Recognition of some modern captcha
That was the name of the work presented by me at the Baltic Science and Engineering Competition, which brought me a charming piece of paper with a Roman edinichka, as well as a brand new laptop.
The job was to recognize the CAPTCHA used by large mobile operators in the form of sending SMS, and to demonstrate the lack of effectiveness of their approach. In order not to hurt anyone's pride, we will call these operators allegorically: red, yellow, green and blue.
')
The project received the official name Captchure and unofficial Breaking Defective Security Measures . Any matches are random.
Oddly enough, all (well, almost all) of these CAPTCHAs turned out to be rather weak. The lowest result - 20% - belongs to the yellow operator, the greatest - 86% - to the blue. Thus, I believe that the task of “demonstrating inefficiency” was successfully solved.
The reasons for choosing cellular operators are trivial. To the respected Scientific Jury, I told the bike that “cellular operators have enough money to hire a programmer of any qualification, and, at the same time, they need to minimize the amount of spam; thus, their CAPTCHA must be quite powerful, which, as my research shows, is completely different. ” In fact, everything was much simpler. I wanted to gain experience byhacking by recognizing some simple CAPTCHA, and I chose the red operator as the victim of the CAPTCHA. And after that, the aforementioned story was born in hindsight.
So, closer to the body. I don’t have any mega-advanced algorithm for recognizing all four types of CAPTCHA; instead, I wrote 4 different algorithms for each type of CAPTCHA separately. However, despite the fact that the algorithms are different in details, in general, they turned out to be very similar.
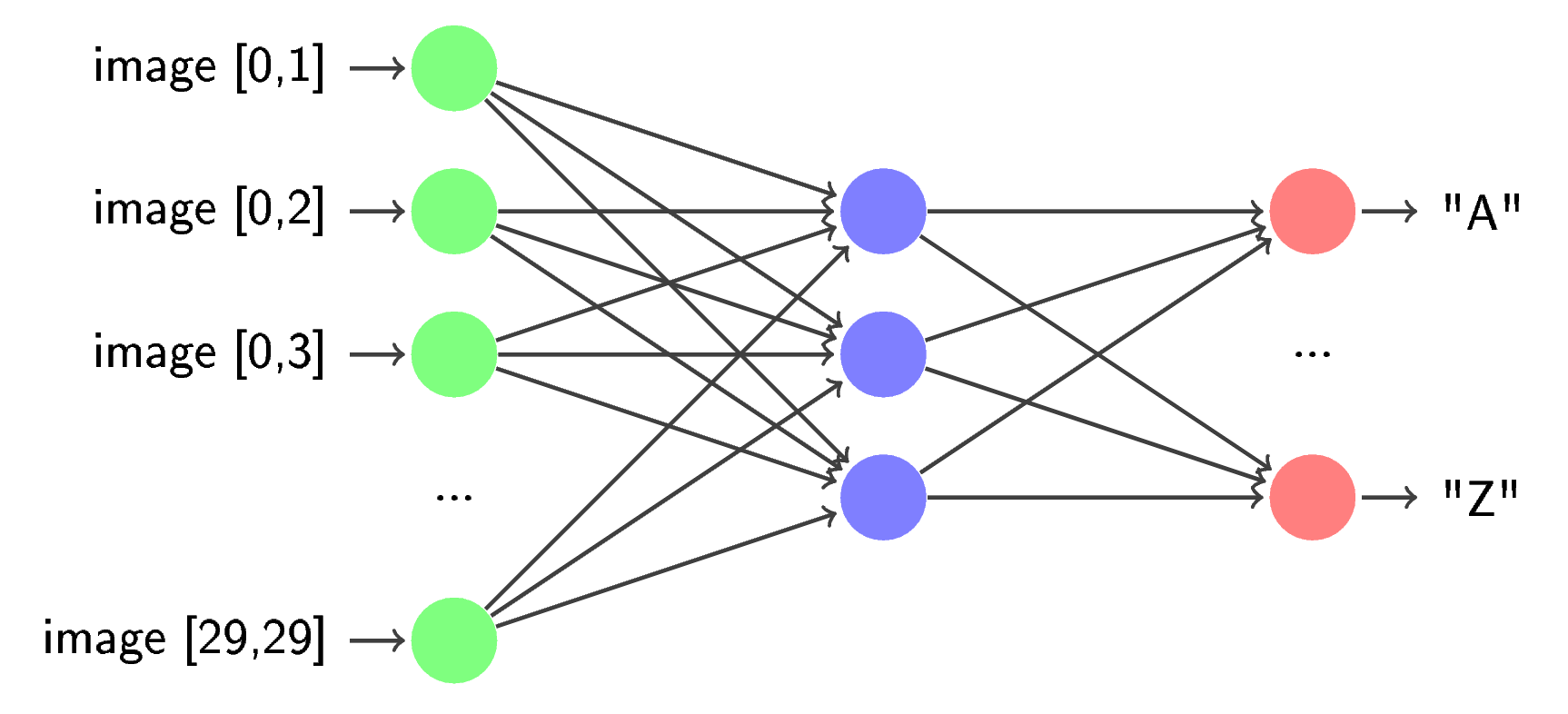
Like many authors before me, I split the CAPTCHA recognition task into 3 subtasks: preprocessing (preprocess), segmentation, and recognition. At the preprocess stage, various noises, distortions, etc. are removed from the original image. In the segmentation, separate characters are extracted from the original image and produced from post-processing (for example, reverse rotation). In recognition, the characters are processed one by one by the previously trained neural network.
Only the preprocess was significantly different. This is due to the fact that different methods of image distortion are used in different CAPTCHA, respectively, and the algorithms for removing these distortions are very different. Segmentation exploited the key idea of finding connectivity components with minor frills (they had to be significant only for yellow-striped ). The recognition was exactly the same for three operators out of four - again, only the yellow operator was different.
The code is written in Python using the OpenCV and FANN libraries, which are not installed without a decent-sized file and a tambourine into the bargain. Therefore, my results will not be easy to reproduce - at least until the authors of the above libraries make normal Python bindings.
As I said, I chose this particular CAPTCHA as the first rabbit. I think a few examples will clarify the situation:


