High Performance Computing: Problems and Solutions
Computers, even personal, are becoming increasingly difficult. Not so long ago, in the box buzzing on the table, everything was simple - the higher the frequency, the greater the performance. Now the systems have become multi-core, multi-processor, specialized accelerators have appeared in them, computers are increasingly being combined into clusters.
What for? How to understand all this diversity?
What does SIMD, SMP, GPGPU and other scary words mean more and more often?
What are the limits of applicability of existing productivity technologies?
Computer power is growing rapidly and all the time it seems that everything is enough for the existing speed.
But no - growing productivity allows you to solve problems that previously could not be risen. Even at the household level, there are tasks that will load your computer for a long time, for example, home video encoding. In industry and science, such tasks are even greater: huge databases, molecular dynamics calculations, modeling of complex mechanisms — automobiles, jet engines — all of this requires increasing computing power.
In previous years, the main productivity growth was provided fairly simply by reducing the size of microprocessor elements. At the same time, power consumption fell and work frequencies grew, computers became faster and faster, retaining, in general terms, their architecture. The microchip manufacturing process changed and megahertz grew into gigahertz, delighting users with increased productivity, because if “mega” is a million, then “gig” is already a billion operations per second.
But, as you know, paradise is either not forever, or not for everyone, and not so long ago it has ended in the computer world. It turned out that the frequency cannot be increased further - leakage currents grow, processors overheat and it does not work around it. You can, of course, develop cooling systems, use water radiators, or cool with liquid nitrogen — but this is not available to every user, only for supercomputers or technomaniacs. Yes, and with any cooling, the possibility of growth was small, about two times maximum, which was unacceptable for users accustomed to a geometric progression.
It seemed that Moore's law, according to which the number of transistors and the associated computer performance doubled every one and a half to two years, would cease to operate.
It's time to think and experiment, remembering all the possible ways to increase the speed of calculations.
Take the most general performance formula:

')
We see that performance can be measured in the number of executable instructions per second.
Let us write the process in more detail, we introduce a clock frequency there:

The first part of the resulting work is the number of instructions executed per clock (IPC, Instruction Per Clock), the second is the number of processor cycles per unit of time, the clock frequency.
Thus, to increase performance, you must either raise the clock frequency or increase the number of instructions executed per clock cycle.
Because the increase in frequency has stopped, it is necessary to increase the number of instructions executed “at a time”.
How to increase the number of instructions executed per cycle?
Obviously, performing several instructions at a time, in parallel. But how to do that?
It all depends on the program being executed.
If the program is written by the programmer as single-threaded, where all instructions are executed sequentially, one after another, the processor (or compiler) will have to “think for a man” and look for parts of the program that can be executed simultaneously, parallelized.
Take a simple program:
The first two instructions can be carried out in parallel, only the third depends on them. So, the whole program can be completed in two steps, not three.
A processor that is able to determine independent and non-contradictory instructions and execute them in parallel is called a superscalar processor .
Many modern processors, including the latest x86 - superscalar processors, but there is another way: to simplify the processor and to assign the search for parallelism to the compiler. At the same time, the processor executes commands in “bundles” that the compiler has prepared for the program, in each such “bundle” - a set of instructions that are independent of each other and can be executed in parallel. Such an architecture is called VLIW (very long instruction word - “very long machine command”), its further development was called EPIC (explicitly parallel instruction computing) - microprocessor architecture with explicit command parallelism)
The most famous processors with this architecture are Intel Itanium.
There is a third way to increase the number of instructions executed per cycle, this is Hyper Threading Technology. In this technology, the superscalar processor independently parallelizes not commands of one thread, but commands of several (in modern processors — two) parallel launched threads.
Those. physically, the processor core is one, but idle when performing one task, processor power can be used to perform another. The operating system sees one processor (or one processor core) with Hyper Threading as two independent processors. But in fact, of course, Hyper Threading works worse than real two independent processors. tasks on it will compete for computing power among themselves.
Concurrency technologies at the instruction level were actively developed in the 90s and the first half of the 2000s, but at present their potential is almost exhausted. You can rearrange commands, rename registers and use other optimizations, extracting parallel-running sections from sequential code, but dependencies and branches will not allow you to fully parallelize the code. Parallelism at the level of instructions is good because it does not require human intervention - but this is not good: while a person is smarter than a microprocessor, he will have to write a truly parallel code.
