We are writing the viewer of the MS Exchange mail database (part 2)

Hello, readers Habrahabr!
This is the completion of the post started here .
In principle, we have already done almost everything; a small ending is left. Let me remind you, we took the EDB database, opened it using the ESE technology, listed the available tables and started listing the columns inside these tables. It remains for us to get the columns, get the values of the columns and voila, the base is read.
In the previous post, I did not add a function responsible for moving to the next column in the table, as well as a description of the SColumnInfo structure, here they are:
typedef struct tagColumnInfo
{
DWORD dwId ;
std :: wstring sName ;
DWORD dwType ;
DWORD dwMaxSize ;
} SColumnInfo ;
bool CJetDBReaderCore :: TableEnd ( std :: wstring sTableName )
{
std :: map < std :: wstring , JET_TABLEID > :: const_iterator iter = m_tables. find ( sTableName ) ;
if ( iter ! = m_tables. end ( ) )
{
if ( _JetMove ( m_sesid, iter - > second, JET_MoveNext, 0 ) )
{
return true ;
}
else return false ;
}
')
return true ;
}
Accordingly, when the transition to the next element fails, this is a sign that the table has ended .
We received a list of columns and brought them into our structures, it remains to get the values.
Get cell values in columns
We write the following function:
JET_ERR CJetDBReaderCore :: EnumColumnsValues (
SDBTableInfo & sTableInfo,
std :: list < SColumnInfo > & sColumnsInfo )
{
typedef std :: basic_string < byte > CByteArray ;
JET_ERR jRes = OpenTable ( sTableInfo. STableName ) ;
if ( jRes == JET_errSuccess )
{
JET_COLUMNLIST sColumnInfo ;
jRes = GetTableColumnInfo ( sTableInfo. sTableName , & sColumnInfo, FALSE ) ;
if ( jRes ! = JET_errSuccess ) return jRes ;
if ( ! MoveToFirst ( sTableInfo. sTableName ) )
{
std :: vector < CByteArray > Holders ( sColumnsInfo. size ( ) ) ;
std :: vector < CByteArray > :: iterator HolderIt = Holders. begin ( ) ;
std :: vector < JET_RETRIEVECOLUMN > Row ( sTableInfo. sColumnInfo . size ( ) ) ;
std :: vector < JET_RETRIEVECOLUMN > :: iterator It = Row. begin ( ) ;
std :: list < SColumnInfo > :: const_iterator ColumnInfoIt
= sColumnsInfo. begin ( ) ;
for ( int nColNum = 0 ; ColumnInfoIt ! = sColumnsInfo. end ( ) ;
++ ColumnInfoIt, ++ It, ++ HolderIt, ++ nColNum )
{
DWORD dwMaxSize = ColumnInfoIt - > dwMaxSize ? ColumnInfoIt - > dwMaxSize :
MAX_BUFFER_SIZE ;
It - > columnid = ColumnInfoIt - > dwId ;
It - > cbData = dwMaxSize ;
HolderIt - > assign ( dwMaxSize, ' \ 0 ' ) ;
It - > pvData = const_cast < byte * > ( HolderIt - > data ( ) ) ;
It - > itagSequence = 1 ;
}
do
{
GetColumns (
sTableInfo. sTableName , & Row [ 0 ] ,
static_cast < int > ( Row. size ( ) ) ) ;
ColumnInfoIt = sColumnsInfo. begin ( ) ;
int iSubItem = 0 ;
for ( It = Row. begin ( ) ; It ! = Row. end ( ) ; ++ It,
++ ColumnInfoIt, ++ iSubItem )
{
if ( ( * It ) . cbActual )
{
std :: wstring s ;
std :: string tmp ;
wchar_t buff [ 16 ] ;
switch ( ColumnInfoIt - > dwType )
{
case JET_coltypBit :
s = * reinterpret_cast < byte * > ( ( * It ) . pvData ) ? L "True" : L "False" ;
break ;
case JET_coltypText :
tmp. assign ( reinterpret_cast < char * > ( ( * It ) . pvData ) , ( * It ) . cbActual ) ;
s. assign ( tmp. begin ( ) , tmp. end ( ) ) ;
break ;
case JET_coltypLongText :
s. assign ( reinterpret_cast < wchar_t * > ( ( * It ) . pvData ) ,
( * It ) . cbActual / sizeof ( wchar_t ) ) ;
break ;
case JET_coltypUnsignedByte :
s = _ltow ( * static_cast < byte * > ( ( * It ) . pvData ) , buff, 10 ) ;
break ;
case JET_coltypShort :
s = _ltow ( * static_cast < short * > ( ( * It ) . pvData ) , buff, 10 ) ;
break ;
case JET_coltypLong :
s = _ltow ( * static_cast < * > ( ( * It ) . pvData ) , buff, 10 ) ;
break ;
case JET_coltypGUID :
wchar_t wszGuid [ 64 ] ;
:: StringFromGUID2 ( * reinterpret_cast < const GUID * > ( ( * It ) . PvData ) ,
wszGuid, sizeof ( wszGuid ) ) ;
USES_CONVERSION ;
s = wszGuid ;
break ;
}
sTableInfo. sColumnInfo [ iSubItem ] . sColumnValues . push_back ( s ) ;
}
else sTableInfo. sColumnInfo [ iSubItem ] . sColumnValues . push_back ( L "<empty>" ) ;
}
}
while ( ! TableEnd ( sTableInfo. sTableName ) ) ;
}
jRes = CloseTable ( sTableInfo. sTableName ) ;
}
return jRes ;
}
We will go through all the lines and subtract the value of the cells for each. And let's start with the fact that we move to the first element by setting the cursor to the appropriate position (function MoveToFirst, see the previous post ).
