FlexClone - Dolly's Digital Sheep

Sheep Dolly from the title is a come to name of the first successful clone of a high-level living creature created by science. And although clones are still experimental in biology, the topic of clones has settled firmly and extensively in IT and in the field of data storage.
The ability to quickly (and last but not least - economically, in terms of space and time) create a complete copy of one or another extensive data is a task in great demand today. Such a clone of data could be used for testing, development, and other experiments where it is undesirable or directly impossible to do this on "combat data."
A practical example of where and how clones can be applied.
Suppose our company uses a large database in which our entire business is concentrated, for example, the base of an ERP system. Of course, business lives and grows, along with the growth of our company, the development team writes new functionality for the base, designs new jobs, writes some new business logic in the database. And all this they need to test and check on the data. Moreover, the more voluminous and real data they will have - the more effective and more accurate their testing will be.
Ideally, they need to be tested on real data, on the real base of your company. However, who in their right mind would allow them to test something on a “combat” base?
Now, if you could create an exact copy of the database, in its current state, especially for testing!
')
But to create a complete, independent clone, we need a storage capacity of at least equal to the capacity of the main base. Moreover, the speed of such a base should ideally be equal to “combat”, that is, it will not work to copy them onto a “bunch of USB disks”. I'm not talking about the fact that under the terms of implementation, for example, an ERP system like SAP, in a deployed infrastructure, there must necessarily be development units and QA (Quality Assurance, validation and testing), and often a base for trainings and training of new users, and each must have its own copy of the current database on which the development and control of applications, as well as staff training.
It is precisely these requirements that often lead to the fact that enterprises implementing ERP automatically get two or three additional to the main storage system, or twice or three times more disks in it, spending not only on their acquisition, but also on operation, maintenance, administration, and so on. But it is also important to maintain the relevance of copies, and therefore regularly roll changes to copies, keeping them relevant to the main copy of the state.
And nothing can be done here. Keep a few identical copies of the base is necessary.
Or is it still possible?
And this is where the clones begin to play.
Clones are full copies of data, working as full copies, that is, not just “reading”, but just like a regular copy. The contents of such a clone can not only be read, but also modified, that is, fully written into it, indistinguishable, for the application, from working with a regular data section.
Make a clone in three ways. First, simply copy the data to free space, and keep it up-to-date manually. This is obvious and not interesting. It is rather a copy, not a clone. This option takes up a huge amount of expensive storage space and a lot of time for its creation.
The second option is the so-called Copy-on-Write (COW) copy. In them, records that, say, the application under test wants to add to its “copy” cause the source data to be copied to a special reserved space, and both the original data set and its changes will be saved. The problems here are the same as those of COW snapshots, it almost triples the productivity of such a storage. And this is also not interesting.
And the third option implemented NetApp.
As you already know, the underlying structure of the storage of data blocks, called WAFL , for all NetApp storage systems is designed in such a way that changes to the blocks in it are made not into actually changing blocks, but into the free space of the volume where the current state data pointers are then swapped.
Such a scheme makes it easy and elegant to solve the problem with variable blocks in the clone. A clone always remains the same virtual “copy” of data (which means we can not occupy space on the disk, but simply refer to the original data blocks from it), and all the changes to the blocks that we make over the clone instances are accumulated separately.
Consequently, such clones occupy disk space only in the amount of changes made to the clones.
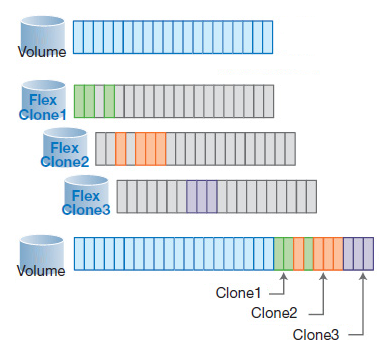
If your programmers in the development department have changed in their virtual copies of the clones of the base, 6TB in size, a couple of terabytes of data, then their clone will occupy exactly 2TB from the free space on the disk, and that’s all.

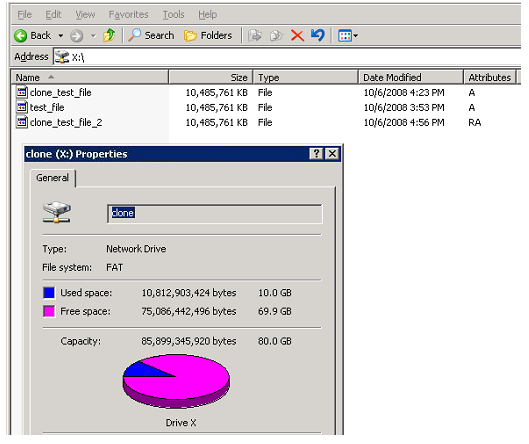
In the screenshot you can see how such a clone looks like in practice. There are three files on the disk, each, from the point of view of the Explorer size of 10GB, but the space occupied by all three on the disk is only 10GB.
It is also useful that such clones can easily “tear off” from the original volume, and, if necessary, turn into a physical copy.
Did the developers check the base upgrade process for the new version, or test the patches? Upgraded, checked all the software to work correctly with the new version, made sure that everything works on the updated database - and easily replaced the working volume with the updated and tested "clone", with all the changes made in this clone, which now becomes quite a full volume.
By the way, there can be up to 255 such clones on each volume (not on the system as a whole - on each volume!), And you can not limit yourself to the number of clones. If your developers have several options and they would like to choose one of them - just give them a clone for each option, let them experiment and choose by comparing all the desired options at once.
As you can see, having such a simple and effective data cloning mechanism often changes the very approach to using them. What was not done before, “because it is impossible,” as an example — the same practical debugging on real data, or parallel development on bulk multi-gigabyte and terabyte data, is now completely realizable with such clones.
In the picture in the title of the article - two
Source: https://habr.com/ru/post/116853/
All Articles