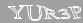
That's it, and at first I also thought that it was very simple ... However, this impression did not come from scratch. So:
It all seemed to negate the merits of this CAPTCHA:
Naturally, these "advantages" are such only from the point of view of the complexity of automatic recognition. In accordance with the three-stage scheme, mentioned by me earlier, we start with the preliminary image processing, namely, a 2-fold increase.


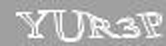
As I already mentioned, the distortions are constant here, and, even though they are not linear, it is not difficult to get rid of them. The parameters were chosen empirically.




Next, I apply a threshold conversion (popularly Threshold) with t = 200 and invert the image:

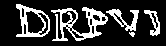

Finally, small (less than 10px) black connected regions are painted over with white:



This is followed by segmentation. As I said, the search for connected components is applied here:



Sometimes (rarely, but sometimes) a letter breaks into several parts; To correct this annoying misunderstanding, I use a fairly simple heuristic that evaluates the belonging of several connected components to a single symbol. This estimate depends only on the horizontal position and size of the descriptive rectangles (bounding boxes) of each character.

It is easy to see that many characters were combined into one component of connectivity, and therefore it is necessary to separate them. Here comes the fact that the image is always exactly 5 characters. This allows you to accurately calculate how many characters are in each component found.
To explain the principle of operation of such an algorithm, you will have to delve a little into the materiel. Denote the number of segments found by n, and the array of widths ( correctly said, yes? ) Of all segments by widths [n]. We assume that if after the above steps n> 5, the image could not be recognized. Consider all possible expansions of the number 5 into positive integer terms. There are only a few of them - only 16. Each such decomposition corresponds to some possible arrangement of symbols for the connected components found. It is logical to assume that the wider the resulting segment, the more characters it contains. Of all the expansions of the five, we choose only those in which the number of terms is equal to n. We divide each element from widths by widths [0] - as if we normalize them. We do the same with all the remaining expansions - we divide each number in them into the first term. And now (attention, climax!), We note that the resulting ordered n-ki can be thought of as points in n-dimensional space. With this in mind, we find the closest to Euclid decomposition of the five to normalized widths. This is the desired result.
By the way, in connection with this algorithm, another interesting way came to my mind to search for all decompositions of a number into terms, which I, however, did not implement, having dug in Python data structures. In short - it comes out pretty obviously, if you notice that the number of expansions of a certain length coincides with the corresponding level of Pascal's triangle. However, I am sure that this algorithm has long been known.
So, after determining the number of characters in each component, the next heuristic occurs - we consider that the delimiters between characters are thinner than the characters themselves. In order to take advantage of this intimate knowledge, we place on the segment n-1 separators, where n is the number of characters in the segment, then in a small neighborhood of each separator we calculate the image downwards. As a result of this projection, we will get information about how many pixels in each column belong to the characters. Finally, in each projection we find the minimum and move the separator there, after which we cut the image along these separators.




Finally, recognition. As I said, for him I use the neural network. For her training, I first run two hundred images under the general trainset heading through the first two stages already written and debugged, with the result that I get a folder with a large number of neatly cut segments. Then I clean the garbage with my hands (the results of incorrect segmentation, for example), after which I bring the result to the same size and give it to FANN to be torn apart. At the output, I get a trained neural network, which is used for recognition. This scheme failed only once - but more on that later.
As a result, the test set (not used for training, the code name - testset ) of 100 images was correctly recognized 45. Not a very good result - it can, of course, be improved, for example, by specifying the preprocess or modifying the recognition, but, frankly, I It was too lazy to bother with it.
In addition, I used another criterion for evaluating the performance of the algorithm — the average error. It was calculated as follows. For each image there was a Levenshtein distance between the opinion of the algorithm on this image and the correct answer - after which the arithmetic average was taken over all the images. For this type of CAPTCHA, the average error was 0.75 characters / image. It seems to me that this is a more accurate criterion than just the percentage of recognition.
By the way, almost everywhere (except for the yellow operator) I used exactly such a scheme - 200 pictures in a trainset, 100 - in a testset.
I chose the next goal of greens - I wanted to take on something more serious than the selection of the distortion matrix.