We have already mentioned scalarity, but besides a scalar there is a vector, and besides superscalar processors there are vector ones.
Vector processors perform some kind of operation on whole data arrays, vectors. In a “pure” form, vector processors were used in supercomputers for scientific computing in the 1980s.
According to Flynn’s classification , vector processors are SIMD - (single instruction, multiple data - a single command stream, a multiple data stream) .
Currently, x86 processors implement many vector extensions - these are MMX, 3DNow !, SSE, SSE2, etc.
Here is how, for example, multiplication of four pairs of numbers with one command using SSE looks like:
Thus, instead of four consecutive scalar multiplications, we made only one - vector.
Vector processors can significantly speed up computations on large amounts of data, but their scope is limited, typical operations on fixed arrays are far from being applicable everywhere.
However, the race of vectorization of calculations is far from over - so in the latest Intel processors a new vector extension AVX (Advanced Vector Extension) appeared
But much more interesting now look
The theoretical computing power of processors in modern video cards is growing much faster than in conventional processors (see the famous NVIDIA image)

Not so long ago, this power was adapted for universal high-performance computing using CUDA / OpenCL.
The architecture of graphic processors (GPGPU, General Purpose computation on GPU - universal calculations by means of a video card), is close to the already considered SIMD.
It is called SIMT - (single instruction, multiple threads, one instruction - multiple threads) . Just as in SIMD, operations are performed with data arrays, but there are much more degrees of freedom — for each cell of the data being processed, there is a separate command string.
As a result
1) In parallel, hundreds of operations can be performed on hundreds of data cells.
2) In each stream, an arbitrary sequence of commands is executed; it can access different cells.
3) Branching is possible. However, in parallel, only threads with the same sequence of operations can be executed in parallel.
GPGPUs allow you to achieve impressive results on some tasks. but there are fundamental limitations that do not allow this technology to become a universal magic wand, namely
1) It is possible to accelerate on a GPU only by a code that is well parallelized by data.
2) GPU uses its own memory. Transferring data between GPU memory and computer memory is quite expensive.
3) Algorithms with a large number of branches work on the GPU inefficiently
So, we have reached completely parallel architectures - independently parallel, both by commands and by data.
In Flynn's classification, this is MIMD (Multiple Instruction stream, Multiple Data stream - Multiple Command stream, Multiple Data stream).
To use all the power of such systems, multi-threaded programs are needed, their execution can be “scattered” into several microprocessors and thereby achieve an increase in productivity without an increase in frequency. Various technologies of multithreading have long been used in supercomputers, they are now “descended from heaven” to ordinary users, and a multi-core processor is more a rule than an exception. But multi-core is not a panacea.
Parallelism is a good way to get around the limitation of clock speed growth, but it has its own limitations.
First of all, this is the law of Amdal , which states
Acceleration of the program execution due to parallelization of its instructions on the set of calculators is limited by the time required to execute its sequential instructions.
The acceleration of the code depends on the number of processors and the parallelism of the code according to the formula

Indeed, using parallel execution, we can speed up the execution time of only parallel code.
In any program except parallel code, there are also consecutive sections and it will not be possible to speed them up by increasing the number of processors, only one processor will work on them.
For example, if the execution of sequential code takes only 25% of the execution time of the entire program, then it will not be possible to speed up this program more than 4 times.
Let's build a graph of the dependence of the acceleration of our program on the number of parallel computing computers-processors. Substituting in the formula 1/4 of the sequential code and 3/4 of the parallel code, we get
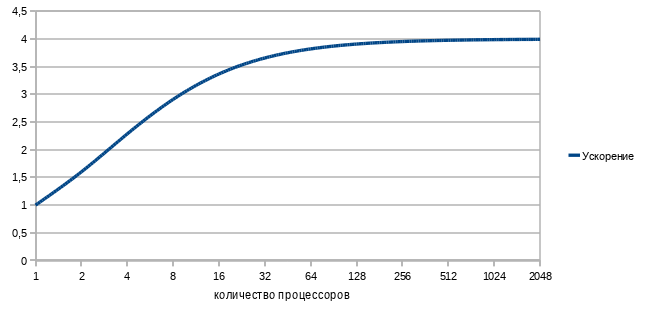
Is it sad And how.
The world's fastest supercomputer with thousands of processors and terabytes of memory on our, it seems, even a good (75%!) Parallel task, less than twice as fast as a regular desktop quad core.
