Simple OCR for .NET
It all started with the need for one of the applications to take a snapshot of an arbitrary window and 3-4 times per second to recognize several image areas with previously known characters. It was not a problem to make a screenshot of the window using WinAPI, but I had to work a little on recognition.
Naturally to start, I looked for ready-made solutions. The first thing that issued Google is the Tesseract library, or rather its wrapper for .NET - called Tessnet2. Unfortunately, a detailed study turned out that it does not suit me. The second version of Tesseract has quite a lot of memory leaks, which did not suit me, because after 10 minutes of the program using Tessnet2, the application crashed with OutOfMemoryException. On the Tesseract page it is written that there should be no leaks in the third version, but I did not find a working wrapper for Tesseract3 either.
Also, the MODI (Microsoft Office Document Imaging) tool did not suit me - because it recognizes only files (you cannot pass it an instance of the Bitmap class for recognition).
')
After a brief search in Google for other free character recognition libraries under .NET and problems associated with them, I decided that it would be easier to make my small library just for such cases. Moreover, the task is quite interesting.
What we have:
What did I want to get in the end? Get a class, to which method you can transfer an image, a special file with a set of recognizable characters, and get a recognized string at the output. Like that:
I also thought it would be nice to have utilities for creating such font files and for checking the created font on a specific image. Utilities are for convenience only. All actions that can be done using utilities can be done in code.
All functionality is distributed between the three classes OCRSymbol, OCRFont and OCRReader.
OCRSymbol - describes the symbol: its name, width and height, shift of the symbol down relative to the highest symbol in the entire set, lists of points characteristic for the symbol and points making up the background.
OCRFont - character set, serialized using BinaryFormater.
OCRReader - coordinates the reading of characters one by one. Also sets the reading strategy. The fact is that when creating an instance of this class, we can set the color. This color will be used either as the background color (all that is not this color, then the symbol), or as the color of the symbol (all that not this color is the background). This is necessary for cases when the background uses more than one color, or when the symbol is drawn in more than one color.
The case when the symbol is drawn in more than one color (black background, everything else is a symbol)

The case when the background is not monochromatic (the background is a green gradient, the characters are painted in white)

The recognition algorithm is very simple. Each symbol is described by two universal lists List. The first - the points that must be present in the symbol (Good), the second - which should not, that is, the background (Bad). When comparing with the next symbol, the list of background points is first traversed if, when checking the next point, the corresponding point in the recognizable image is not the background (the background color is set when creating the OCRReader), the cycle ends and proceed to comparison with the next symbol. If the list of background points is successfully passed, then we similarly run through the list of symbol points. Any mismatch - go to the comparison with the next symbol. If all the checks were successful, then we recognized our symbol and can proceed to the recognition of the next one.
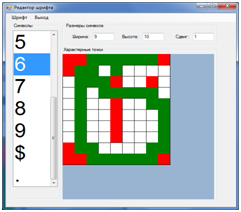
I didn’t want to manually describe the lists of points for each character, so I wrote a utility that automatically imports all image files from a specified directory and creates the lists by file name and specified background color. Of course in most cases a manual adjustment would be desirable. Since all the pixels of the image are scattered around the lists of background points and character points. In most cases, this accuracy is not necessary. It is enough to specify 10-20 points from each list to uniquely identify the symbol. For example, for my example, the following lists of pixels were enough for the character '6' (red - background, green - character, white - not checked). The first screenshot - the symbol is described by the utility, the second - after manual editing. They are recognized equally. It was possible to make even less characteristic points.