Advantages:
Disadvantages:
It turned out that even in spite of the fact that these flaws are seemingly insignificant, their exploitation makes it possible to effectively deal with all the advantages.
Again, let's start with preprocessing. First, we estimate the angle of rotation of the rectangle on which the characters lie. To do this, apply the Erode operator (local minimum search) to the source image, then the Threshold to select the residuals of the rectangle and, finally, the inversion. Get a nice white spot on a black background.
Next comes a deep thought. The first. To estimate the angle of rotation of the entire rectangle, it is sufficient to estimate the angle of rotation of its upper side. The second. It is possible to estimate the angle of rotation of the upper side by searching for a line parallel to this side. Third. To describe any straight line, except strictly vertical, two parameters are enough - vertical displacement from the center of coordinates and angle of inclination, and we are only interested in the second one. Fourth. The task of searching for a straight line can be solved not by a very large search - there are no too big turning angles there, and we don’t need ultra-high accuracy. The fifth. To search for the necessary line, you can compare each direct estimate of how close it is to what you are looking for, and then choose the maximum. The sixth. The most important. To estimate a certain angle of inclination of a straight line, let us imagine that the image from above is tangent to a straight line with such an inclination angle. It is clear that from the dimensions of the image and the angle of inclination, it is possible to uniquely calculate the vertical offset of the line, so that it is uniquely defined. Further, we will gradually move this line down. At some point, it will touch the white spot. Let us remember this moment and the area of intersection of the line with the spot. Let me remind you that the straight line has an 8-connected view on the plane, so angry cries from the audience that the straight line has one dimension, and the area is a two-dimensional concept, is irrelevant here. Then for some time we will move this line downward, at each step remembering the intersection area, after which we will summarize the results obtained. This amount will be an estimate of this angle of rotation.


Summarizing the above, we will look for such a straight line that when moving it down the image, the brightness of the pixels lying on this straight line increases most dramatically.
So, the angle of rotation is found. But we should not rush to immediately apply the knowledge obtained. The fact is that this will destroy the image connectivity, but we still need it.
The next step is to separate the characters from the background. Here we are greatly helped by the fact that the characters are much darker than the background. It is a logical step by the developers - otherwise it would be very difficult to read the picture. Who does not believe - can try to independently binarize the image and see for yourself.
However, the approach "in the forehead" - an attempt to cut off characters with a threshold transformation - does not work here. The best result that I managed to achieve - at t = 140 - looks very bad. Too much trash remains. Therefore it was necessary to apply a workaround. The idea here is as follows. Symbols are usually connected. And they often own the darkest points on the image. And what if you try to apply a fill from these darkest points, and then throw out too small areas filled in - obvious rubbish?
The result is, frankly, amazing. Most of the images manage to get rid of the background completely. However, it happens that a symbol breaks into several parts - in this case, one crutch can help in segmentation - but more on that later.

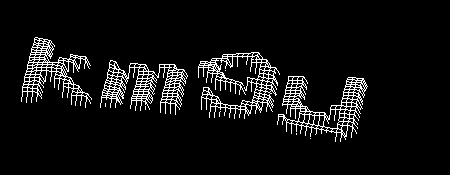
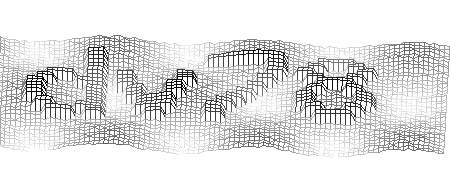
Next, we make a turn to the angle found earlier.


Finally, the combination of the Dilate and Erode operators relieves us of the small holes left in the characters, which helps to simplify recognition.


Segmentation here is much simpler than preprocess. First of all, we look for connected components.


Then we combine the components that are horizontally close (the procedure is exactly the same as before):


Actually, everything. This is followed by recognition, but it is no different from the above.
This algorithm allowed achieving results in 69% of successfully recognized images and obtaining an average error of 0.3 characters / image.
So, the third status "defeated" received a blue operator. It was, so to speak, a respite before a really big fish ...



It is difficult to write something in dignity, but I still try:
In contrast to this:
So, preprocess. Let's start with the background clipping. Since the image is tricolor, we will cut it into channels, and then we will throw away all the points that are brighter than 116 across all channels. We will get just such a pretty mask:



Then convert the image to the HSV color space ( Wikipedia ). This will save information about the color of characters, and at the same time remove the gradient from their edges.



Apply the mask obtained earlier to the result:



At this preprocess ends. Segmentation is also quite trivial. We begin, as always, with connected components:




It would be possible to stop there, but only 73% come out this way, which doesn’t suit me at all - only 4% better than the result of the obviously more complex CAPTCHA. So, the next step is to reverse the rotation of characters. Here we can use the already mentioned fact that local characters fit well into a rectangle. The idea is to find a descriptive rectangle for each character, and then, by its slope, calculate the slope of the actual character. Here, the describing rectangle is understood as such that, firstly, it contains all the pixels of a given symbol, and, secondly, it has the smallest area of all possible. I use a ready-made implementation of the search algorithm for such a rectangle from OpenCV ( MinAreaRect2 ).

Further, as always, follows recognition.
This algorithm successfully recognizes 86% of images with an average error of 0.16 characters / image, which confirms the assumption that this CAPTCHA is indeed the simplest. However, the operator is not the largest ...
The most interesting comes. So to say, the apotheosis of my creative activity :) This CAPTCHA is really the most difficult for both the computer and, unfortunately, for a person.



Advantages:
Disadvantages:
Over the first step, I thought for a long time. The first thing that came to mind was to play around with local maxima (Dilate) to remove small noise. However, this approach led to the fact that there was not much left of the letters - only ragged outlines. The problem was aggravated by the fact that the texture of the characters themselves is not uniform - this is clearly visible at high magnification. To get rid of it, I decided to choose the most stupid way - I opened Paint and wrote down the codes of all the colors found in the images. It turned out that all in these images there are four different textures, and the three of them have 4 different colors, and the last - 3; moreover, all the components of these colors turned out to be multiples of 51. Next, I compiled a table of colors with which I managed to get rid of the texture. However, before this “REMAP”, I’m also overwriting all too light pixels, which are usually located on the edges of characters - otherwise you have to mark them as noise, and then deal with them, while they contain little information.
So, after this transformation, the image contains no more than 6 colors - 4 colors of symbols (we will conventionally call them gray, blue, light green and dark green), white (background color) and “unknown”, denoting that the pixel color is its place could not be identified with any of the known colors. Call conditionally - because at this point I’ll get rid of the three channels and turn to the usual and convenient monochrome image.