And still worse than in this ideal case. In the real world, the costs of ensuring parallelism are never equal to zero, and therefore when adding more and more new processors, performance will start to fall from a certain point.
But how, then, is the power of modern very, very multi-core supercomputers used?
In many algorithms, the execution time of a parallel code strongly depends on the amount of data processed, and the execution time of a sequential code is not. The more data you need to process, the greater the gain from parallel processing. Therefore, by “driving” large amounts of data to the supercomputer, we get good acceleration.
For example, multiplying 3 * 3 matrices on a supercomputer, we hardly notice the difference with the usual single-processor version, but multiplying matrices with a size of 1000 * 1000 will already be fully justified on a multi-core machine.
There is such a simple example: 9 women in 1 month cannot give birth to one child. Parallelism does not work here. But the same 81 women in 9 months can give birth (take maximum efficiency!) 81 children, that is, we get the maximum theoretical performance from increased parallelism, 9 children per month or, on average, the same one child per month for 9 women .
Big computers - big tasks!
A multiprocessor is a computer system that contains several processors and one that is visible to all processors. address space.
Multiprocessors differ in the organization of work with memory.
In such systems, multiple processors (and processor caches) have access to the same physical RAM. Such a model is often called symmetric multiprocessing (SMP). Access to memory in such a system is called UMA (uniform memory access, uniform access) because Any processor can access any memory location and the speed of this access is independent of the memory address. However, each microprocessor can use its own cache.

Several processor cache subsystems are usually connected to shared memory via the bus.
Let's look at the picture.
What is good with us?
Any processor accesses all memory and it all works the same. Programming for such systems is easier than for any other multiarchitecture. The bad thing is that all processors access memory through the bus, and as the number of processing cores grows, the capacity of this bus quickly becomes a bottleneck.
Adds headaches and the problem of ensuring the coherence of caches.
Suppose we have a multiprocessor computer. Each processor has its own cache, well, as in the figure above. Let several processors read a memory cell, and it got into their caches. It's okay, as long as this cell is unchanged - it is read from fast caches and is somehow used in calculations.
If, as a result of the program, one of the processors changes this memory cell so that there is no mismatch, so that all other processors “see” this update will have to change the contents of the cache of all processors and somehow slow them down for the duration of this update.
It is good if the number of cores / processors is 2, like in a desktop computer, and if 8 or 16? And if they all exchange data through a single bus?
Performance losses can be very significant.
How to reduce the load on the tire?
First of all, you can stop using it to ensure coherence. What is the easiest way to do this?
Yes, yes, use shared cache. This is how most modern multi-core processors work.

Let's look at the picture, find two differences from the previous one.
Yes, the cache is now one for all, respectively, the problem of coherence is not worth it. And the circles turned into rectangles, it symbolizes the fact that all the cores and caches are on the same chip. In reality, the picture is somewhat more complicated, the caches are multilevel, some are common, some are not, a special bus can be used for communication between them, but all true multi-core processors do not use an external bus to ensure cache coherence, which means they reduce the load on it.
Multi-core processors - one of the main ways to improve the performance of modern computers.
Six nuclear processors are already being produced, in the future there will be even more cores ... where are the limits?
First of all, the “nuclearity” of processors is limited by heat generation, the more transistors simultaneously working in one chip, the more this crystal heats, the harder it is to cool it.
And the second big limitation is, again, the throughput of the external bus. Many cores require a lot of data to grind them, the bus speed is no longer enough, you have to give up SMP in favor
NUMA (Non-Uniform Memory Access - “Non-uniform Memory Access” or Non-Uniform Memory Architecture - “Non-Uniform Memory Architecture”) is an architecture in which, with a common address space, the speed of memory access depends on its location . there is “own” memory, access to which is faster and “alien”, access to which is slower.
