as a proxy allows us to ensure the integrity of user perception, making significant changes in the underlying technology. In the next phase of our deployment, we will completely remove Ruby-on-Rails from our search stack, connecting users directly to Blender and potentially reducing delays even more. ”
Source: https://habr.com/ru/post/117258/
All Articles