The next step was to clear the image from the lines. Here, the situation is saved by the fact that these lines are very thin - only 1 pixel.A simple filter suggests itself: go over the entire image, comparing the color of each pixel with the colors of its neighbors (in pairs - vertically and horizontally); if the neighbors match in color, and do not match the color of the pixel itself, make it the same as the neighbors. I use a slightly more sophisticated version of the same filter that works in two stages. At first, he evaluates his neighbors at a distance of 2, at the second, at a distance of 1. This allows one to achieve this effect:

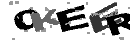

Then I get rid of most of the spots, as well as the “unknown” color. To do this, I first look for all the small connected areas (smaller than 15 in area, to be exact), put them on a black and white mask, and then combine the result with the areas occupied by the “unknown” color.


With the help of these masks, I set the image on the imageInpaint (or rather, its implementation in OpenCV). This allows you to very effectively clean up most of the garbage from the image.



However, the implementation of this algorithm in OpenCV was created to work with photos and videos, rather than recognizing artificially created images with noisy text. After its application, gradients appear, which I would like to avoid in order to simplify the segmentation. Thus, it is necessary to make additional processing, namely - sharpening. For the color of each pixel, I calculate the one closest to it from the above table (remember, there are 5 colors - one for each of the textures of characters and white).



Finally, the final step in the preprocess will be the removal of all remaining small connected areas. They appear after applying Inpaint, so there is no repetition here.



We proceed to segmentation. It greatly complicates the fact that the characters are very close to each other. It may happen that one symbol does not show half of the other. It becomes quite bad when these symbols are of the same color. In addition, the remains of garbage also play a role - it may happen that in the original image the lines intersect in a large number in one place. In this case, the algorithm that I described earlier will not be able to get rid of them.
After a week spent in fruitless attempts to write a segmentation in the same way as in the previous cases, I scored on this case and changed tactics. My new strategy was to divide the entire segmentation process into two parts. The first one estimates the angle of rotation of the characters and performs the reverse rotation. In the second of the already expanded images, the characters are re-highlighted. So let's get started.We begin, as always, with a search for connected components.



Then you need to estimate the angle of rotation of each character. When working with the Greenpeace fan-operator, I came up with an algorithm for this, but wrote and applied it only here. In order to illustrate his work, I will draw an analogy. Imagine a piston that moves on a black and white image of a symbol from bottom to top. The piston handle, for which it is pushed, is located vertically, the working platform, which it pushes - horizontally, parallel to the bottom of the image and perpendicular to the handle. The handle is attached to the platform in the middle, and at the point of attachment there is a movable joint, as a result of which the platform can be rotated. Forgive me terminology specialists.
Let the handle move upwards, pushing the platform in front of you according to the laws of physics. We assume that only the white image of the symbol is material, and the piston easily passes through the black background. Then the piston, having reached the white color, will begin to interact with it, namely, to turn - provided that the force is still applied to the handle. He can stop in two cases: if he has rested against a symbol on both sides of the point of application of force, or if he has rested against a symbol as the very point of application of force. In all other cases, he will be able to continue driving. Attention, culmination: we will assume that the angle of rotation of the symbol is the angle of inclination of the piston at the moment when it stopped.

This algorithm is fairly accurate, but I do not take into account the obviously great results (more than 27 degrees). Of the remaining ones, I find the arithmetic average, after which the whole image is turned to a minus this angle. Then I search for connected components again.