In modern systems, it looks like this
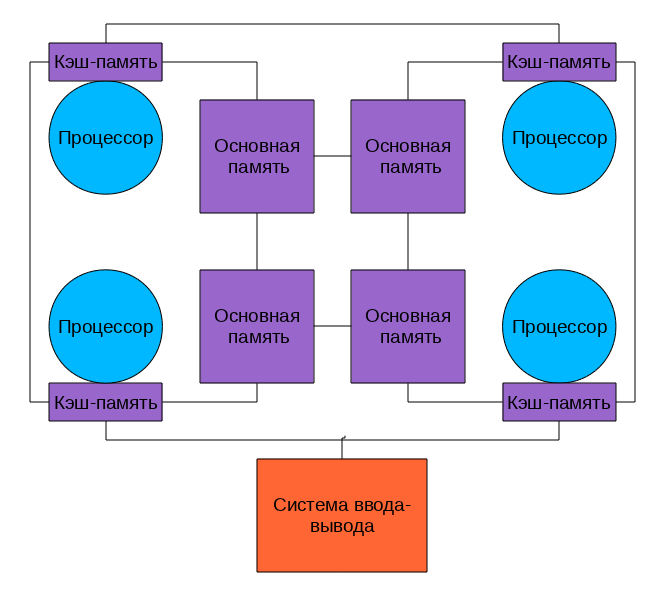
The processors are connected to memory and to each other using a fast bus, in the case of AMD this is Hyper Transport, in the case of the latest Intel processors it is QuickPath Interconnect
Because There is no common for all tires, when working with "its" memory, it ceases to be a bottleneck of the system.
NUMA architecture allows you to create quite productive multiprocessor systems, and given the multi-core modern processors, we’ll get a very serious computing power “in one package”, limited mainly by the complexity of ensuring the cache coherence of this processor and memory confusion.
But if we need more power, we will have to combine several multiprocessors into
A multicomputer is a computer system without shared memory, consisting of a large number of interconnected computers (nodes), each of which has its own memory. When working on a common task, multicomputer nodes interact by sending messages to each other.
Modern multicomputers built from a variety of typical parts are called computational clusters.
Most modern supercomputers are built on a cluster architecture, they combine many computing nodes using a fast network (Gigabit Ethernet or InfiniBand) and allow you to achieve the maximum possible with modern development of science computing power.
The problems limiting their power are also rather big
It:
1) System programming with thousands of computing processors operating in parallel
2) Giant power consumption
3) Difficulty leading to fundamental unreliability
Well, in short, we ran through almost all the technologies and principles of building powerful computing systems.
Now there is an opportunity to imagine the structure of a modern supercomputer.
This is a multicomputer cluster, each node of which is a NUMA or SMP system with several processors, each of the processors with several cores, each core with the possibility of superscalar internal parallelism and vector extensions. On top of all this, GPGPU accelerators are installed in many supercomputers.
All these technologies have advantages and limitations, there are subtleties in the application.
And now try to efficiently download and program all this magnificence!
The task is not trivial ... but very interesting.
What will happen next?
The course "Basics of parallel computing" Internet University supercomputer technology
Flynn's classification on parallels.ru
MultiProcessors, their Memory Organizations and Implementations by Intel & AMD
Multi-core as a way to increase computing system performance
Wikipedia and the Internet
PS The text was born as an attempt to sort out and organize in my head information about technologies in the field of high-performance computing. Inaccuracies and errors are possible, I will be very grateful for comments and comments.
What for? How to understand all this diversity?
What does SIMD, SMP, GPGPU and other scary words mean more and more often?
What are the limits of applicability of existing productivity technologies?
Introduction
Where are the difficulties?
Computer power is growing rapidly and all the time it seems that everything is enough for the existing speed.
But no - growing productivity allows you to solve problems that previously could not be risen. Even at the household level, there are tasks that will load your computer for a long time, for example, home video encoding. In industry and science, such tasks are even greater: huge databases, molecular dynamics calculations, modeling of complex mechanisms — automobiles, jet engines — all of this requires increasing computing power.
In previous years, the main productivity growth was provided fairly simply by reducing the size of microprocessor elements. At the same time, power consumption fell and work frequencies grew, computers became faster and faster, retaining, in general terms, their architecture. The microchip manufacturing process changed and megahertz grew into gigahertz, delighting users with increased productivity, because if “mega” is a million, then “gig” is already a billion operations per second.
But, as you know, paradise is either not forever, or not for everyone, and not so long ago it has ended in the computer world. It turned out that the frequency cannot be increased further - leakage currents grow, processors overheat and it does not work around it. You can, of course, develop cooling systems, use water radiators, or cool with liquid nitrogen — but this is not available to every user, only for supercomputers or technomaniacs. Yes, and with any cooling, the possibility of growth was small, about two times maximum, which was unacceptable for users accustomed to a geometric progression.