Everything is very similar to how we enumerated table names from MSysObjects, with one exception: then we knew that the data is of string type, and here the data can be arbitrary. Therefore, we will create special Holders byte containers where we will save future information, and since this is a normal vector, we don’t have to think about cleaning the memory, it will be destroyed when we get out of sight of this function.
Those.:
- For brevity, we declare:
typedef std :: basic_string < byte > CByteArray
- Create Holder'y for the data, and they will get information from the database:
std :: vector < CByteArray > Holders ( sColumnsInfo. size ( ) ) ;
- And then in the cycle we link the pieces of memory where the data and our holders will be returned, and for this we first allocate enough memory for them to hold all the information (we received the maximum data size when listing the columns):
HolderIt - > assign ( dwMaxSize, ' \ 0 ' ) ;
It - > pvData = const_cast < byte * > ( HolderIt - > data ( ) ) ; - And now in the cycle we will return the information for each column to our JET_RETRIEVECOLUMN vector, which uses the memory allocated for holders:
GetColumns ( sTableInfo. STableName , & Row [ 0 ] , static_cast < INT > ( Row. Size ( ) ) ) ;
As a result, we subtract one line from the table. But since Data is an array of bytes, it needs to be converted to something more readable, so we will try to parse the cells depending on their types. In this example, the following types are understood (as the most obvious):
- JET_coltypBit
- JET_coltypText
- JET_coltypLongText
- JET_coltypUnsignedByte
- JET_coltypShort
- JET_coltypLong
- JET_coltypGUID
Description available in ESE types can be found here .
Conclusion
So we wrote a viewer mail base! If you start digging through these endless tables, you can find a lot of interesting things, for example, what has changed a lot in Exchange 2010 compared to all previous versions and much, much more.
The fact that we wrote there is a significant drawback: visibility. We filled out a bunch of structures that didn’t display. Those. you need to write a GUI program, which in a visual form shows the contents of all these structures. Write it should be easy, because It will be a collection of simple grids, the benefit of the structure we have already prepared and completed, that is, roughly speaking, it remains only to print. I will give a couple of examples of such tables below.
What did it give us practically? On the one hand, not much, because Most of the information is in binary form JET_coltypBinary and you will not find a description of this format anywhere. Here, Exchange can’t do without reverse engineering . But on the other hand, we can better understand “How does it really work?”, And this can be invaluable information. Plus, it is useful material for the "start" if you have to do something similar in the future.
Where can it come in handy? This can be useful only in cases when another API does not work or does not satisfy some requirements, for example, a performance requirement. Examples of such tasks can be: antivirus, audit, migration and recovery systems.
Finally, two small examples of the data.
A piece of the list of tables in the database:
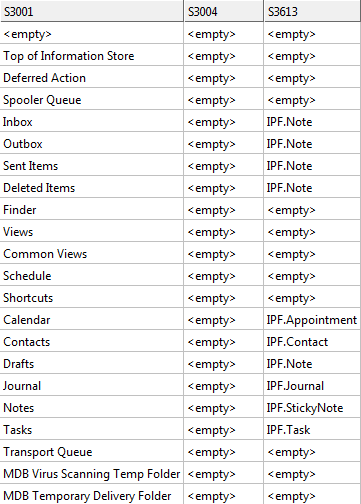
List of folders and their types:
Thank you for reading and taking your time!
PS This code is an adapted and reduced version for the post. Therefore, there are some flaws in the code, or rather gags in the field of reduced functionality. Please do not pay attention to them this is not production, but I wanted to show working examples. The code is fully working and written so that it can be placed on the Internet and at the same time not “eat” all the space on the page. Thank you for understanding.
PPS I understand that in view of the specificity of this information is unlikely to be useful for a wide range of people, but if it helps, even to one person, I will be glad, and the time spent on this post will pay off.
Related Links
- Extensible Storage Engine on MSDN
- Article in Russian (almost the only article in the Russian Internet about the use of ESE API)
- Examples of using ESE features
Source: https://habr.com/ru/post/116511/
All Articles