Further it becomes more and more interesting. In the previous examples, I started various frauds with the received segments, and then transferred them to the neural network. Everything is different here. First, in order to at least partially restore the information lost after dividing the image into connectivity components, I draw a “background” on each of them in dark gray color (96) - what was next to the cut segment, but did not fall into it , after which I smooth the outlines of the characters using the same procedure as in the preprocess for the lines (with the distance to the neighbor equal to one).
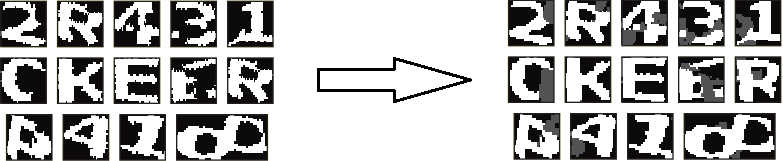
Formally (in terms of program modules), segmentation ends here. The attentive reader must have noticed that the separation of stuck characters was not mentioned anywhere. Yes, this is so - I pass them on to recognition in exactly this form, and I finish it in place.
The reason is that the method of splitting together stuck characters, which was described earlier (with the smallest projection) does not work here - the authors have chosen the font very well. Therefore it is necessary to apply a different, more complex approach. At the core of this approach is the idea that a neural network can be used for segmentation.
At the very beginning, I described an algorithm that allows us to find the number of characters in a segment with a known width of this segment and the total number of characters. The same algorithm is used here. For each segment, the number of characters in it is calculated. If he is alone there, you do not need to finish anything, and this segment immediately goes>> = to the neural network. If the symbol is not one there, then potential separators are placed along the segment at equal distances. Then each separator moves in its own small neighborhood, and the neural network response to the characters around this separator is calculated at the same time, after which it remains only to choose the maximum (in fact, it all does a rather stupid algorithm, but, in principle, everything is really approximately).
Naturally, participation of a neural network in the process of segmentation (or pre-segmentation, if you like) excludes the possibility of using the neural network training scheme that I have already described. More specifically, it does not allow to get the very first neural network - it can be used to train others. Therefore, I act quite simply - I use conventional segmentation methods (projection) to train a neural network, while using it, the above described algorithm comes into play.
There is one more subtlety associated with the use of a neural network in this algorithm. In the previous examples, the neural network was trained on the almost raw results of preprocess and segmentation. Here it allowed to get no more than 12% of successful recognition. It categorically did not suit me. Therefore, before starting the next epoch of neural network training, I introduced various distortions into the source images that roughly simulate real ones: add white / gray / black dots, gray lines / circles / rectangles, rotate. I also increased the trainset from 200 images to 300 and added a so-called validsetto test the quality of training during training on 100 images. This made it possible to achieve an increase in productivity somewhere by five percent, and together with the segmentation of the neural network, it gave the result I mentioned at the beginning of the article.
Providing statistics is complicated by the fact that I ended up with two neural networks: one gave a higher recognition percentage, and the other a smaller error. Here I give the results of the first.
In total, as I have said repeatedly, there were 100 images in the testset. Of these, 20 were successfully recognized, unsuccessfully, respectively, 80, and the error was 1.91 characters per image. Noticeably worse than all other operators, but the corresponding CAPTCHA.
Everything that relates to this work, I posted in a special forum thread on my site, in particular: the source code , neural network files and images.
Next year, I would like to participate in something - at least in the same Baltic competition (and after it, preferably in Intel ISEF ), but the creative crisis makes itself felt - it’s impossible to think up a sane topic for the project, but continue There is no desire to mess with captcha. Perhaps the habrasoobschestvo can help me ...
The ideas that I had, but none of which I do not like - these functional operating systems and distributed (and / or anonymous) networks. Unfortunately, the first will probably be too difficult for me (and who needs them, these functional axes? ), And the second has already been done and done well ( I2P , Netsukuku ). At the same time, I want something that, firstly, it is possible to do in a year (at least two), and secondly, I would seriously claim a high place on the same ISEF. Maybe you can tell in which direction I should move?
UPD 2015-04-09: the repository on Github .
The job was to recognize the CAPTCHA used by large mobile operators in the form of sending SMS, and to demonstrate the lack of effectiveness of their approach. In order not to hurt anyone's pride, we will call these operators allegorically: red, yellow, green and blue.
')
The project received the official name Captchure and unofficial Breaking Defective Security Measures . Any matches are random.
Oddly enough, all (well, almost all) of these CAPTCHAs turned out to be rather weak. The lowest result - 20% - belongs to the yellow operator, the greatest - 86% - to the blue. Thus, I believe that the task of “demonstrating inefficiency” was successfully solved.
The reasons for choosing cellular operators are trivial. To the respected Scientific Jury, I told the bike that “cellular operators have enough money to hire a programmer of any qualification, and, at the same time, they need to minimize the amount of spam; thus, their CAPTCHA must be quite powerful, which, as my research shows, is completely different. ” In fact, everything was much simpler. I wanted to gain experience by
So, closer to the body. I don’t have any mega-advanced algorithm for recognizing all four types of CAPTCHA; instead, I wrote 4 different algorithms for each type of CAPTCHA separately. However, despite the fact that the algorithms are different in details, in general, they turned out to be very similar.
Like many authors before me, I split the CAPTCHA recognition task into 3 subtasks: preprocessing (preprocess), segmentation, and recognition. At the preprocess stage, various noises, distortions, etc. are removed from the original image. In the segmentation, separate characters are extracted from the original image and produced from post-processing (for example, reverse rotation). In recognition, the characters are processed one by one by the previously trained neural network.
Only the preprocess was significantly different. This is due to the fact that different methods of image distortion are used in different CAPTCHA, respectively, and the algorithms for removing these distortions are very different. Segmentation exploited the key idea of finding connectivity components with minor frills (they had to be significant only for yellow-
The code is written in Python using the OpenCV and FANN libraries, which are not installed without a decent-sized file and a tambourine into the bargain. Therefore, my results will not be easy to reproduce - at least until the authors of the above libraries make normal Python bindings.
Red
As I said, I chose this particular CAPTCHA as the first rabbit. I think a few examples will clarify the situation:
That's it, and at first I also thought that it was very simple ... However, this impression did not come from scratch. So:
- The colors are exhausted by grayscale, and the symbols are light, the background is dark.