A utility was also created to test the operation of the font file created using the previous utility.
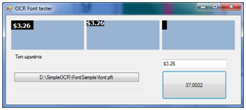
Recognition of 5 characters, taking into account cropping (cropping the image to the character boundaries), took 37 ms. For the full alphabet, the recognition time will be self-longer.
A library with recognizer classes, a utility for creating and editing font files and checking on an image, examples of font images, as well as the source of all this for Visual Studio 2010 can be downloaded from mediafire.com .
Or from GitHub.com
The AForge .NET library is used to crop the edges of the image, since the Bitmap.Clone method works very slowly. I would be glad if my workings will be useful to someone other than me.
Tessnet2 and MODI
Naturally to start, I looked for ready-made solutions. The first thing that issued Google is the Tesseract library, or rather its wrapper for .NET - called Tessnet2. Unfortunately, a detailed study turned out that it does not suit me. The second version of Tesseract has quite a lot of memory leaks, which did not suit me, because after 10 minutes of the program using Tessnet2, the application crashed with OutOfMemoryException. On the Tesseract page it is written that there should be no leaks in the third version, but I did not find a working wrapper for Tesseract3 either.
Also, the MODI (Microsoft Office Document Imaging) tool did not suit me - because it recognizes only files (you cannot pass it an instance of the Bitmap class for recognition).
')
After a brief search in Google for other free character recognition libraries under .NET and problems associated with them, I decided that it would be easier to make my small library just for such cases. Moreover, the task is quite interesting.
What we have:
- Symbols are not distorted. That is, to recognize the captcha will not work
- The set of recognizable characters is constant and for each character we have a file with its image.
- A small number of characters for recognition. The more characters - the longer it recognizes
Idea
What did I want to get in the end? Get a class, to which method you can transfer an image, a special file with a set of recognizable characters, and get a recognized string at the output. Like that:
var playerStacks = new OCRReader(OCRFont.Load("MyFont.pft")), Color.Black, useForeColor: false);
var stackString = playerStacks.Recognize(imageToRecognition);I also thought it would be nice to have utilities for creating such font files and for checking the created font on a specific image. Utilities are for convenience only. All actions that can be done using utilities can be done in code.
Implementation
All functionality is distributed between the three classes OCRSymbol, OCRFont and OCRReader.
OCRSymbol - describes the symbol: its name, width and height, shift of the symbol down relative to the highest symbol in the entire set, lists of points characteristic for the symbol and points making up the background.
OCRFont - character set, serialized using BinaryFormater.
OCRReader - coordinates the reading of characters one by one. Also sets the reading strategy. The fact is that when creating an instance of this class, we can set the color. This color will be used either as the background color (all that is not this color, then the symbol), or as the color of the symbol (all that not this color is the background). This is necessary for cases when the background uses more than one color, or when the symbol is drawn in more than one color.
The case when the symbol is drawn in more than one color (black background, everything else is a symbol)
The case when the background is not monochromatic (the background is a green gradient, the characters are painted in white)
The recognition algorithm is very simple. Each symbol is described by two universal lists List. The first - the points that must be present in the symbol (Good), the second - which should not, that is, the background (Bad). When comparing with the next symbol, the list of background points is first traversed if, when checking the next point, the corresponding point in the recognizable image is not the background (the background color is set when creating the OCRReader), the cycle ends and proceed to comparison with the next symbol. If the list of background points is successfully passed, then we similarly run through the list of symbol points. Any mismatch - go to the comparison with the next symbol. If all the checks were successful, then we recognized our symbol and can proceed to the recognition of the next one.
Additional utilities
I didn’t want to manually describe the lists of points for each character, so I wrote a utility that automatically imports all image files from a specified directory and creates the lists by file name and specified background color. Of course in most cases a manual adjustment would be desirable. Since all the pixels of the image are scattered around the lists of background points and character points. In most cases, this accuracy is not necessary. It is enough to specify 10-20 points from each list to uniquely identify the symbol. For example, for my example, the following lists of pixels were enough for the character '6' (red - background, green - character, white - not checked). The first screenshot - the symbol is described by the utility, the second - after manual editing. They are recognized equally. It was possible to make even less characteristic points.
A utility was also created to test the operation of the font file created using the previous utility.
Recognition of 5 characters, taking into account cropping (cropping the image to the character boundaries), took 37 ms. For the full alphabet, the recognition time will be self-longer.
Sources
A library with recognizer classes, a utility for creating and editing font files and checking on an image, examples of font images, as well as the source of all this for Visual Studio 2010 can be downloaded from mediafire.com .
Or from GitHub.com
Conclusion
The AForge .NET library is used to crop the edges of the image, since the Bitmap.Clone method works very slowly. I would be glad if my workings will be useful to someone other than me.
Used materials
Source: https://habr.com/ru/post/116602/
All Articles