Details about the breakthrough AI in Kinect
Microsoft Research has published a scientific paper and video showing how the Kinect body tracking algorithm works - almost as amazingly as some of the applications it has already found.
Kinect's breakthrough provides several components. Its iron is well thought out and performs its functions at a reasonable price. However, after the astonishment of the fast-measuring iron depth passes, attention inevitably attracts the way in which it (Kinect) tracks the human body. In this case, the hero is a rather classical pattern recognition technique, but implemented with grace.
Devices that monitor body position, have already been before; but their big problem is the need for the user to get into the reference pose, in which the algorithm identifies him with a simple mapping. After that, the tracking algorithm following the body movements is used. The basic idea: if we have an area identified as a hand in the first frame, then this hand cannot move very far in the next frame, which means we are just trying to identify nearby areas.
Tracking algorithms are good in theory, but in practice they fail if the body position is lost for some reason; and they do very badly with other objects blocking the tracked person, even for a short time. In addition, tracking several people is difficult; and with such a “loss of track” it can be restored after quite a long time, if at all.
')
So, what did the guys from Microsoft Research do with this problem that Kinect works much better?
They returned to the original principles and decided to build a body recognition system that does not depend on tracking, but finds parts of the body based on the local analysis of each pixel. Traditional pattern recognition works by using a decision-making structure trained on a variety of samples. In order for it to work, you usually provide a classifier with a large number of characteristic values, which you think contain the information necessary to recognize the object. In many cases, the task of choosing informative features is the most difficult task.
The signs that were chosen may surprise, as they are simple and far from obvious in the sense of information content for identifying parts of the body. All attributes are obtained from a simple formula.
f = d (x + u / d (x)) - d (x + v / d (x))
where u, v is a pair of displacement vectors, and d (x) is the pixel depth, that is, the distance from Kinect to the point projected on x . This is a very simple sign, in fact it is just a difference in the depth of two pixels offset from the source by u and v. (By varying u and v, we obtain a set of features. In the work itself (link below), everything is much clearer. - Comments of transl.)
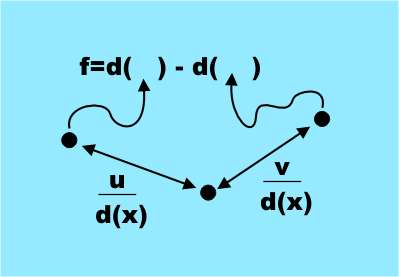
The only complication is that the offset is normalized by the depth of the original pixel, that is, divided by d (x). This makes the displacements independent of depth and relates to the apparent size of the body.
It is clear that these signs measure something related to the three-dimensional shape of the area around a pixel; but are they enough to distinguish, say, a leg from the arm — that is another question.
The next step performed by the team is to train a variety of a classifier called a “decision forest”, that is, a set of decision trees. Each tree was trained on a set of features in deep images that were previously tied to the corresponding parts of the body. That is, the trees were rebuilt until they began to produce the correct classification for a particular part of the body on a test set of images. Learning only three trees per 1 million images on a 1000-core cluster took about a day.
Trained classifiers give the probability that a pixel belongs to a particular part of the body; and the next stage of the algorithm simply selects the regions with the highest probability for parts of each type. For example, a region will be categorized as 'leg', if the "foot" classifier gave the maximum probability in that region. The final stage is the calculation of the estimated location of the joints relative to the areas identified as defined parts of the body. In this diagram, probability maxima for different parts of the body are indicated by colored areas:
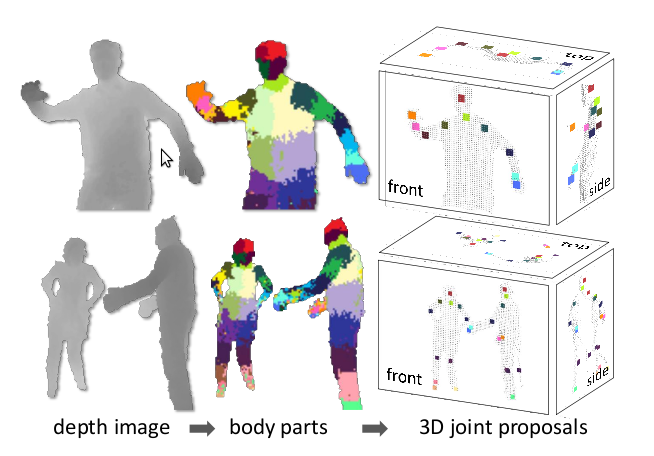
Note that it is quite simple to calculate all this, having a depth value of at least three pixels and here you can use the GPU. Therefore, the system can process 200 frames per second and does not require an initial reference posture. Since each frame is analyzed independently, and there is no tracking as such, there is no problem with the loss of the body image; and you can process several bodies simultaneously.