- No extra noise
- Constant distortion (i.e. not changing from picture to picture)
- There are always exactly five characters.
- Character sizes are about the same.
- Characters are almost always connected.
It all seemed to negate the merits of this CAPTCHA:
- Sticking letters
- Nasty holey font
- Very small size (83x23 px)
Naturally, these "advantages" are such only from the point of view of the complexity of automatic recognition. In accordance with the three-stage scheme, mentioned by me earlier, we start with the preliminary image processing, namely, a 2-fold increase.
As I already mentioned, the distortions are constant here, and, even though they are not linear, it is not difficult to get rid of them. The parameters were chosen empirically.
Next, I apply a threshold conversion (popularly Threshold) with t = 200 and invert the image:
Finally, small (less than 10px) black connected regions are painted over with white:
This is followed by segmentation. As I said, the search for connected components is applied here:
Sometimes (rarely, but sometimes) a letter breaks into several parts; To correct this annoying misunderstanding, I use a fairly simple heuristic that evaluates the belonging of several connected components to a single symbol. This estimate depends only on the horizontal position and size of the descriptive rectangles (bounding boxes) of each character.
It is easy to see that many characters were combined into one component of connectivity, and therefore it is necessary to separate them. Here comes the fact that the image is always exactly 5 characters. This allows you to accurately calculate how many characters are in each component found.
To explain the principle of operation of such an algorithm, you will have to delve a little into the materiel. Denote the number of segments found by n, and the array of widths ( correctly said, yes? ) Of all segments by widths [n]. We assume that if after the above steps n> 5, the image could not be recognized. Consider all possible expansions of the number 5 into positive integer terms. There are only a few of them - only 16. Each such decomposition corresponds to some possible arrangement of symbols for the connected components found. It is logical to assume that the wider the resulting segment, the more characters it contains. Of all the expansions of the five, we choose only those in which the number of terms is equal to n. We divide each element from widths by widths [0] - as if we normalize them. We do the same with all the remaining expansions - we divide each number in them into the first term. And now (attention, climax!), We note that the resulting ordered n-ki can be thought of as points in n-dimensional space. With this in mind, we find the closest to Euclid decomposition of the five to normalized widths. This is the desired result.
By the way, in connection with this algorithm, another interesting way came to my mind to search for all decompositions of a number into terms, which I, however, did not implement, having dug in Python data structures. In short - it comes out pretty obviously, if you notice that the number of expansions of a certain length coincides with the corresponding level of Pascal's triangle. However, I am sure that this algorithm has long been known.
So, after determining the number of characters in each component, the next heuristic occurs - we consider that the delimiters between characters are thinner than the characters themselves. In order to take advantage of this intimate knowledge, we place on the segment n-1 separators, where n is the number of characters in the segment, then in a small neighborhood of each separator we calculate the image downwards. As a result of this projection, we will get information about how many pixels in each column belong to the characters. Finally, in each projection we find the minimum and move the separator there, after which we cut the image along these separators.
Finally, recognition. As I said, for him I use the neural network. For her training, I first run two hundred images under the general trainset heading through the first two stages already written and debugged, with the result that I get a folder with a large number of neatly cut segments. Then I clean the garbage with my hands (the results of incorrect segmentation, for example), after which I bring the result to the same size and give it to FANN to be torn apart. At the output, I get a trained neural network, which is used for recognition. This scheme failed only once - but more on that later.
As a result, the test set (not used for training, the code name - testset ) of 100 images was correctly recognized 45. Not a very good result - it can, of course, be improved, for example, by specifying the preprocess or modifying the recognition, but, frankly, I It was too lazy to bother with it.
In addition, I used another criterion for evaluating the performance of the algorithm — the average error. It was calculated as follows. For each image there was a Levenshtein distance between the opinion of the algorithm on this image and the correct answer - after which the arithmetic average was taken over all the images. For this type of CAPTCHA, the average error was 0.75 characters / image. It seems to me that this is a more accurate criterion than just the percentage of recognition.
By the way, almost everywhere (except for the yellow operator) I used exactly such a scheme - 200 pictures in a trainset, 100 - in a testset.
Green
I chose the next goal of greens - I wanted to take on something more serious than the selection of the distortion matrix.
Advantages:
- Three-dimensional effect
- Rotate and shift
- Uneven brightness
Disadvantages:
- Characters are noticeably darker than background.
- The upper side of the rectangle can be clearly seen - can be used for reverse rotation
It turned out that even in spite of the fact that these flaws are seemingly insignificant, their exploitation makes it possible to effectively deal with all the advantages.
Again, let's start with preprocessing. First, we estimate the angle of rotation of the rectangle on which the characters lie. To do this, apply the Erode operator (local minimum search) to the source image, then the Threshold to select the residuals of the rectangle and, finally, the inversion. Get a nice white spot on a black background.
Next comes a deep thought. The first. To estimate the angle of rotation of the entire rectangle, it is sufficient to estimate the angle of rotation of its upper side. The second. It is possible to estimate the angle of rotation of the upper side by searching for a line parallel to this side. Third. To describe any straight line, except strictly vertical, two parameters are enough - vertical displacement from the center of coordinates and angle of inclination, and we are only interested in the second one. Fourth. The task of searching for a straight line can be solved not by a very large search - there are no too big turning angles there, and we don’t need ultra-high accuracy. The fifth. To search for the necessary line, you can compare each direct estimate of how close it is to what you are looking for, and then choose the maximum. The sixth. The most important. To estimate a certain angle of inclination of a straight line, let us imagine that the image from above is tangent to a straight line with such an inclination angle. It is clear that from the dimensions of the image and the angle of inclination, it is possible to uniquely calculate the vertical offset of the line, so that it is uniquely defined. Further, we will gradually move this line down. At some point, it will touch the white spot. Let us remember this moment and the area of intersection of the line with the spot. Let me remind you that the straight line has an 8-connected view on the plane, so angry cries from the audience that the straight line has one dimension, and the area is a two-dimensional concept, is irrelevant here. Then for some time we will move this line downward, at each step remembering the intersection area, after which we will summarize the results obtained. This amount will be an estimate of this angle of rotation.