It seemed that Moore's law, according to which the number of transistors and the associated computer performance doubled every one and a half to two years, would cease to operate.
It's time to think and experiment, remembering all the possible ways to increase the speed of calculations.
Performance formula
Take the most general performance formula:
')
We see that performance can be measured in the number of executable instructions per second.
Let us write the process in more detail, we introduce a clock frequency there:
The first part of the resulting work is the number of instructions executed per clock (IPC, Instruction Per Clock), the second is the number of processor cycles per unit of time, the clock frequency.
Thus, to increase performance, you must either raise the clock frequency or increase the number of instructions executed per clock cycle.
Because the increase in frequency has stopped, it is necessary to increase the number of instructions executed “at a time”.
Enable parallelism
How to increase the number of instructions executed per cycle?
Obviously, performing several instructions at a time, in parallel. But how to do that?
It all depends on the program being executed.
If the program is written by the programmer as single-threaded, where all instructions are executed sequentially, one after another, the processor (or compiler) will have to “think for a man” and look for parts of the program that can be executed simultaneously, parallelized.
Instruction level parallelism
Take a simple program:
a = 1
b = 2
c = a + b
The first two instructions can be carried out in parallel, only the third depends on them. So, the whole program can be completed in two steps, not three.
A processor that is able to determine independent and non-contradictory instructions and execute them in parallel is called a superscalar processor .
Many modern processors, including the latest x86 - superscalar processors, but there is another way: to simplify the processor and to assign the search for parallelism to the compiler. At the same time, the processor executes commands in “bundles” that the compiler has prepared for the program, in each such “bundle” - a set of instructions that are independent of each other and can be executed in parallel. Such an architecture is called VLIW (very long instruction word - “very long machine command”), its further development was called EPIC (explicitly parallel instruction computing) - microprocessor architecture with explicit command parallelism)
The most famous processors with this architecture are Intel Itanium.
There is a third way to increase the number of instructions executed per cycle, this is Hyper Threading Technology. In this technology, the superscalar processor independently parallelizes not commands of one thread, but commands of several (in modern processors — two) parallel launched threads.
Those. physically, the processor core is one, but idle when performing one task, processor power can be used to perform another. The operating system sees one processor (or one processor core) with Hyper Threading as two independent processors. But in fact, of course, Hyper Threading works worse than real two independent processors. tasks on it will compete for computing power among themselves.
Concurrency technologies at the instruction level were actively developed in the 90s and the first half of the 2000s, but at present their potential is almost exhausted. You can rearrange commands, rename registers and use other optimizations, extracting parallel-running sections from sequential code, but dependencies and branches will not allow you to fully parallelize the code. Parallelism at the level of instructions is good because it does not require human intervention - but this is not good: while a person is smarter than a microprocessor, he will have to write a truly parallel code.
Data Level Concurrency
Vector processors
We have already mentioned scalarity, but besides a scalar there is a vector, and besides superscalar processors there are vector ones.
Vector processors perform some kind of operation on whole data arrays, vectors. In a “pure” form, vector processors were used in supercomputers for scientific computing in the 1980s.
According to Flynn’s classification , vector processors are SIMD - (single instruction, multiple data - a single command stream, a multiple data stream) .
Currently, x86 processors implement many vector extensions - these are MMX, 3DNow !, SSE, SSE2, etc.
Here is how, for example, multiplication of four pairs of numbers with one command using SSE looks like:
float a[4] = { 300.0, 4.0, 4.0, 12.0 };
float b[4] = { 1.5, 2.5, 3.5, 4.5 };
__asm {
movups xmm0, a ; // 4 a xmm0
movups xmm1, b ; // 4 b xmm1
mulps xmm1, xmm0 ; // : xmm1=xmm1*xmm0
movups a, xmm1 ; // xmm1 a
};
Thus, instead of four consecutive scalar multiplications, we made only one - vector.
Vector processors can significantly speed up computations on large amounts of data, but their scope is limited, typical operations on fixed arrays are far from being applicable everywhere.
However, the race of vectorization of calculations is far from over - so in the latest Intel processors a new vector extension AVX (Advanced Vector Extension) appeared
But much more interesting now look
GPUs
The theoretical computing power of processors in modern video cards is growing much faster than in conventional processors (see the famous NVIDIA image)
Not so long ago, this power was adapted for universal high-performance computing using CUDA / OpenCL.