Now that you understand how it all works, watch the video from Microsoft Research:
(alternative source )
Kinect is a significant achievement and it is based on a fairly standard, classical pattern recognition, but correctly applied. You also need to take into account the availability of a large multi-core computing power, which allowed us to make the training set large enough. This is one of the features of recognition techniques that one can spend centuries on learning, but then the classification itself can be performed very quickly. Perhaps we are entering a “golden age” when the computational power necessary for good pattern recognition and machine learning work will finally make them practical.
Actually publication (Pdf, 4.6 Mb)
PS
1. This is a translation. Since Habr's comprehensive wisdom does not provide for such trifles as changing the type of topic when it was first published in the sandbox, it is not properly designed.
Original by Harry Fairhead from I Programmer.
2. Since Habr's all-encompassing wisdom also does not tolerate haste, I already decided that the topic did not pass the moderation and published it elsewhere. So if anyone saw him there, do not tell anyone. But know that it was intended for Habr. :)
Kinect's breakthrough provides several components. Its iron is well thought out and performs its functions at a reasonable price. However, after the astonishment of the fast-measuring iron depth passes, attention inevitably attracts the way in which it (Kinect) tracks the human body. In this case, the hero is a rather classical pattern recognition technique, but implemented with grace.
Devices that monitor body position, have already been before; but their big problem is the need for the user to get into the reference pose, in which the algorithm identifies him with a simple mapping. After that, the tracking algorithm following the body movements is used. The basic idea: if we have an area identified as a hand in the first frame, then this hand cannot move very far in the next frame, which means we are just trying to identify nearby areas.
Tracking algorithms are good in theory, but in practice they fail if the body position is lost for some reason; and they do very badly with other objects blocking the tracked person, even for a short time. In addition, tracking several people is difficult; and with such a “loss of track” it can be restored after quite a long time, if at all.
')
So, what did the guys from Microsoft Research do with this problem that Kinect works much better?
They returned to the original principles and decided to build a body recognition system that does not depend on tracking, but finds parts of the body based on the local analysis of each pixel. Traditional pattern recognition works by using a decision-making structure trained on a variety of samples. In order for it to work, you usually provide a classifier with a large number of characteristic values, which you think contain the information necessary to recognize the object. In many cases, the task of choosing informative features is the most difficult task.
The signs that were chosen may surprise, as they are simple and far from obvious in the sense of information content for identifying parts of the body. All attributes are obtained from a simple formula.
f = d (x + u / d (x)) - d (x + v / d (x))
where u, v is a pair of displacement vectors, and d (x) is the pixel depth, that is, the distance from Kinect to the point projected on x . This is a very simple sign, in fact it is just a difference in the depth of two pixels offset from the source by u and v. (By varying u and v, we obtain a set of features. In the work itself (link below), everything is much clearer. - Comments of transl.)
The only complication is that the offset is normalized by the depth of the original pixel, that is, divided by d (x). This makes the displacements independent of depth and relates to the apparent size of the body.
It is clear that these signs measure something related to the three-dimensional shape of the area around a pixel; but are they enough to distinguish, say, a leg from the arm — that is another question.
The next step performed by the team is to train a variety of a classifier called a “decision forest”, that is, a set of decision trees. Each tree was trained on a set of features in deep images that were previously tied to the corresponding parts of the body. That is, the trees were rebuilt until they began to produce the correct classification for a particular part of the body on a test set of images. Learning only three trees per 1 million images on a 1000-core cluster took about a day.
Trained classifiers give the probability that a pixel belongs to a particular part of the body; and the next stage of the algorithm simply selects the regions with the highest probability for parts of each type. For example, a region will be categorized as 'leg', if the "foot" classifier gave the maximum probability in that region. The final stage is the calculation of the estimated location of the joints relative to the areas identified as defined parts of the body. In this diagram, probability maxima for different parts of the body are indicated by colored areas:
Note that it is quite simple to calculate all this, having a depth value of at least three pixels and here you can use the GPU. Therefore, the system can process 200 frames per second and does not require an initial reference posture. Since each frame is analyzed independently, and there is no tracking as such, there is no problem with the loss of the body image; and you can process several bodies simultaneously.
Now that you understand how it all works, watch the video from Microsoft Research:
(alternative source )
Kinect is a significant achievement and it is based on a fairly standard, classical pattern recognition, but correctly applied. You also need to take into account the availability of a large multi-core computing power, which allowed us to make the training set large enough. This is one of the features of recognition techniques that one can spend centuries on learning, but then the classification itself can be performed very quickly. Perhaps we are entering a “golden age” when the computational power necessary for good pattern recognition and machine learning work will finally make them practical.
Actually publication (Pdf, 4.6 Mb)
PS
1. This is a translation. Since Habr's comprehensive wisdom does not provide for such trifles as changing the type of topic when it was first published in the sandbox, it is not properly designed.
Original by Harry Fairhead from I Programmer.
2. Since Habr's all-encompassing wisdom also does not tolerate haste, I already decided that the topic did not pass the moderation and published it elsewhere. So if anyone saw him there, do not tell anyone. But know that it was intended for Habr. :)
Source: https://habr.com/ru/post/116393/
All Articles