Summarizing the above, we will look for such a straight line that when moving it down the image, the brightness of the pixels lying on this straight line increases most dramatically.
So, the angle of rotation is found. But we should not rush to immediately apply the knowledge obtained. The fact is that this will destroy the image connectivity, but we still need it.
The next step is to separate the characters from the background. Here we are greatly helped by the fact that the characters are much darker than the background. It is a logical step by the developers - otherwise it would be very difficult to read the picture. Who does not believe - can try to independently binarize the image and see for yourself.
However, the approach "in the forehead" - an attempt to cut off characters with a threshold transformation - does not work here. The best result that I managed to achieve - at t = 140 - looks very bad. Too much trash remains. Therefore it was necessary to apply a workaround. The idea here is as follows. Symbols are usually connected. And they often own the darkest points on the image. And what if you try to apply a fill from these darkest points, and then throw out too small areas filled in - obvious rubbish?
The result is, frankly, amazing. Most of the images manage to get rid of the background completely. However, it happens that a symbol breaks into several parts - in this case, one crutch can help in segmentation - but more on that later.
Next, we make a turn to the angle found earlier.
Finally, the combination of the Dilate and Erode operators relieves us of the small holes left in the characters, which helps to simplify recognition.
Segmentation here is much simpler than preprocess. First of all, we look for connected components.
Then we combine the components that are horizontally close (the procedure is exactly the same as before):
Actually, everything. This is followed by recognition, but it is no different from the above.
This algorithm allowed achieving results in 69% of successfully recognized images and obtaining an average error of 0.3 characters / image.
Blue
So, the third status "defeated" received a blue operator. It was, so to speak, a respite before a really big fish ...
It is difficult to write something in dignity, but I still try:
- Rotate characters - the only more or less serious obstacle
- Background noise in the form of characters
- Characters sometimes touch each other
In contrast to this:
- Background significantly lighter than characters
- The characters fit well into the rectangle.
- Different color symbols make it easy to separate them from each other.
So, preprocess. Let's start with the background clipping. Since the image is tricolor, we will cut it into channels, and then we will throw away all the points that are brighter than 116 across all channels. We will get just such a pretty mask:
Then convert the image to the HSV color space ( Wikipedia ). This will save information about the color of characters, and at the same time remove the gradient from their edges.
Apply the mask obtained earlier to the result:
At this preprocess ends. Segmentation is also quite trivial. We begin, as always, with connected components:
It would be possible to stop there, but only 73% come out this way, which doesn’t suit me at all - only 4% better than the result of the obviously more complex CAPTCHA. So, the next step is to reverse the rotation of characters. Here we can use the already mentioned fact that local characters fit well into a rectangle. The idea is to find a descriptive rectangle for each character, and then, by its slope, calculate the slope of the actual character. Here, the describing rectangle is understood as such that, firstly, it contains all the pixels of a given symbol, and, secondly, it has the smallest area of all possible. I use a ready-made implementation of the search algorithm for such a rectangle from OpenCV ( MinAreaRect2 ).
Further, as always, follows recognition.
This algorithm successfully recognizes 86% of images with an average error of 0.16 characters / image, which confirms the assumption that this CAPTCHA is indeed the simplest. However, the operator is not the largest ...
Yellow
The most interesting comes. So to say, the apotheosis of my creative activity :) This CAPTCHA is really the most difficult for both the computer and, unfortunately, for a person.
Advantages:
- Noise in the form of spots and lines
- Rotate and scale characters
- Close proximity of characters
Disadvantages:
- Very limited palette
- All lines are very thin.
- Spots often do not intersect with characters
- The rotation angle of all characters is approximately the same.
Over the first step, I thought for a long time. The first thing that came to mind was to play around with local maxima (Dilate) to remove small noise. However, this approach led to the fact that there was not much left of the letters - only ragged outlines. The problem was aggravated by the fact that the texture of the characters themselves is not uniform - this is clearly visible at high magnification. To get rid of it, I decided to choose the most stupid way - I opened Paint and wrote down the codes of all the colors found in the images. It turned out that all in these images there are four different textures, and the three of them have 4 different colors, and the last - 3; moreover, all the components of these colors turned out to be multiples of 51. Next, I compiled a table of colors with which I managed to get rid of the texture. However, before this “REMAP”, I’m also overwriting all too light pixels, which are usually located on the edges of characters - otherwise you have to mark them as noise, and then deal with them, while they contain little information.
So, after this transformation, the image contains no more than 6 colors - 4 colors of symbols (we will conventionally call them gray, blue, light green and dark green), white (background color) and “unknown”, denoting that the pixel color is its place could not be identified with any of the known colors. Call conditionally - because at this point I’ll get rid of the three channels and turn to the usual and convenient monochrome image.
The next step was to clear the image from the lines. Here, the situation is saved by the fact that these lines are very thin - only 1 pixel.A simple filter suggests itself: go over the entire image, comparing the color of each pixel with the colors of its neighbors (in pairs - vertically and horizontally); if the neighbors match in color, and do not match the color of the pixel itself, make it the same as the neighbors. I use a slightly more sophisticated version of the same filter that works in two stages. At first, he evaluates his neighbors at a distance of 2, at the second, at a distance of 1. This allows one to achieve this effect:
Then I get rid of most of the spots, as well as the “unknown” color. To do this, I first look for all the small connected areas (smaller than 15 in area, to be exact), put them on a black and white mask, and then combine the result with the areas occupied by the “unknown” color.
With the help of these masks, I set the image on the imageInpaint (or rather, its implementation in OpenCV). This allows you to very effectively clean up most of the garbage from the image.