The architecture of graphic processors (GPGPU, General Purpose computation on GPU - universal calculations by means of a video card), is close to the already considered SIMD.
It is called SIMT - (single instruction, multiple threads, one instruction - multiple threads) . Just as in SIMD, operations are performed with data arrays, but there are much more degrees of freedom — for each cell of the data being processed, there is a separate command string.
As a result
1) In parallel, hundreds of operations can be performed on hundreds of data cells.
2) In each stream, an arbitrary sequence of commands is executed; it can access different cells.
3) Branching is possible. However, in parallel, only threads with the same sequence of operations can be executed in parallel.
GPGPUs allow you to achieve impressive results on some tasks. but there are fundamental limitations that do not allow this technology to become a universal magic wand, namely
1) It is possible to accelerate on a GPU only by a code that is well parallelized by data.
2) GPU uses its own memory. Transferring data between GPU memory and computer memory is quite expensive.
3) Algorithms with a large number of branches work on the GPU inefficiently
Multiarchitecture-
So, we have reached completely parallel architectures - independently parallel, both by commands and by data.
In Flynn's classification, this is MIMD (Multiple Instruction stream, Multiple Data stream - Multiple Command stream, Multiple Data stream).
To use all the power of such systems, multi-threaded programs are needed, their execution can be “scattered” into several microprocessors and thereby achieve an increase in productivity without an increase in frequency. Various technologies of multithreading have long been used in supercomputers, they are now “descended from heaven” to ordinary users, and a multi-core processor is more a rule than an exception. But multi-core is not a panacea.
Severe law, but it is the law
Parallelism is a good way to get around the limitation of clock speed growth, but it has its own limitations.
First of all, this is the law of Amdal , which states
Acceleration of the program execution due to parallelization of its instructions on the set of calculators is limited by the time required to execute its sequential instructions.
The acceleration of the code depends on the number of processors and the parallelism of the code according to the formula
Indeed, using parallel execution, we can speed up the execution time of only parallel code.
In any program except parallel code, there are also consecutive sections and it will not be possible to speed them up by increasing the number of processors, only one processor will work on them.
For example, if the execution of sequential code takes only 25% of the execution time of the entire program, then it will not be possible to speed up this program more than 4 times.
Let's build a graph of the dependence of the acceleration of our program on the number of parallel computing computers-processors. Substituting in the formula 1/4 of the sequential code and 3/4 of the parallel code, we get
Is it sad And how.
The world's fastest supercomputer with thousands of processors and terabytes of memory on our, it seems, even a good (75%!) Parallel task, less than twice as fast as a regular desktop quad core.
And still worse than in this ideal case. In the real world, the costs of ensuring parallelism are never equal to zero, and therefore when adding more and more new processors, performance will start to fall from a certain point.
But how, then, is the power of modern very, very multi-core supercomputers used?
In many algorithms, the execution time of a parallel code strongly depends on the amount of data processed, and the execution time of a sequential code is not. The more data you need to process, the greater the gain from parallel processing. Therefore, by “driving” large amounts of data to the supercomputer, we get good acceleration.
For example, multiplying 3 * 3 matrices on a supercomputer, we hardly notice the difference with the usual single-processor version, but multiplying matrices with a size of 1000 * 1000 will already be fully justified on a multi-core machine.
There is such a simple example: 9 women in 1 month cannot give birth to one child. Parallelism does not work here. But the same 81 women in 9 months can give birth (take maximum efficiency!) 81 children, that is, we get the maximum theoretical performance from increased parallelism, 9 children per month or, on average, the same one child per month for 9 women .
Big computers - big tasks!
Multiprocessor
A multiprocessor is a computer system that contains several processors and one that is visible to all processors. address space.
Multiprocessors differ in the organization of work with memory.
Shared memory systems
In such systems, multiple processors (and processor caches) have access to the same physical RAM. Such a model is often called symmetric multiprocessing (SMP). Access to memory in such a system is called UMA (uniform memory access, uniform access) because Any processor can access any memory location and the speed of this access is independent of the memory address. However, each microprocessor can use its own cache.
Several processor cache subsystems are usually connected to shared memory via the bus.
Let's look at the picture.
What is good with us?
Any processor accesses all memory and it all works the same. Programming for such systems is easier than for any other multiarchitecture. The bad thing is that all processors access memory through the bus, and as the number of processing cores grows, the capacity of this bus quickly becomes a bottleneck.