However, the implementation of this algorithm in OpenCV was created to work with photos and videos, rather than recognizing artificially created images with noisy text. After its application, gradients appear, which I would like to avoid in order to simplify the segmentation. Thus, it is necessary to make additional processing, namely - sharpening. For the color of each pixel, I calculate the one closest to it from the above table (remember, there are 5 colors - one for each of the textures of characters and white).
Finally, the final step in the preprocess will be the removal of all remaining small connected areas. They appear after applying Inpaint, so there is no repetition here.
We proceed to segmentation. It greatly complicates the fact that the characters are very close to each other. It may happen that one symbol does not show half of the other. It becomes quite bad when these symbols are of the same color. In addition, the remains of garbage also play a role - it may happen that in the original image the lines intersect in a large number in one place. In this case, the algorithm that I described earlier will not be able to get rid of them.
After a week spent in fruitless attempts to write a segmentation in the same way as in the previous cases, I scored on this case and changed tactics. My new strategy was to divide the entire segmentation process into two parts. The first one estimates the angle of rotation of the characters and performs the reverse rotation. In the second of the already expanded images, the characters are re-highlighted. So let's get started.We begin, as always, with a search for connected components.
Then you need to estimate the angle of rotation of each character. When working with the Greenpeace fan-operator, I came up with an algorithm for this, but wrote and applied it only here. In order to illustrate his work, I will draw an analogy. Imagine a piston that moves on a black and white image of a symbol from bottom to top. The piston handle, for which it is pushed, is located vertically, the working platform, which it pushes - horizontally, parallel to the bottom of the image and perpendicular to the handle. The handle is attached to the platform in the middle, and at the point of attachment there is a movable joint, as a result of which the platform can be rotated. Forgive me terminology specialists.
Let the handle move upwards, pushing the platform in front of you according to the laws of physics. We assume that only the white image of the symbol is material, and the piston easily passes through the black background. Then the piston, having reached the white color, will begin to interact with it, namely, to turn - provided that the force is still applied to the handle. He can stop in two cases: if he has rested against a symbol on both sides of the point of application of force, or if he has rested against a symbol as the very point of application of force. In all other cases, he will be able to continue driving. Attention, culmination: we will assume that the angle of rotation of the symbol is the angle of inclination of the piston at the moment when it stopped.
This algorithm is fairly accurate, but I do not take into account the obviously great results (more than 27 degrees). Of the remaining ones, I find the arithmetic average, after which the whole image is turned to a minus this angle. Then I search for connected components again.
Further it becomes more and more interesting. In the previous examples, I started various frauds with the received segments, and then transferred them to the neural network. Everything is different here. First, in order to at least partially restore the information lost after dividing the image into connectivity components, I draw a “background” on each of them in dark gray color (96) - what was next to the cut segment, but did not fall into it , after which I smooth the outlines of the characters using the same procedure as in the preprocess for the lines (with the distance to the neighbor equal to one).
Formally (in terms of program modules), segmentation ends here. The attentive reader must have noticed that the separation of stuck characters was not mentioned anywhere. Yes, this is so - I pass them on to recognition in exactly this form, and I finish it in place.
The reason is that the method of splitting together stuck characters, which was described earlier (with the smallest projection) does not work here - the authors have chosen the font very well. Therefore it is necessary to apply a different, more complex approach. At the core of this approach is the idea that a neural network can be used for segmentation.
At the very beginning, I described an algorithm that allows us to find the number of characters in a segment with a known width of this segment and the total number of characters. The same algorithm is used here. For each segment, the number of characters in it is calculated. If he is alone there, you do not need to finish anything, and this segment immediately goes
Naturally, participation of a neural network in the process of segmentation (or pre-segmentation, if you like) excludes the possibility of using the neural network training scheme that I have already described. More specifically, it does not allow to get the very first neural network - it can be used to train others. Therefore, I act quite simply - I use conventional segmentation methods (projection) to train a neural network, while using it, the above described algorithm comes into play.
There is one more subtlety associated with the use of a neural network in this algorithm. In the previous examples, the neural network was trained on the almost raw results of preprocess and segmentation. Here it allowed to get no more than 12% of successful recognition. It categorically did not suit me. Therefore, before starting the next epoch of neural network training, I introduced various distortions into the source images that roughly simulate real ones: add white / gray / black dots, gray lines / circles / rectangles, rotate. I also increased the trainset from 200 images to 300 and added a so-called validsetto test the quality of training during training on 100 images. This made it possible to achieve an increase in productivity somewhere by five percent, and together with the segmentation of the neural network, it gave the result I mentioned at the beginning of the article.
Providing statistics is complicated by the fact that I ended up with two neural networks: one gave a higher recognition percentage, and the other a smaller error. Here I give the results of the first.
In total, as I have said repeatedly, there were 100 images in the testset. Of these, 20 were successfully recognized, unsuccessfully, respectively, 80, and the error was 1.91 characters per image. Noticeably worse than all other operators, but the corresponding CAPTCHA.
Instead of conclusion
Everything that relates to this work, I posted in a special forum thread on my site, in particular: the source code , neural network files and images.
Next year, I would like to participate in something - at least in the same Baltic competition (and after it, preferably in Intel ISEF ), but the creative crisis makes itself felt - it’s impossible to think up a sane topic for the project, but continue There is no desire to mess with captcha. Perhaps the habrasoobschestvo can help me ...
The ideas that I had, but none of which I do not like - these functional operating systems and distributed (and / or anonymous) networks. Unfortunately, the first will probably be too difficult for me (and who needs them, these functional axes? ), And the second has already been done and done well ( I2P , Netsukuku ). At the same time, I want something that, firstly, it is possible to do in a year (at least two), and secondly, I would seriously claim a high place on the same ISEF. Maybe you can tell in which direction I should move?
UPD 2015-04-09: the repository on Github .
Source: https://habr.com/ru/post/116222/
All Articles