Adds headaches and the problem of ensuring the coherence of caches.
Cache coherence
Suppose we have a multiprocessor computer. Each processor has its own cache, well, as in the figure above. Let several processors read a memory cell, and it got into their caches. It's okay, as long as this cell is unchanged - it is read from fast caches and is somehow used in calculations.
If, as a result of the program, one of the processors changes this memory cell so that there is no mismatch, so that all other processors “see” this update will have to change the contents of the cache of all processors and somehow slow them down for the duration of this update.
It is good if the number of cores / processors is 2, like in a desktop computer, and if 8 or 16? And if they all exchange data through a single bus?
Performance losses can be very significant.
Multi-core processors
How to reduce the load on the tire?
First of all, you can stop using it to ensure coherence. What is the easiest way to do this?
Yes, yes, use shared cache. This is how most modern multi-core processors work.
Let's look at the picture, find two differences from the previous one.
Yes, the cache is now one for all, respectively, the problem of coherence is not worth it. And the circles turned into rectangles, it symbolizes the fact that all the cores and caches are on the same chip. In reality, the picture is somewhat more complicated, the caches are multilevel, some are common, some are not, a special bus can be used for communication between them, but all true multi-core processors do not use an external bus to ensure cache coherence, which means they reduce the load on it.
Multi-core processors - one of the main ways to improve the performance of modern computers.
Six nuclear processors are already being produced, in the future there will be even more cores ... where are the limits?
First of all, the “nuclearity” of processors is limited by heat generation, the more transistors simultaneously working in one chip, the more this crystal heats, the harder it is to cool it.
And the second big limitation is, again, the throughput of the external bus. Many cores require a lot of data to grind them, the bus speed is no longer enough, you have to give up SMP in favor
NUMA
NUMA (Non-Uniform Memory Access - “Non-uniform Memory Access” or Non-Uniform Memory Architecture - “Non-Uniform Memory Architecture”) is an architecture in which, with a common address space, the speed of memory access depends on its location . there is “own” memory, access to which is faster and “alien”, access to which is slower.
In modern systems, it looks like this
The processors are connected to memory and to each other using a fast bus, in the case of AMD this is Hyper Transport, in the case of the latest Intel processors it is QuickPath Interconnect
Because There is no common for all tires, when working with "its" memory, it ceases to be a bottleneck of the system.
NUMA architecture allows you to create quite productive multiprocessor systems, and given the multi-core modern processors, we’ll get a very serious computing power “in one package”, limited mainly by the complexity of ensuring the cache coherence of this processor and memory confusion.
But if we need more power, we will have to combine several multiprocessors into
Multicomputer
A multicomputer is a computer system without shared memory, consisting of a large number of interconnected computers (nodes), each of which has its own memory. When working on a common task, multicomputer nodes interact by sending messages to each other.
Modern multicomputers built from a variety of typical parts are called computational clusters.
Most modern supercomputers are built on a cluster architecture, they combine many computing nodes using a fast network (Gigabit Ethernet or InfiniBand) and allow you to achieve the maximum possible with modern development of science computing power.
The problems limiting their power are also rather big
It:
1) System programming with thousands of computing processors operating in parallel
2) Giant power consumption
3) Difficulty leading to fundamental unreliability
Putting it all together
Well, in short, we ran through almost all the technologies and principles of building powerful computing systems.
Now there is an opportunity to imagine the structure of a modern supercomputer.
This is a multicomputer cluster, each node of which is a NUMA or SMP system with several processors, each of the processors with several cores, each core with the possibility of superscalar internal parallelism and vector extensions. On top of all this, GPGPU accelerators are installed in many supercomputers.
All these technologies have advantages and limitations, there are subtleties in the application.
And now try to efficiently download and program all this magnificence!
The task is not trivial ... but very interesting.
What will happen next?
Information sources
The course "Basics of parallel computing" Internet University supercomputer technology
Flynn's classification on parallels.ru
MultiProcessors, their Memory Organizations and Implementations by Intel & AMD
Multi-core as a way to increase computing system performance
Wikipedia and the Internet
PS The text was born as an attempt to sort out and organize in my head information about technologies in the field of high-performance computing. Inaccuracies and errors are possible, I will be very grateful for comments and comments.
Source: https://habr.com/ru/post/117021/
All Articles